Автор: Денис Аветисян
Новый метод позволяет эффективно восстановить производительность больших языковых моделей, оптимизированных для работы с 4-битными вычислениями.
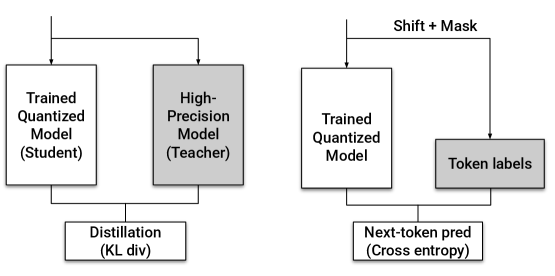
В статье представлена методика Quantization-Aware Distillation (QAD) для повышения точности инференса LLM, квантованных до NVFP4, превосходящая традиционную Quantization-Aware Training (QAT).
Квантование моделей глубокого обучения, необходимое для эффективного развертывания, часто приводит к значительной потере точности. В данной работе, ‘Quantization-Aware Distillation for NVFP4 Inference Accuracy Recovery’, представлен метод дистилляции с учетом квантования (QAD), позволяющий восстановить точность больших языковых и мультимодальных моделей, квантованных до NVFP4. QAD демонстрирует высокую эффективность и стабильность, особенно в случае моделей, обученных с использованием многоэтапных конвейеров пост-обучения, где традиционное обучение с учетом квантования (QAT) сталкивается с трудностями. Сможет ли QAD стать стандартным подходом к восстановлению точности квантованных моделей и упростить их развертывание в реальных приложениях?
Эффективность как Предел: Узкое Место Больших Языковых Моделей
Несмотря на впечатляющие достижения в области искусственного интеллекта, большие языковые модели (БЯМ) по-прежнему требуют значительных вычислительных ресурсов, что ограничивает их широкое распространение и внедрение. Обучение и функционирование этих моделей, способных генерировать текст, переводить языки и отвечать на вопросы, связано с огромными затратами энергии и требует дорогостоящего оборудования. Это создает существенные препятствия для исследователей и организаций с ограниченными ресурсами, а также замедляет развертывание БЯМ в приложениях, требующих оперативной обработки данных, например, в мобильных устройствах или системах реального времени. Необходимость снижения вычислительной нагрузки является ключевой задачей для обеспечения доступности и практического применения этих мощных инструментов.
Традиционные методы разработки больших языковых моделей сталкиваются с серьезной проблемой: увеличение масштаба модели не всегда приводит к пропорциональному улучшению производительности, а зачастую требует экспоненциального роста вычислительных ресурсов. Это создает узкое место в эффективности, ограничивая возможности развертывания и использования этих моделей на широком спектре устройств и приложений. В связи с этим, все больше внимания уделяется техникам квантования — методам снижения точности представления параметров модели, что позволяет существенно уменьшить ее размер и вычислительную нагрузку без критичной потери качества. Квантование, таким образом, представляет собой ключевое направление исследований, направленное на создание более компактных и эффективных языковых моделей, доступных для более широкого круга пользователей и задач.
Для решения всё более сложных задач, требующих от больших языковых моделей (БЯМ) обработки огромных объемов информации и выполнения многоступенчатых рассуждений, необходима существенная оптимизация как потребления памяти, так и вычислительных затрат. Современные БЯМ часто оказываются непомерно ресурсоемкими, что ограничивает их применение на устройствах с ограниченными возможностями и препятствует масштабному развертыванию. Уменьшение «следа» модели в памяти и снижение требований к вычислительной мощности позволит не только ускорить обработку данных, но и расширить круг потенциальных пользователей и сценариев применения, открывая новые горизонты для развития искусственного интеллекта и обработки естественного языка. Достижение этой цели требует инновационных подходов к архитектуре моделей, алгоритмам обучения и методам сжатия данных.
