Автор: Денис Аветисян
Новый механизм разреженного внимания позволяет значительно повысить эффективность обработки длинных последовательностей в моделях, генерирующих изображения.

Представлен Log-linear Sparse Attention (LLSA) — подход, снижающий вычислительную сложность самовнимания в Diffusion Transformers для обучения моделей высокого разрешения.
Несмотря на впечатляющие результаты Diffusion Transformers (DiT) в генерации изображений, квадратичная сложность механизма самовнимания существенно ограничивает их масштабируемость для обработки длинных последовательностей. В данной работе, посвященной разработке ‘Trainable Log-linear Sparse Attention for Efficient Diffusion Transformers’, предложен новый механизм разреженного внимания (LLSA), снижающий вычислительную сложность до логарифмической за счет иерархической структуры. LLSA позволяет эффективно обучать DiT для генерации изображений высокого разрешения в пиксельном пространстве, ускоряя процесс в 6.09 раз, при этом сохраняя качество генерируемых изображений. Возможно ли дальнейшее снижение вычислительных затрат и расширение возможностей DiT за счет оптимизации архитектуры LLSA и использования новых методов обучения?
Масштабируемость Диффузионных Трансформеров: Ключевое Ограничение
Диффузионные трансформеры стремительно зарекомендовали себя как передовые модели в области генерации изображений, демонстрируя впечатляющие результаты в различных задачах. Эти модели превосходят существующие подходы в создании детализированных и реалистичных изображений, охватывая широкий спектр приложений — от фотореалистичной визуализации до художественного творчества. Их способность к улавливанию сложных закономерностей в данных и генерации новых образцов, соответствующих этим закономерностям, открывает новые горизонты в компьютерном зрении и искусственном интеллекте. Успехи диффузионных трансформеров наблюдаются в задачах повышения разрешения изображений, восстановления поврежденных изображений и даже в создании совершенно новых визуальных концепций, что делает их ключевым инструментом для исследователей и разработчиков в области генеративных моделей.
Диффузионные трансформаторы, демонстрирующие передовые результаты в генерации изображений, сталкиваются с существенным ограничением, обусловленным использованием механизма полного самовнимания. Данный подход требует сравнения каждого элемента последовательности со всеми остальными, что приводит к квадратичной сложности $O(N^2)$ при увеличении размера входных данных. Подобная вычислительная нагрузка становится критичной при обработке изображений высокого разрешения, где количество пикселей, составляющих последовательность, значительно возрастает. Вследствие этого, применение стандартного механизма самовнимания становится непрактичным и ограничивает возможность масштабирования моделей для генерации детализированных и реалистичных изображений.
Квадратичная сложность, являющаяся препятствием для масштабирования диффузионных трансформеров, обусловлена необходимостью сопоставления каждого пикселя изображения со всеми остальными. В процессе вычисления внимания каждый пиксель должен быть сравнен с каждым другим, что приводит к росту вычислительных затрат пропорционально квадрату количества пикселей $O(N^2)$. При работе с изображениями высокого разрешения, содержащими миллионы пикселей, этот процесс становится крайне ресурсоемким и замедляет генерацию. По сути, чем длиннее последовательность (в данном случае, последовательность пикселей, представляющих изображение), тем сильнее проявляется этот «узкий участок», ограничивая возможность обработки изображений больших размеров и требуя разработки более эффективных механизмов внимания.
Разреженное Внимание: Путь к Эффективности
Механизм разреженного внимания (Sparse Attention) представляет собой альтернативный подход к стандартному вниманию, направленный на снижение вычислительной сложности. Вместо вычисления внимания между каждым токеном последовательности, разреженное внимание фокусируется на наиболее релевантных токенах, отбрасывая менее значимые связи. Это достигается путем ограничения количества токенов, участвующих в вычислении внимания, что приводит к снижению требуемой памяти и времени вычислений. Сложность стандартного механизма внимания составляет $O(n^2)$, где $n$ — длина последовательности, в то время как разреженное внимание может снизить эту сложность до $O(n \cdot \sqrt{n})$ или даже $O(n \log n)$ в зависимости от конкретной реализации и выбранной стратегии разрежения.
