Автор: Денис Аветисян
Новая методика позволяет более точно и осмысленно оценивать работу систем, автоматически создающих вопросы, выявляя и анализируя типичные ошибки.
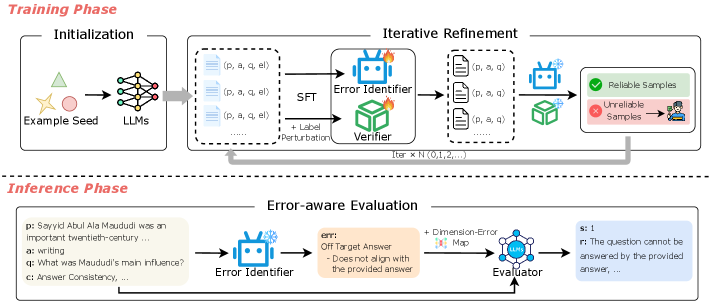
В статье представлена ErrEval — платформа для оценки генерации вопросов, основанная на явной диагностике ошибок и повышающая точность и интерпретируемость результатов.
Автоматическая генерация вопросов часто страдает от критических дефектов, таких как фактические неточности и несоответствие ответам, однако существующие методы оценки, включая использующие большие языковые модели, как правило, не учитывают эти недостатки. В данной работе представлена система ErrEval: Error-Aware Evaluation for Question Generation through Explicit Diagnostics — гибкий фреймворк, улучшающий оценку качества генерируемых вопросов за счет явной диагностики ошибок. ErrEval переформулирует процесс оценки как двухэтапный: сначала выявляются и классифицируются типичные ошибки, а затем эта информация используется для более точной и обоснованной оценки. Способно ли явное выявление ошибок значительно повысить надежность и интерпретируемость автоматической оценки генерации вопросов?
Автоматическая генерация вопросов: вызов для современных систем
Автоматическая генерация вопросов — ключевой элемент современных интерактивных систем обучения и оценки знаний, однако задача эта остается сложной и многогранной. Ее важность обусловлена необходимостью создания персонализированных образовательных траекторий и эффективных инструментов проверки усвоенного материала. В отличие от простого извлечения вопросов из существующего текста, полноценная автоматическая генерация требует не только понимания содержания, но и способности формулировать вопросы, требующие осмысленного ответа, а также учитывать уровень знаний обучающегося. Несмотря на значительный прогресс в области обработки естественного языка, создание алгоритмов, способных генерировать вопросы, не уступающие по качеству вопросам, составленным человеком, представляет собой серьезную научную проблему, требующую дальнейших исследований и инновационных подходов.
Существующие методы автоматической генерации вопросов часто сталкиваются с серьезными проблемами в обеспечении их качества. Вопросы, создаваемые такими системами, нередко страдают от недостаточной связности, что затрудняет понимание их контекста и логики. Более того, значительная часть сгенерированных вопросов оказывается не отвечаемой на основе предоставленного текста, либо содержит фактические неточности и противоречия. Это связано с тем, что алгоритмы, как правило, фокусируются на поверхностном анализе текста, упуская из виду глубокое понимание смысла и взаимосвязей между понятиями, что приводит к созданию формально корректных, но семантически несостоятельных вопросов. Преодоление этих ограничений является ключевой задачей для создания эффективных систем автоматической генерации вопросов, способных поддерживать полноценное интерактивное обучение и объективную оценку знаний.

Оценка качества вопросов: за пределами простых метрик
Традиционные метрики оценки качества сгенерированных вопросов, такие как BLEU и даже BERTScore, фокусируются преимущественно на лексическом совпадении с эталонными вопросами и не учитывают семантическую адекватность. BLEU оценивает n-граммное совпадение, что делает её чувствительной к незначительным вариациям формулировок, не отражающим смысловую эквивалентность. BERTScore, хотя и использует контекстные эмбеддинги, все еще может быть недостаточно чувствителен к тонким различиям в значении, особенно когда вопрос сформулирован другими словами, но сохраняет тот же смысл. Обе метрики не способны адекватно оценить, насколько хорошо сгенерированный вопрос соответствует исходному контексту и является ли он действительно осмысленным и релевантным для проверки понимания материала.
Для всесторонней оценки качества генерируемых вопросов необходимы мета-оценочные бенчмарки, такие как QGEval. QGEval позволяет измерить степень корреляции между автоматическими метриками (например, BLEU, BERTScore) и экспертными оценками, выставляемыми людьми. Этот подход позволяет выявить, насколько точно автоматические метрики отражают реальное семантическое качество вопросов, и определить, какие метрики требуют улучшения или дополнения для более надежной оценки. Использование QGEval обеспечивает объективное сравнение различных методов оценки и позволяет выбрать наиболее эффективные для конкретных задач генерации вопросов.
