Автор: Денис Аветисян
Исследователи представили Phi-Former — инновационную систему глубокого обучения, повышающую точность предсказания взаимодействия между химическими соединениями и белками.
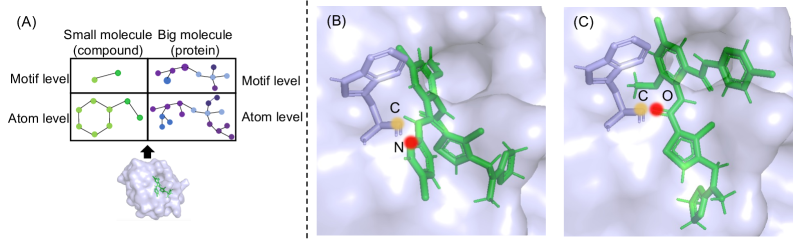
Phi-Former использует иерархическое представление и предварительное обучение для моделирования взаимодействий на атомном и уровне мотивов.
Поиск и разработка новых лекарственных препаратов остается сложной и дорогостоящей задачей, требующей учета множества факторов взаимодействия. В данной работе, представленной в статье ‘Phi-Former: A Pairwise Hierarchical Approach for Compound-Protein Interactions Prediction’, предложен новый подход к прогнозированию взаимодействия между соединениями и белками, основанный на иерархическом представлении и предварительном обучении модели. Phi-Former учитывает биологическую роль мотивов и моделирует взаимодействия на различных уровнях — от атомарного до уровне функциональных групп, что позволяет повысить точность прогнозирования. Сможет ли предложенный метод ускорить процесс разработки лекарств и способствовать созданию более эффективных и безопасных препаратов?
Точность Предсказания: Фундамент Разработки Лекарств
Точное предсказание силы взаимодействия между лекарственным соединением и белком-мишенью является краеугольным камнем успешной разработки новых препаратов, однако эта задача по-прежнему представляет собой серьезную проблему. Сложность обусловлена многофакторностью процесса связывания, включающего не только геометрическое соответствие, но и электростатические взаимодействия, гидрофобные эффекты и конформационные изменения. Неточное предсказание может привести к отбору неэффективных соединений, что влечет за собой значительные финансовые потери и задержки в выходе новых лекарств на рынок. Повышение точности таких предсказаний имеет решающее значение для снижения рисков и ускорения процесса создания инновационных терапевтических средств.
Традиционные методы предсказания силы взаимодействия между соединениями и белками часто сталкиваются с трудностями, обусловленными сложностью этих процессов. Взаимодействие не ограничивается простой геометрической совместимостью, а включает в себя динамические изменения конформации белка, электростатические взаимодействия, водородные связи и ван-дер-ваальсовы силы. Неспособность адекватно учесть все эти факторы приводит к высокой вероятности ложноположительных и ложноотрицательных результатов, что, в свою очередь, значительно увеличивает число неудачных клинических испытаний новых лекарственных препаратов. По этой причине, точное моделирование этих сложных взаимодействий остается критически важной задачей для современной фармацевтической разработки, требующей новых подходов и более совершенных вычислительных методов.
Современные модели, основанные на анализе последовательностей и структуры белков, нуждаются в существенном усовершенствовании для более точной оценки сродства связывания. Несмотря на значительный прогресс в вычислительной биологии, предсказание силы взаимодействия между соединениями и белками остается сложной задачей. Существующие алгоритмы часто упрощают реальные процессы, игнорируя тонкие структурные изменения, динамику белковых комплексов и роль растворителя. Более того, многие модели испытывают трудности с обработкой данных о белках, структура которых недостаточно изучена или подвержена конформационным изменениям. Поэтому разработка новых методов, учитывающих эти нюансы и использующих более совершенные алгоритмы машинного обучения, является ключевым направлением в современной фармацевтической химии и протеомике. Точное предсказание сродства связывания позволит значительно сократить время и затраты на разработку лекарственных препаратов, а также повысить вероятность успеха клинических испытаний.