Методы разреженного внимания, такие как VSA (Vector Sparse Attention) и SLA (Sparse Local Attention), расширяют базовую концепцию, предлагая дополнительные механизмы для повышения эффективности. VSA использует сжатие векторов внимания для уменьшения объема вычислений, фокусируясь на наиболее информативных частях входной последовательности. SLA, в свою очередь, применяет селективное внимание, ограничивая область рассмотрения только локальными участками последовательности, что снижает вычислительную сложность и потребление памяти. Оба подхода направлены на оптимизацию использования ресурсов при обработке длинных последовательностей, сохраняя при этом качество модели.
Блочная разреженная внимательность Top-K совершенствует подход, сжимая и отбирая ключевые блоки на основе их значимости. Данный метод позволяет снизить вычислительную сложность за счет фокусировки на наиболее важных участках входной последовательности. Вместо вычисления внимания для каждой пары токенов, Top-K блочная разреженная внимательность вычисляет внимание только для ограниченного числа блоков, отобранных по критерию важности, что приводит к снижению вычислительных затрат и требований к памяти. Эффективность достигается путем применения $k$-выборки наиболее значимых блоков, где $k$ — гиперпараметр, определяющий степень разреженности и баланс между точностью и скоростью вычислений.
Pixel DiT: Новая Архитектура для Эффективной Генерации Изображений
Архитектура Pixel DiT представляет собой диффузионный трансформатор, работающий непосредственно с пиксельными данными. В отличие от традиционных подходов, использующих патчификацию или кодирование с помощью вариационных автоэнкодеров (VAE), Pixel DiT обрабатывает изображения на уровне отдельных пикселей. Это позволяет избежать потерь информации, связанных с процессами дискретизации и реконструкции, что, в свою очередь, способствует повышению точности и детализации генерируемых изображений. Непосредственная обработка пиксельных данных также упрощает архитектуру модели, устраняя необходимость в дополнительных компонентах, связанных с обработкой патчей или латентного пространства VAE.
Для оптимизации производительности и стабильности модели Pixel DiT используются методы переупорядочивания индексов и перемасштабирования шума. Переупорядочивание индексов позволяет эффективно организовать обработку данных, снижая вычислительные затраты и улучшая параллелизм. Перемасштабирование шума, в свою очередь, стабилизирует процесс диффузии, предотвращая чрезмерное отклонение от исходного изображения и обеспечивая более высокое качество генерируемых результатов. Комбинация этих методов позволяет достичь более высокой скорости обучения и улучшенной стабильности модели при генерации изображений.