Квантование: Путь к Эффективности
Квантизация, заключающаяся в снижении точности представления числовых данных, является прямым способом компрессии моделей и повышения скорости вычислений. Традиционно, модели машинного обучения используют 32-битные числа с плавающей точкой (float32) для представления весов и активаций. Уменьшение разрядности до 8 бит (int8) или даже до 4 бит (например, NVFP4) позволяет значительно сократить объем памяти, необходимый для хранения модели, и снизить вычислительную нагрузку, поскольку операции с меньшей точностью требуют меньше ресурсов. Это достигается за счет уменьшения количества бит, используемых для кодирования каждого числа, что напрямую влияет на размер модели и скорость выполнения операций, таких как умножение матриц и сложение векторов.
Формат NVFP4 представляет собой 4-битный формат чисел с плавающей точкой, разработанный для повышения эффективности обучения и инференса на графических процессорах (GPU). В отличие от традиционных 32-битных или 16-битных форматов, использование 4 бит для представления чисел позволяет существенно сократить объем памяти, необходимый для хранения весов и активаций модели. Это, в свою очередь, приводит к ускорению вычислений, поскольку требуется меньше операций по чтению и записи данных. NVFP4 оптимизирован для архитектуры GPU NVIDIA и поддерживает аппаратное ускорение, что обеспечивает более высокую производительность по сравнению с программной эмуляцией пониженной точности. Применение NVFP4 позволяет добиться значительного улучшения пропускной способности и снижения энергопотребления при выполнении задач машинного обучения.
Использование формата NVFP4, 4-битного представления чисел с плавающей точкой, позволяет существенно уменьшить размер моделей машинного обучения и снизить вычислительные затраты. Переход от традиционных 32-битных или 16-битных представлений к NVFP4 приводит к четырехкратному или восьмикратному уменьшению объема памяти, необходимого для хранения весов и активаций модели. Это, в свою очередь, позволяет развертывать сложные модели на устройствах с ограниченными ресурсами, таких как мобильные телефоны, встраиваемые системы и периферийные вычислительные устройства, где память и энергопотребление являются критическими факторами. Снижение вычислительной сложности достигается за счет использования операций с меньшей точностью, что приводит к ускорению вычислений на графических процессорах (GPU), поддерживающих данный формат.
Калибровка: Искусство Баланса
Пост-тренировочная квантизация (PTQ) требует эффективной калибровки для преобразования весов модели из формата с плавающей точкой в квантованные значения. Этот процесс включает в себя определение оптимального диапазона и масштаба для представления весов с использованием меньшего количества бит, например, 8-битных целых чисел. Калибровка осуществляется на репрезентативном наборе данных, позволяющем оценить распределение активаций и весов модели. От точности калибровки напрямую зависит сохранение точности модели после квантизации, поскольку неверное масштабирование или смещение может привести к значительным потерям информации и снижению производительности. Различные методы калибровки, такие как калибровка по максимальному значению или среднеквадратичной ошибке (MSE), направлены на минимизацию этих потерь и обеспечение высокой точности квантованной модели.
Методы калибровки, такие как Max Calibration и калибровка на основе среднеквадратичной ошибки (MSE), уточняют процесс квантования путем минимизации потери информации. Max Calibration определяет масштабный коэффициент квантования, используя максимальное абсолютное значение весов, что позволяет эффективно отображать диапазон значений с плавающей точкой в целочисленный формат. В свою очередь, MSE-калибровка стремится минимизировать среднеквадратичную ошибку между исходными значениями с плавающей точкой и квантованными значениями, что приводит к более точному представлению весов и, следовательно, к сохранению производительности модели. Оба метода позволяют оптимизировать процесс квантования, снижая влияние квантизации на точность модели и обеспечивая эффективное сжатие без значительной потери качества.