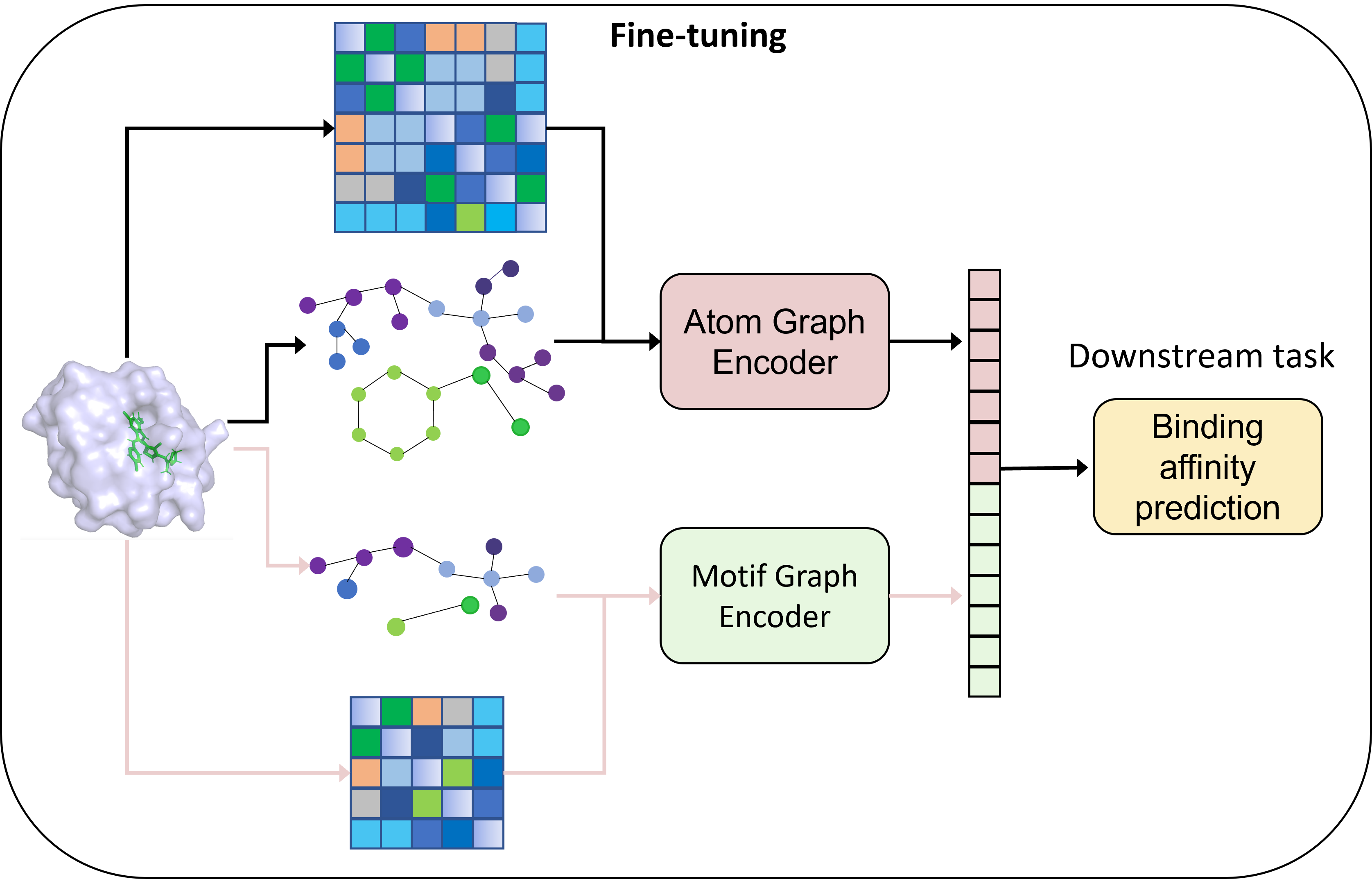
Phi-former: Иерархический Подход к Моделированию Взаимодействий
Phi-former представляет собой фреймворк для обучения представлений взаимодействий на основе иерархического подхода, использующий возможности Graph Transformers. В его основе лежит представление молекул посредством парных взаимодействий, моделируемых с использованием графовых трансформаторов. Данный подход позволяет эффективно захватывать сложные взаимосвязи между атомами и фрагментами молекулы, представляя их в виде иерархической структуры. Использование Graph Transformers обеспечивает возможность агрегации информации от соседних узлов графа, что способствует более точному моделированию молекулярных взаимодействий и свойств. Фреймворк предназначен для задач предсказания химических свойств и разработки новых материалов.