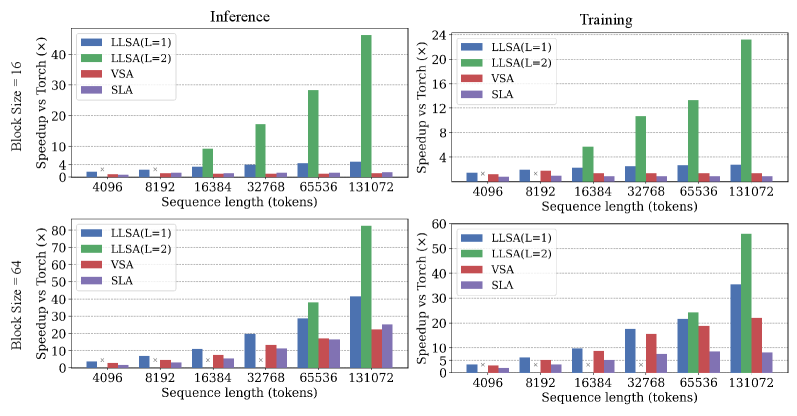
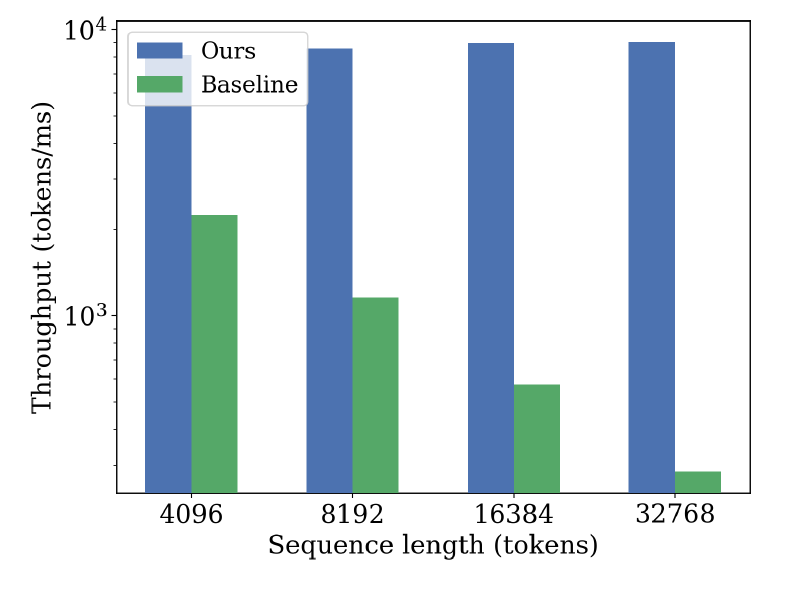
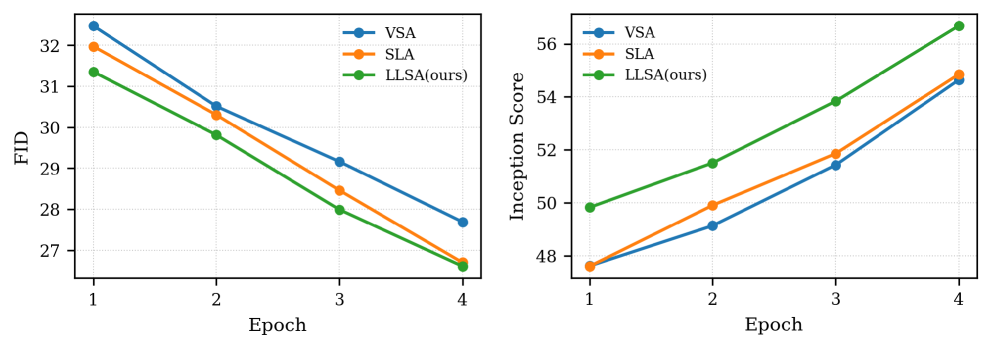
Экспериментальные результаты, полученные на наборах данных ImageNet и FFHQ, демонстрируют способность Pixel DiT генерировать изображения высокого качества при сниженных вычислительных затратах. Ключевым нововведением является механизм Log-linear Sparse Attention (LLSA), позволяющий снизить вычислительную сложность с $O(N^2)$ до $O(N log N)$, где N — количество токенов. В ходе экспериментов LLSA показал 6.09-кратное увеличение пропускной способности обучения по сравнению с DiT, использующими полную аттенцию, на изображениях размером 256×256. Кроме того, LLSA продемонстрировал более низкий показатель FID (Fréchet Inception Distance) по сравнению с VSA (Vector Sparse Attention) и SLA (Sparse Linear Attention) на обоих эталонных наборах данных — FFHQ и ImageNet.
Логарифмически-линейное разреженное внимание (LLSA), реализованное в Pixel DiT, продемонстрировало значительное повышение эффективности обучения. На изображениях размером 256×256 LLSA обеспечило ускорение обучения в 6.09 раза по сравнению с DiT, использующими полномасштабное внимание. В ходе тестирования на эталонных наборах данных FFHQ и ImageNet LLSA показало более низкий показатель FID (Frechet Inception Distance) по сравнению с вариантами VSA (Vector Sparse Attention) и SLA (Sparse Local Attention), что свидетельствует о превосходстве в качестве генерируемых изображений.

Расширяя Горизонты: PixelFlow и Дальше
Модель PixelFlow представляет собой многоступенчатый диффузионный подход к генерации изображений, позволяющий создавать высокодетализированные картинки путем последовательного увеличения разрешения. Вместо генерации изображения высокого разрешения сразу, PixelFlow начинает с создания изображения низкого разрешения, а затем постепенно улучшает его качество и детализацию на нескольких этапах. Этот процесс, известный как прогрессивная дискретизация, позволяет эффективно использовать вычислительные ресурсы и значительно снижает требования к памяти. Каждый этап увеличения разрешения добавляет новые детали и текстуры, пока не будет достигнуто желаемое качество изображения. Такой подход не только обеспечивает высокое качество генерируемых изображений, но и делает процесс более управляемым и эффективным, открывая возможности для создания контента с высоким разрешением даже на устройствах с ограниченными ресурсами.