Успешная калибровка, использующая постобучающую квантизацию (PTQ) с форматом NVFP4, позволяет сохранять точность модели при значительной компрессии. Экспериментальные данные демонстрируют, что применение NVFP4 в процессе PTQ, в сочетании с эффективными алгоритмами калибровки, позволяет добиться сжатия модели до 4 раз без существенной потери производительности. Сохранение точности достигается за счет минимизации ошибок квантования и оптимизации распределения значений весов и активаций в ограниченном диапазоне представления NVFP4. Такой подход позволяет развертывать модели на устройствах с ограниченными ресурсами, сохраняя при этом приемлемый уровень точности и скорость работы.
Квантованная Дистилляция: Передача Знаний
Метод квантованной дистилляции с учётом квантования (QAD) использует обученную «учительскую» модель для направления процесса обучения «студенческой» модели, подвергающейся квантованию, что позволяет значительно повысить её точность. В основе подхода лежит передача знаний от более сложной и точной «учительской» модели к более компактной «студенческой», при этом процесс обучения адаптирован к ограничениям, вносимым квантованием. Это позволяет «студенческой» модели сохранять высокую производительность даже при значительном снижении вычислительных затрат, что особенно важно для развертывания моделей на устройствах с ограниченными ресурсами. Таким образом, QAD представляет собой эффективный способ сжатия моделей без существенной потери точности, открывая возможности для более широкого применения передовых алгоритмов искусственного интеллекта.
В основе метода Quantization-Aware Distillation (QAD) лежит эффективная передача знаний от более крупной, точной модели-учителя к компактной, квантованной модели-ученику. Ключевым инструментом в этом процессе выступает функция потерь, основанная на дивергенции Кульбака-Лейблера (KL Divergence). KL(P||Q) = \sum_i P(i) \log \frac{P(i)}{Q(i)} Эта функция измеряет разницу между распределениями вероятностей, генерируемыми учителем и учеником, и побуждает ученика максимально приблизить свое поведение к учителю. Благодаря KL Divergence, ученик не просто имитирует предсказания учителя, но и учится понимать лежащие в их основе закономерности, что позволяет значительно повысить его точность даже после квантования и уменьшения размера. Таким образом, QAD обеспечивает эффективный перенос знаний, минимизируя потери точности, связанные с уменьшением вычислительных ресурсов.
Применение методики квантизационно-зависимой дистилляции (QAD) с моделями, такими как Llama Nemotron Super, AceReason Nemotron и Nemotron Nano, демонстрирует существенное повышение производительности по сравнению со стандартной квантизацией. Исследования показывают, что QAD позволяет добиться прироста точности до 5.8% на эталонных тестах, например, GPQA-D, в сравнении с квантизацией с обучением (QAT). Данный подход позволяет эффективно переносить знания от более крупной, точной модели-учителя к компактной квантованной модели-ученику, сохраняя при этом высокую производительность и снижая вычислительные затраты. Полученные результаты подтверждают, что QAD является перспективным методом для развертывания больших языковых моделей на ресурсоограниченных устройствах без значительной потери качества.
Применение методики квантизационно-зависимой дистилляции (QAD) к модели Llama Nemotron Super V1 демонстрирует ощутимый прирост точности на ключевых бенчмарках. В частности, зафиксировано увеличение показателя на 4.1% при оценке на наборе данных AIME 2025, а также улучшение на 1.2% на GPQA Diamond. Эти результаты свидетельствуют об эффективности QAD в сохранении точности модели при снижении вычислительных ресурсов, что особенно важно для развертывания моделей на ресурсоограниченных устройствах и снижения затрат на вычислительные ресурсы. Подобные улучшения позволяют значительно повысить практическую ценность больших языковых моделей без существенных потерь в качестве генерируемого текста.
Исследования показали, что применение методики квантизационно-зависимой дистилляции (QAD) к модели Nemotron Nano 9B V2 демонстрирует существенное повышение точности. В частности, на бенчмарке AIME 2025 наблюдается прирост в 4.4%, а на GPQA Diamond — 5.8%. Эти результаты подчеркивают эффективность QAD в сохранении и улучшении производительности модели при снижении вычислительной сложности, что делает Nemotron Nano 9B V2 более доступным для развертывания в условиях ограниченных ресурсов, не жертвуя при этом качеством генерации ответов.