Модель Phi-former применяет иерархическое моделирование для представления молекул, начиная с графов на уровне атомов и переходя к графам на уровне мотивов. Это достигается путем последовательного построения абстракций: изначально каждый атом рассматривается как узел в графе, описывающем его связи с соседними атомами. Далее, алгоритмы выявления мотивов идентифицируют подструктуры, состоящие из нескольких атомов, которые затем представляются как единые узлы в графе более высокого уровня. Такой подход позволяет моделировать молекулы на различных масштабах, эффективно представляя как локальные взаимодействия между атомами, так и глобальные свойства молекулярной структуры, что способствует повышению точности предсказаний.
Для точного моделирования молекулярных взаимодействий в Phi-former используется кодирование пространственной позиции. Данная методика позволяет эффективно учитывать трёхмерные координаты атомов, что критически важно для описания их взаимного расположения и силы взаимодействия. Внедрение кодирования пространственной позиции позволяет модели различать атомы, находящиеся на одинаковом расстоянии, но в разных направлениях, что значительно повышает точность предсказания свойств молекул и их поведения в различных химических процессах. В Phi-former кодирование позиционной информации интегрируется непосредственно в архитектуру Graph Transformer, позволяя модели использовать информацию о координатах атомов на каждом этапе обработки графа.
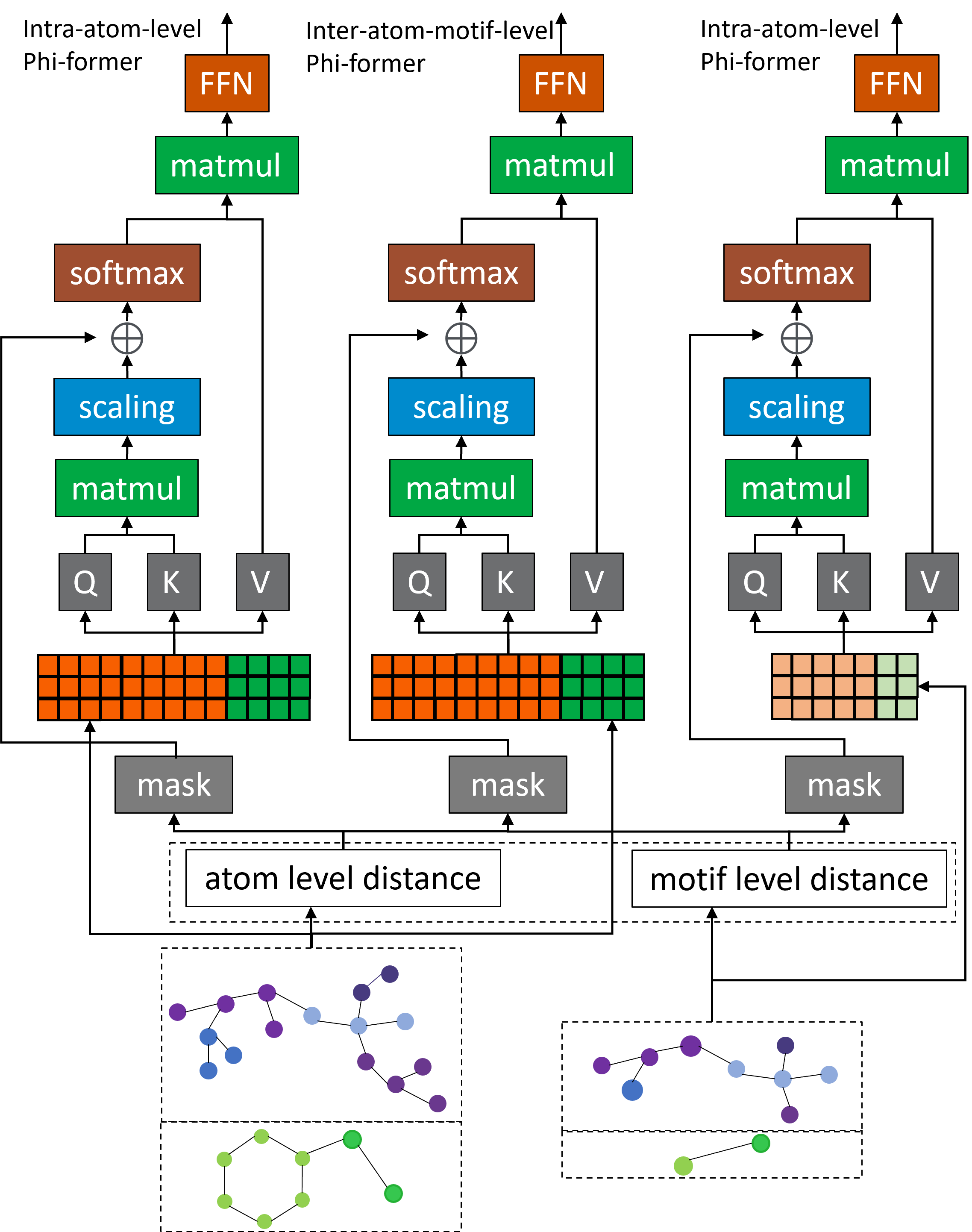
Оптимизация Обучения с Помощью Иерархических Функций Потерь