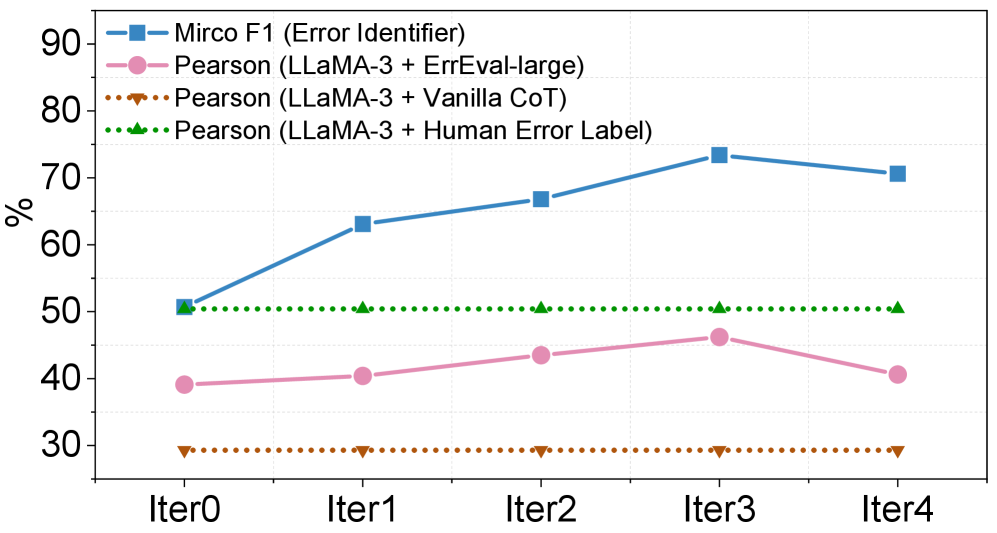
Предложенная основанная на ошибках система оценки (ErrEval) демонстрирует стабильное улучшение соответствия с человеческими оценками. В ходе тестирования на бенчмарке QGEval, ErrEval достигает до 13.2% относительного улучшения коэффициента корреляции Пирсона. Это указывает на более точную оценку качества генерируемых вопросов по сравнению с традиционными метриками, поскольку ErrEval лучше отражает субъективные оценки, данные людьми-экспертами. Повышение корреляции свидетельствует о способности системы более эффективно различать качественные и некачественные вопросы.
Фреймворк ErrEval использует существующие бенчмарки, такие как QGEval, для выявления недостатков в автоматической оценке качества сгенерированных вопросов. В результате, коэффициент корреляции Пирсона, демонстрируемый ErrEval, достигает значения 0.462, что на 12.0% выше, чем у базового подхода CoT (Chain-of-Thought) при использовании четырех различных LLM-оценщиков. Данный результат указывает на улучшенную согласованность автоматических оценок с человеческими суждениями о качестве вопросов, что позволяет более эффективно оценивать и совершенствовать системы генерации вопросов.

Детализируя ошибки: таксономия для улучшения
ErrEval использует детализированную таксономию ошибок для классификации дефектов в генерируемых вопросах. Эта таксономия разделяет ошибки на три основные категории: структурные, лингвистические и содержательные. Структурные ошибки касаются неправильной грамматической конструкции вопроса или несоответствия между вопросом и ожидаемым типом ответа. Лингвистические ошибки включают в себя неточности в использовании слов, грамматические ошибки и стилистические недостатки. Содержательные ошибки возникают, когда вопрос не соответствует контексту, содержит фактические неточности или не проверяет понимание ключевой информации. Классификация по этим категориям позволяет проводить более точную диагностику проблем и разрабатывать целевые стратегии улучшения качества генерируемых вопросов.
Диагностические возможности системы ErrEval усиливаются за счет методов идентификации ошибок, в частности, с использованием оптимизированных моделей, таких как RoBERTa. Данный подход позволяет автоматически определять типы ошибок в сгенерированных вопросах, что необходимо для дальнейшего анализа и улучшения качества генерации. RoBERTa, будучи предобученной моделью на большом объеме текстовых данных, демонстрирует высокую эффективность в задачах классификации и понимания естественного языка, что делает ее подходящим инструментом для выявления структурных, лингвистических и содержательных ошибок.
В ходе тестирования на наборе данных SQuAD 2.0, модель ErrEval-large продемонстрировала точность в 67.5%. Этот показатель на 4.6% превышает точность базовой модели Chain-of-Thought (CoT) без дополнительных улучшений. Данный прирост точности указывает на эффективность используемой в ErrEval-large таксономии ошибок и методов их выявления, что позволяет более корректно оценивать качество генерируемых вопросов и ответов по сравнению со стандартным подходом CoT.