Исследования показали, что методика квантизации с учетом дистилляции (QAD) способна восстановить точность, сопоставимую с использованием формата BF16, что особенно заметно на примере модели AceReason Nemotron 7B при оценке на наборе данных GPQA Diamond. Это означает, что QAD позволяет существенно снизить вычислительные затраты и требования к памяти, связанные с использованием более точных, но ресурсоемких форматов, таких как BF16, практически не теряя в качестве результатов. Достижение такой близости к точности BF16 при квантизации открывает возможности для развертывания сложных языковых моделей на более широком спектре устройств и делает их доступными для большего числа пользователей.
Эффективность метода квантизации с учетом дистилляции (QAD) напрямую зависит от качества используемых обучающих данных, однако, для достижения максимальных результатов, возможно существенное усиление за счет применения синтетических данных и переноса знаний из других доменов. Исследования показали, что для обучения модели AceReason Nemotron 7B с использованием QAD требуется приблизительно 0.8 миллиарда токенов, при этом грамотное дополнение данных и использование техник трансфера обучения позволяют не только повысить точность, но и сократить объем необходимых ресурсов для достижения сопоставимых результатов. Это открывает возможности для адаптации и улучшения моделей даже при ограниченном доступе к большим объемам размеченных данных.
Нативная Квантизация: Будущее Эффективности
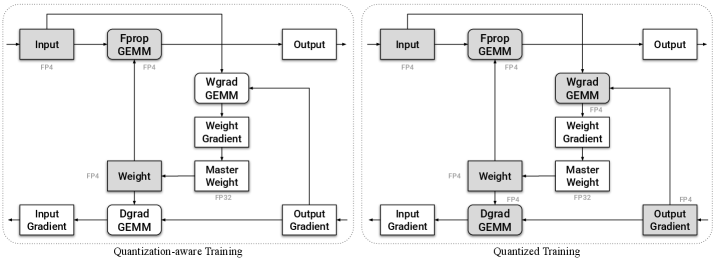
Непосредственная квантизация весов, активаций и градиентов в процессе обучения, известная как Native Quantized Training, представляет собой эффективный метод снижения вычислительных затрат. В отличие от традиционных подходов, где квантизация применяется после завершения обучения, данный метод интегрирует процесс квантизации непосредственно в цикл обучения модели. Это позволяет значительно уменьшить объем памяти, необходимый для хранения параметров модели, и ускорить выполнение операций, поскольку вычисления производятся с использованием целочисленной арифметики вместо арифметики с плавающей точкой. Такой подход особенно актуален для крупных языковых моделей, где объем параметров может достигать миллиардов, что существенно ограничивает возможности развертывания на устройствах с ограниченными ресурсами.
Применение метода нативной квантизации при обучении больших языковых моделей открывает значительные перспективы для существенного ускорения процессов обучения и последующей работы с этими моделями. Традиционно, обучение и вывод требуют больших вычислительных ресурсов и времени, однако квантизация — представление данных с использованием меньшего количества битов — позволяет значительно снизить эти затраты. В случае с большими языковыми моделями, где количество параметров исчисляется миллиардами, даже небольшое уменьшение точности представления данных может привести к значительному приросту скорости и снижению потребления памяти. Это, в свою очередь, позволяет обучать и развертывать более сложные модели на менее дорогостоящем оборудовании, делая передовые технологии искусственного интеллекта более доступными и эффективными.
Сочетание обучения с собственной квантизацией (Native Quantized Training) с методами квантизационно-чувствительной оптимизации (Quantization-Aware Design, QAD) и усовершенствованными техниками калибровки представляет собой многообещающий путь к созданию высокоэффективных и доступных больших языковых моделей. Данный подход позволяет не только снизить вычислительные затраты за счет уменьшения разрядности весов и активаций, но и минимизировать потерю точности, обычно возникающую при квантизации. Усовершенствованные методы калибровки, в частности, позволяют более точно определить оптимальные значения квантования, адаптируясь к специфике каждой модели и задачи. В результате, достигается значительное ускорение обучения и инференса, а также снижение требований к аппаратным ресурсам, что открывает возможности для развертывания сложных моделей искусственного интеллекта на более широком спектре устройств.