Phi-former использует как внутриуровневые (Intra-Loss), так и межъуровневые (Inter-Loss) функции потерь для оптимизации обучения на различных уровнях иерархии. Внутриуровневые функции потерь оптимизируют представление отдельных компонентов и взаимодействий на локальном уровне, в то время как межъуровневые функции потерь направлены на оптимизацию взаимодействия между различными уровнями иерархической структуры, обеспечивая согласованность и целостность модели. Такой двойной подход позволяет модели эффективно учитывать как локальные, так и глобальные зависимости в комплексе «белок-лиганд», что способствует более точному предсказанию аффинности связывания.
Двойная функция потерь, используемая в модели, обеспечивает одновременную оптимизацию как локальных, так и глобальных взаимодействий внутри комплекса «соединение-белок». Локальные взаимодействия, определяемые внутри отдельных фрагментов молекул, учитываются для точного моделирования связей в непосредственной близости. Глобальные взаимодействия, напротив, охватывают более широкие области комплекса, позволяя модели улавливать долгосрочные зависимости и общую структуру. Такое сочетание позволяет более полно и точно описывать процесс связывания, что критически важно для прогнозирования аффинности и стабильности комплекса.
Результаты тестирования модели на наборе данных PDBBind 2019 продемонстрировали ее превосходство над существующими методами, включая MONN, TankBind, OnionNet, IGN и SS-GNN. Модель достигла среднеквадратичной ошибки (RMSE) в 1.159 и коэффициента корреляции Пирсона в 0.846. Данные показатели свидетельствуют о более высокой точности предсказаний по сравнению с альтернативными подходами к определению взаимодействия между белками и соединениями.