В процессе оценки качества генерируемых вопросов, модуль Верификатора продемонстрировал эффективность в идентификации ошибок, достигнув показателя Micro F1 Score в 77.3% на размеченном наборе данных (development set). Данный показатель является метрикой, отражающей точность и полноту обнаружения ошибок, и позволяет оценить способность системы к выявлению несоответствий в генерируемых вопросах. Высокий показатель Micro F1 Score указывает на то, что Верификатор эффективно идентифицирует как верно-положительные, так и верно-отрицательные случаи, обеспечивая надежную диагностику ошибок в процессе генерации вопросов.
Использование LLM как интеллектуальных оценщиков
Современные исследования активно изучают возможности использования больших языковых моделей (LLM) в качестве оценивающих систем, выходя за рамки традиционных метрик. Вместо простого подсчета совпадений или использования заранее заданных критериев, LLM способны анализировать вопросы с точки зрения их сложности, ясности и способности стимулировать критическое мышление. Этот подход позволяет оценивать качество вопросов более тонко и комплексно, учитывая не только формальные характеристики, но и семантическую значимость и потенциальную пользу для обучающегося. Благодаря способности к пониманию естественного языка, LLM могут выявлять скрытые недостатки или двусмысленности, которые остаются незамеченными при использовании стандартных метрик, открывая новые перспективы для автоматической оценки и улучшения систем генерации вопросов.
Методика “цепочки рассуждений” (Chain-of-Thought Prompting) позволяет побудить большие языковые модели (LLM) не просто оценивать качество вопроса, но и предоставлять развернутое обоснование своей оценки. Вместо простого присвоения числового значения, модель формулирует объяснение, указывая, какие аспекты вопроса делают его удачным или неудачным — например, четкость формулировки, соответствие заданной теме или потенциальную полезность для пользователя. Такой подход значительно повышает ценность оценки, поскольку позволяет получить ценные сведения о причинах успеха или провала конкретного вопроса, что может быть использовано для улучшения систем генерации вопросов и повышения их качества.
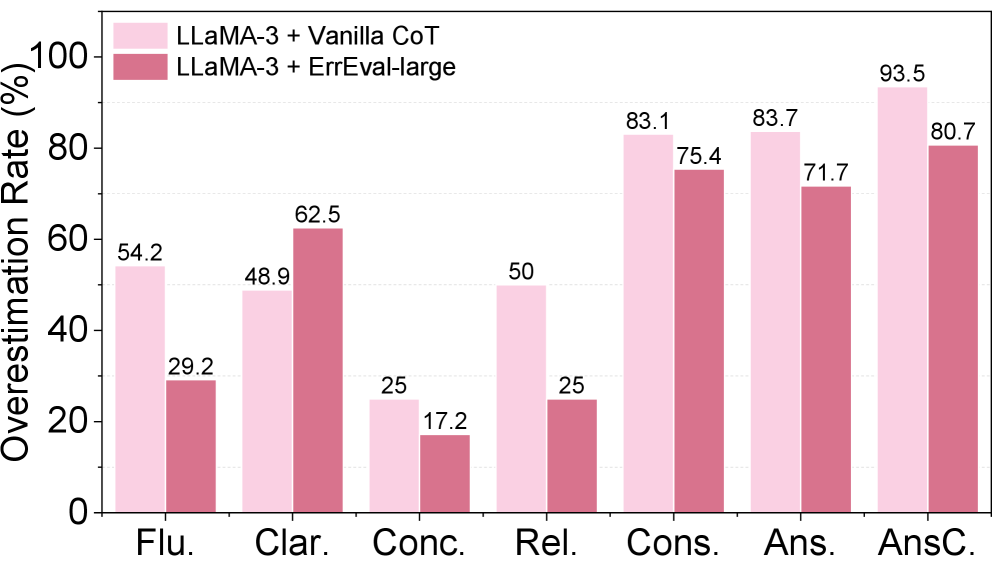
Исследование ErrEval продемонстрировало высокую надежность подхода к оценке качества вопросов, подтвержденную минимальным влиянием на корректные исходные данные. В ходе экспериментов до 97.58% образцов, изначально признанных верными, остались без изменений после применения метода ErrEval. Это указывает на то, что система оценки не вносит случайные искажения и способна точно выделять проблемные вопросы, не затрагивая при этом качественные примеры. Такая стабильность и точность делают ErrEval перспективным инструментом для автоматизированной оценки систем генерации вопросов, позволяя разработчикам более эффективно выявлять и устранять недостатки.