Успешное применение методов разреженного внимания и оптимизированных диффузионных моделей знаменует собой переход к более эффективным и масштабируемым моделям генерации изображений. Традиционные подходы, требующие огромных вычислительных ресурсов для обработки каждого пикселя, уступают место инновационным техникам, позволяющим значительно сократить сложность вычислений. В частности, разреженное внимание позволяет модели концентрироваться на наиболее релевантных участках изображения, игнорируя несущественные детали, что существенно снижает потребность в памяти и вычислительной мощности. Это открывает возможности для генерации изображений высокого разрешения на более доступном оборудовании и в режиме реального времени, что особенно важно для широкого спектра приложений, включая творческие инструменты, визуальные эффекты и расширенную реальность. Данный сдвиг в сторону эффективности не только снижает затраты, но и способствует демократизации доступа к технологиям генерации изображений, делая их более доступными для исследователей и пользователей по всему миру.
Достижения в области диффузионных моделей, такие как применение разреженного внимания и оптимизированных алгоритмов, открывают новые возможности для генерации изображений в реальном времени и расширяют доступ к высококачественному визуальному контенту. В частности, внедрение LLSA (Long-Range Sparse Attention) привело к значительному снижению вычислительной сложности — с $O(N^2)$ до $O(N log N)$, где N — количество пикселей. Это означает, что генерация детализированных изображений становится возможной на менее мощном оборудовании и с меньшими задержками, что критически важно для интерактивных приложений, таких как редактирование изображений в реальном времени, создание виртуальной реальности и стриминг высококачественного видеоконтента. Подобные улучшения не только ускоряют процесс генерации, но и делают его более экономичным, способствуя широкому распространению технологий искусственного интеллекта в области визуальных искусств и развлечений.
Представленное исследование демонстрирует стремление к математической чистоте в архитектуре Diffusion Transformers. Авторы предлагают механизм Log-linear Sparse Attention (LLSA), направленный на снижение вычислительной сложности самовнимания при обработке длинных последовательностей. Этот подход, по сути, является реализацией принципа, что любое решение должно быть доказуемо корректным, а не просто эмпирически работающим. Как отмечал Ян Лекун: «Машинное обучение — это просто математика». Данная работа подтверждает эту мысль, представляя собой не просто оптимизацию производительности, а элегантное решение, основанное на фундаментальных принципах математической логики и стремящееся к теоретической обоснованности каждого компонента.
Что дальше?
Представленный подход к разреженному вниманию, хотя и демонстрирует снижение вычислительной сложности, оставляет ряд вопросов без ответа. Доказательство корректности предложенной аппроксимации, а не просто эмпирическое подтверждение на тестовых данных, представляется необходимой следующей стадией. Утверждение о линейной сложности требует строгого математического обоснования в условиях произвольной длины последовательности и размера контекстного окна. Иначе, это лишь иллюзия эффективности.
Перспективным направлением представляется исследование адаптивных стратегий выбора разреженных связей. Статичные шаблоны, как правило, не оптимальны. Алгоритмы, способные динамически определять наиболее значимые связи в зависимости от входных данных, могут значительно улучшить качество генерируемых изображений, но требуют существенных вычислительных ресурсов. Впрочем, истинная элегантность алгоритма проявляется не в скорости, а в его математической чистоте и доказуемости.
Наконец, следует признать, что снижение сложности внимания — лишь одна из задач. Узкое место современной диффузионной модели — не внимание, а сам процесс диффузии. Поиск более эффективных алгоритмов семплирования и оптимизации функции потерь, вероятно, принесет более существенные плоды, чем дальнейшая оптимизация внимания, вне зависимости от его сложности.
Оригинал статьи: https://arxiv.org/pdf/2512.16615.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
2025-12-19 19:03