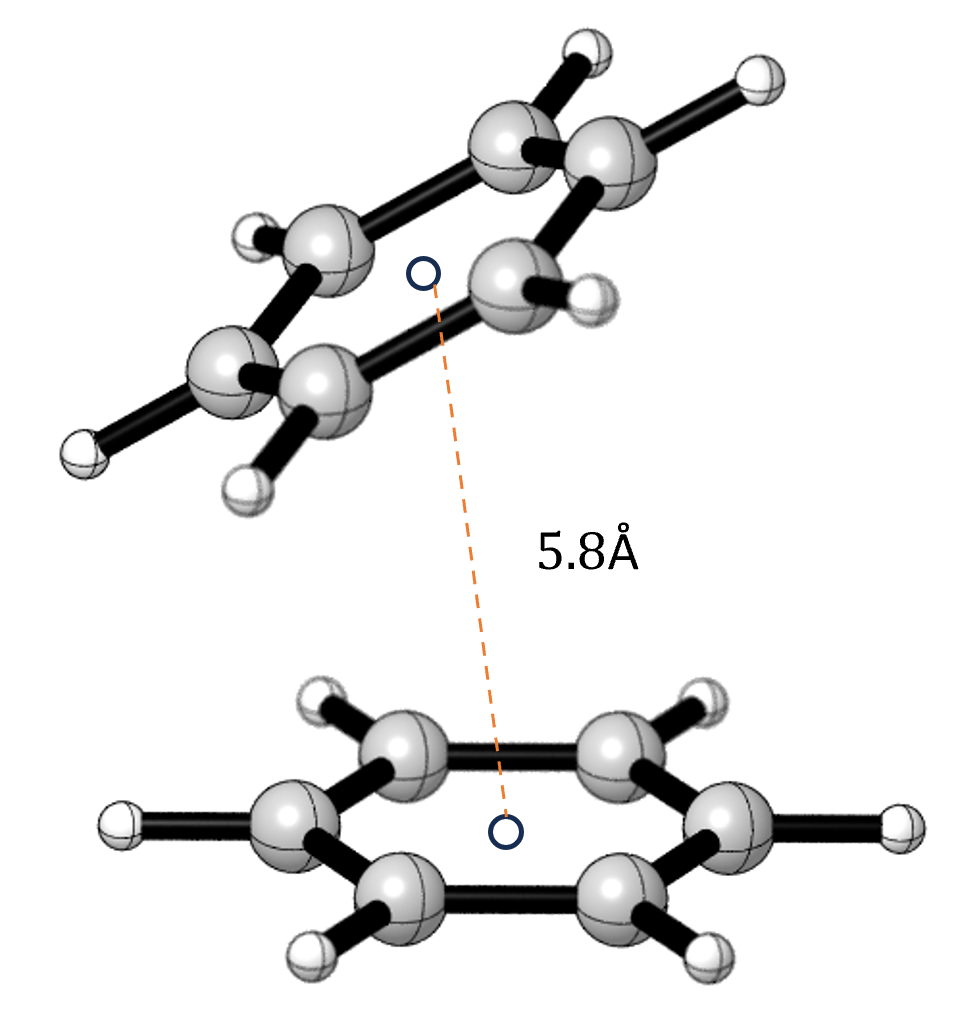
Раскрытие Роли Нековалентных Взаимодействий
Phi-former, благодаря явному моделированию взаимодействий на различных уровнях, позволяет получить глубокое понимание роли специфических нековалентных связей, в частности, π-π взаимодействий. Данный подход выходит за рамки упрощенных моделей, учитывая тонкости электронных и пространственных эффектов, определяющих стабильность и специфичность связывания молекул. Это особенно важно, поскольку π-π взаимодействия часто играют ключевую роль в процессах молекулярного распознавания, формировании белковых комплексов и, следовательно, в эффективности лекарственных препаратов. Исследование этих взаимодействий с помощью Phi-former предоставляет ценные данные для разработки более эффективных и целенаправленных лекарственных средств, учитывающих тонкие детали молекулярного взаимодействия.