Сочетание передовых методов оценки на базе больших языковых моделей и систем-верификаторов открывает перспективные пути к созданию более адекватных и приближенных к человеческому восприятию инструментов для анализа систем генерации вопросов. Традиционные метрики часто не учитывают нюансы качества, такие как логичность, релевантность и ясность формулировок. Новые подходы позволяют не только выявлять слабые места в генерируемых вопросах, но и предоставлять развернутые объяснения причин, что существенно облегчает процесс их улучшения. Такая синергия позволяет перейти от простой количественной оценки к более глубокому и качественному анализу, что, в свою очередь, способствует созданию систем, генерирующих вопросы, действительно полезные и понятные для пользователей.
К устойчивой и надежной генерации вопросов
Современные исследования в области автоматической генерации вопросов демонстрируют значительный прогресс благодаря комплексному подходу, сочетающему оценку с учетом потенциальных ошибок, передовые методы оценки на базе больших языковых моделей и использование эталонных наборов данных, таких как SimQG и SQuAD. Такая комбинация позволяет не просто оценивать грамматическую корректность сгенерированных вопросов, но и анализировать их релевантность, сложность и способность стимулировать глубокое понимание материала. Благодаря этому, разработчики могут выявлять слабые места существующих моделей и создавать более надежные и эффективные системы, способные генерировать вопросы, действительно способствующие обучению и поиску знаний.
Дальнейшие исследования в области автоматической генерации вопросов должны быть направлены на создание моделей, способных формировать не просто грамматически верные запросы, а действительно проницательные, стимулирующие глубокое осмысление материала. Акцент смещается с формальной корректности к содержательной ценности вопроса — способности побудить пользователя к критическому анализу, поиску связей и формированию новых знаний. Такие модели должны уметь выявлять ключевые концепции, предвидеть возможные затруднения в понимании и генерировать вопросы, направленные на преодоление этих трудностей, тем самым превращая процесс обучения в активное и продуктивное взаимодействие.
Развитие технологий автоматической генерации вопросов обладает огромным потенциалом для коренной трансформации ключевых областей. В сфере образования, такие системы способны адаптировать учебный процесс к индивидуальным потребностям каждого ученика, создавая персонализированные тесты и задания, способствующие более глубокому усвоению материала. В области поиска и анализа знаний, автоматическая генерация вопросов может служить мощным инструментом для извлечения скрытой информации из больших объемов текста, помогая исследователям формулировать новые гипотезы и открывать закономерности. Наконец, в сфере взаимодействия человека и компьютера, такие системы способны создавать более естественные и интуитивно понятные интерфейсы, позволяя пользователям получать необходимую информацию в форме вопросов и ответов, что значительно упрощает доступ к знаниям и повышает эффективность коммуникации.
Исследование, представленное в данной работе, подчеркивает необходимость более глубокого анализа систем генерации вопросов, выходящего за рамки простой оценки метрик. Авторы предлагают ErrEval — фреймворк, ориентированный на выявление конкретных ошибок, что соответствует философскому взгляду на старение систем. Как заметил Эдсгер Дейкстра: «Программирование — это не столько техника, сколько искусство». Данный подход к оценке, акцентирующий внимание на диагностике, позволяет не просто констатировать факт наличия ошибок, но и понимать их природу, тем самым способствуя более эффективной эволюции системы. Это особенно важно, учитывая, что стабильность, достигнутая за счет игнорирования внутренних проблем, может оказаться лишь отсрочкой неизбежного кризиса.
Что впереди?
Представленная работа, стремясь к более тонкой диагностике ошибок в генерации вопросов, неизбежно обнажает сложность самой метрики «качества». Недостаточно просто выявить несоответствие — необходимо понять, почему оно возникло, и что важнее, — является ли это проявлением неизбежной энтропии системы или симптомом конструктивной слабости. Архитектура, лишенная истории своих ошибок, действительно хрупка, но и бесконечная детализация провалов не гарантирует долговечности.
В дальнейшем, вероятно, потребуется смещение фокуса с количественной оценки ошибок на качественное их понимание. Простая статистика несоответствий не раскроет тонкостей взаимодействия языковой модели с реальностью, её склонности к определённым видам галлюцинаций или предвзятостей. Каждая задержка в достижении абсолютной точности — это цена более глубокого понимания границ применимости этих моделей.
Поиск универсальной метрики, способной уловить все нюансы генерации вопросов, — занятие, возможно, бесплодное. Более перспективным представляется создание набора специализированных диагностических инструментов, адаптированных к конкретным типам вопросов и целевым аудиториям. Или, возможно, нам следует признать, что идеальная генерация вопросов — это иллюзия, а задача состоит лишь в том, чтобы создавать вопросы, достаточно хорошие для конкретной цели, в конкретный момент времени.
Оригинал статьи: https://arxiv.org/pdf/2601.10406.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-18 19:19