Исследования в области оптимизации моделей искусственного интеллекта указывают на перспективу широкого распространения сложных алгоритмов на разнообразных аппаратных платформах. Вместо того чтобы ограничиваться мощными серверными установками, передовые модели, такие как большие языковые модели, смогут функционировать эффективно даже на устройствах с ограниченными ресурсами — от смартфонов до встраиваемых систем. Такая демократизация доступа к мощному искусственному интеллекту откроет новые возможности для инноваций в различных областях, позволяя разработчикам и исследователям создавать приложения, которые ранее были невозможны из-за аппаратных ограничений, и сделает передовые технологии доступными для большего числа пользователей.
Исследование демонстрирует, что традиционные методы Quantization-Aware Training (QAT) оказываются недостаточно эффективными при работе со сложными, уже обученными моделями. Предложенная методика Quantization-Aware Distillation (QAD) позволяет не только восстановить точность инференса LLM, квантованных до NVFP4, но и превзойти QAT по стабильности. Это подтверждает, что понимание внутренней структуры системы, а не просто слепое следование правилам, позволяет находить более эффективные решения. Как однажды заметила Ада Лавлейс: «Чтобы понять систему, нужно изучить её устройство, а не просто наблюдать за её работой.» Этот принцип находит отражение в подходе QAD, который акцентирует внимание на передаче знаний от более точной модели к квантованной, что позволяет минимизировать потери точности.
Куда двигаться дальше?
Представленная работа демонстрирует, что восстановление точности при использовании NVFP4 — задача не только решаемая, но и поддающаяся более изящным методам, чем традиционное обучение с учётом квантизации. Однако, за кажущейся эффективностью квантизационной дистилляции скрывается вопрос: насколько глубоко мы действительно понимаем природу потери информации при столь агрессивном снижении точности? Иными словами, дистилляция — это лишь временное замаскирование неизбежной энтропии, или же реальный путь к созданию моделей, не уступающих своим 16- или 32-битным предшественникам?
Следующим шагом представляется не просто улучшение существующих алгоритмов дистилляции, а переосмысление самой концепции представления информации. Возможно, истинный прорыв лежит в разработке новых числовых форматов, изначально оптимизированных для работы с квантованными данными, а не в попытках насильно втиснуть полновесные числа в узкие рамки. Необходимо исследовать, как различные архитектуры моделей взаимодействуют с квантованными представлениями, и как эти взаимодействия можно использовать для минимизации потерь точности.
Наконец, стоит признать, что текущие метрики оценки качества моделей могут быть неадекватны для оценки квантованных систем. Вполне возможно, что для выявления реальных возможностей и ограничений NVFP4 необходимы новые методы анализа, учитывающие специфику работы с низкоточными данными. Иначе, мы рискуем оптимизировать модели не по реальной производительности, а по иллюзорным показателям.
Оригинал статьи: https://arxiv.org/pdf/2601.20088.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Адаптация моделей к новым данным: квантильная коррекция для нейросетей
- Голос в переводе: как нейросети учатся понимать речь
- Игры без модели: новый подход к управлению в условиях неопределенности
- Проверка научных статей: новый эталон для автоматического рецензирования
- Цифровые двойники: первый опыт обучения
- Ищем закономерности: Новый пакет TSQCA для R
- Где «смотрят» большие языковые модели: новый взгляд на визуальное понимание
- Волны звука под контролем нейросети: моделирование и инверсия в вязкоупругой среде
- Эмоциональный отпечаток: Как мы научили ИИ читать душу (и почему рейтинги вам врут)
2026-01-29 23:16