Понимание нековалентных взаимодействий имеет решающее значение для рационального дизайна лекарственных препаратов и оптимизации кандидатов в лекарства. Эти взаимодействия, включающие силы притяжения и отталкивания между молекулами, определяют, как лекарственное средство связывается с целевой биологической молекулой, такой как белок. Точное предсказание силы и специфичности этих взаимодействий позволяет исследователям разрабатывать препараты с повышенной эффективностью и сниженными побочными эффектами. Оптимизация структуры молекулы лекарственного средства с учетом этих взаимодействий позволяет улучшить её фармакокинетические и фармакодинамические свойства, обеспечивая более целенаправленную доставку и усиление терапевтического эффекта. Таким образом, глубокое понимание нековалентных взаимодействий является краеугольным камнем современной разработки лекарственных препаратов, способствуя созданию более безопасных и эффективных методов лечения.
Разработанная модель Phi-former демонстрирует значительно улучшенные предсказательные способности в области поиска лекарственных средств, что подтверждается результатами тестирования на наборе данных PDBBind 2019. Достигнутое значение среднеквадратичной ошибки (RMSE) в 1.159 и коэффициент корреляции Пирсона 0.846 свидетельствуют о высокой точности предсказания связывающей энергии между потенциальными лекарственными кандидатами и их мишенями. Повышенная точность модели позволяет значительно ускорить процесс разработки новых препаратов, сократив время и затраты, связанные с традиционными методами скрининга и оптимизации молекул. Это, в свою очередь, открывает возможности для более быстрого вывода на рынок инновационных лекарств и снижения их стоимости для пациентов.
Представленная работа демонстрирует стремление к математической чистоте в предсказании взаимодействий между соединениями и белками. Разработчики Phi-Former, используя иерархическое моделирование и предварительное обучение, стремятся к созданию алгоритма, который не просто ‘работает на тестах’, а обладает внутренней доказательностью. Как однажды заметил Тим Бернерс-Ли: «Данные должны быть свободны и доступны для всех». Этот принцип находит отражение в стремлении к созданию прозрачных и обоснованных моделей, способных точно предсказывать сложные биологические взаимодействия, что особенно важно для разработки новых лекарственных препаратов. Иерархическое представление, используемое в Phi-Former, позволяет разложить сложную задачу на более простые, поддающиеся строгому анализу и проверке, что соответствует принципам элегантности и корректности алгоритма.
Куда же дальше?
Представленный Phi-Former, несомненно, демонстрирует прогресс в предсказании взаимодействий между соединениями и белками. Однако, истинная элегантность алгоритма заключается не в достижении новых рекордов точности на текущих наборах данных, а в его способности к обобщению. Текущая архитектура, основанная на иерархическом представлении и предварительном обучении, всё же страдает от присущей глубокому обучению проблемы — зависимости от объёма и качества размеченных данных. Вопрос в том, насколько устойчива эта модель к изменениям в химическом пространстве, к новым классам соединений и белков, не представленных в обучающей выборке.
Дальнейшие исследования должны быть направлены на разработку методов, позволяющих уменьшить эту зависимость. В частности, представляется перспективным исследование возможностей включения априорных знаний о физико-химических свойствах соединений и белков непосредственно в архитектуру модели, возможно, через разработку инвариантных представлений. Следует также обратить внимание на алгоритмы активного обучения, позволяющие эффективно выбирать наиболее информативные образцы для разметки, сокращая тем самым объём необходимых данных. И, конечно, необходимо помнить о вычислительной сложности: асимптотическое поведение подобных моделей при увеличении размера молекул и белков требует тщательного анализа.
В конечном счёте, предсказание взаимодействий — это лишь промежуточный шаг. Истинная цель — не просто определить, взаимодействуют ли два объекта, а понять как они взаимодействуют. Построение моделей, способных предсказывать аффинность связывания, энергию взаимодействия и даже структуру комплекса, остаётся сложной, но необходимой задачей. И только в этом случае можно будет говорить о подлинном прогрессе в области компьютерной химии и биологии.
Оригинал статьи: https://arxiv.org/pdf/2602.05479.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Графы и действия: новый подход к планированию для роботов
- Bibby AI: Новый помощник для исследователей в LaTeX
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Квантовые амбиции: Иран вступает в гонку
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Федеративное обучение: баланс между конфиденциальностью и скоростью
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-07 10:41