Автор: Денис Аветисян
Новый подход позволяет задавать вопросы о данных временных рядов на естественном языке, объединяя возможности поиска в базе данных и проверки с помощью программного кода.
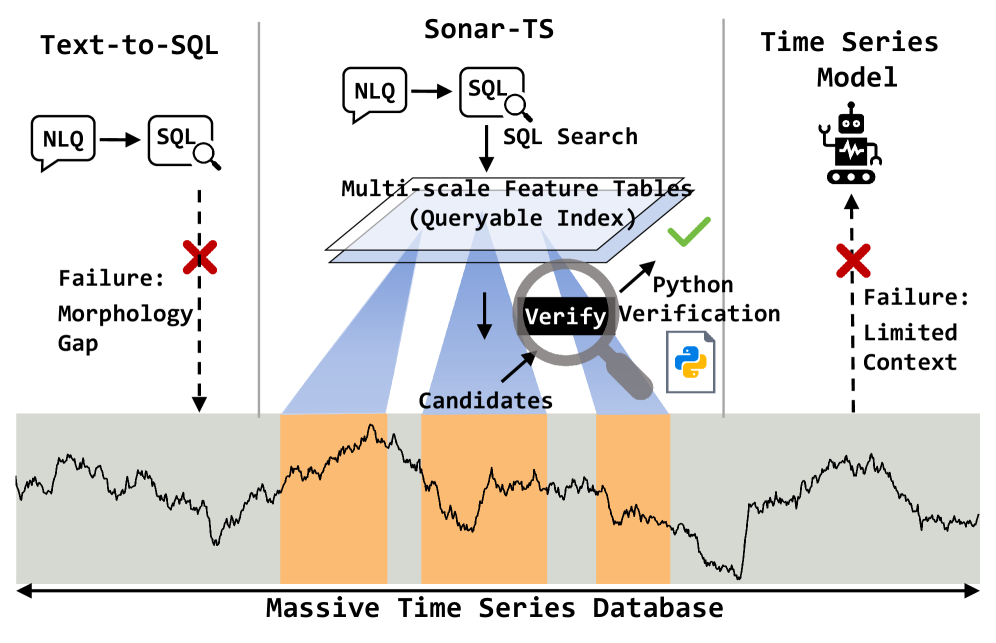
Представлена задача NLQ4TSDB и нейро-символическая система Sonar-TS для запросов к базам данных временных рядов.
Несмотря на растущий объем данных временных рядов, извлечение значимой информации из них с помощью естественного языка остается сложной задачей. В данной работе, посвященной задаче ‘Sonar-TS: Search-Then-Verify Natural Language Querying for Time Series Databases’, предложен нейро-символический фреймворк Sonar-TS, использующий конвейер «Поиск-Проверка» для обработки запросов на естественном языке к базам данных временных рядов. Этот подход объединяет поиск по базе данных с верификацией результатов с помощью программ на Python, позволяя эффективно находить закономерности и аномалии в больших объемах данных. Может ли предложенный фреймворк и новый бенчмарк NLQTSBench стать основой для дальнейших исследований в области интеллектуального анализа данных временных рядов?
Разрушая границы: вызов естественного языка для анализа временных рядов
Традиционные подходы к обработке естественного языка для анализа временных рядов, такие как Text-to-SQL и Time Series Question Answering (TSQA), зачастую оказываются неэффективными при работе со сложными запросами. Эти методы испытывают трудности в интерпретации нюансов, заложенных в человеческой речи, особенно когда речь идет о временных зависимостях и морфологических особенностях данных. Неспособность адекватно понимать контекст и сложные отношения между переменными во времени приводит к неточным результатам и требует значительных усилий по предварительной обработке запросов. Проблемы возникают как при формулировании запросов на естественном языке, так и при их преобразовании в исполняемые запросы к базам данных временных рядов, что подчеркивает необходимость разработки более совершенных методов, способных к глубокому семантическому пониманию.
Традиционные методы обработки естественного языка, применяемые к анализу временных рядов, зачастую сталкиваются с трудностями в интерпретации тонких временных взаимосвязей и морфологических особенностей, характерных для реальных данных. Например, фразы, описывающие тренды (“резкий рост”, “плавное снижение”) или паттерны (“сезонные колебания”, “циклические изменения”), требуют не просто сопоставления ключевых слов, но и понимания контекста и временной шкалы. Более того, обработка таких понятий, как «перед», «после», «во время» или «в течение», требует глубокого семантического анализа и учета гранулярности временных рядов. Неспособность адекватно уловить эти нюансы приводит к неточным ответам на запросы и ограничивает возможности полноценного анализа данных, что подчеркивает необходимость разработки более совершенных методов.
Для эффективной работы с базами данных временных рядов (TSDB) посредством естественного языка недостаточно простого перевода запроса. Необходим глубокий семантический анализ, позволяющий системе не только распознать ключевые слова, но и понять контекст, временные взаимосвязи и скрытые значения, заключенные в формулировке вопроса. Простое сопоставление слов с командами SQL не позволяет учесть нюансы, такие как определение относительных периодов времени («на прошлой неделе»), понимание морфологических особенностей данных временных рядов и интерпретацию сложных запросов, требующих агрегации и фильтрации. Именно поэтому успешная обработка естественного языка для TSDB требует от системы способности к извлечению смысла и построению логических выводов, аналогичных человеческому пониманию.
Ограничения существующих методов запроса к базам данных временных рядов (TSDB) подчеркивают необходимость принципиально новой парадигмы — NLQ4TSDB. Традиционные подходы, основанные на преобразовании естественного языка в SQL-запросы или попытки ответа на вопросы о временных рядах, часто оказываются неспособны корректно интерпретировать сложные временные взаимосвязи и морфологические особенности, присущие реальным данным. Вместо простого перевода запроса, требуется глубокое семантическое понимание, позволяющее учитывать контекст, тенденции и аномалии во временных рядах. NLQ4TSDB предполагает создание систем, способных не только понимать запрос на естественном языке, но и самостоятельно строить эффективные запросы к TSDB, учитывая специфику данных и требуемый уровень детализации. Такой подход позволит значительно упростить анализ временных рядов для широкого круга пользователей, не обладающих навыками программирования или работы с SQL.
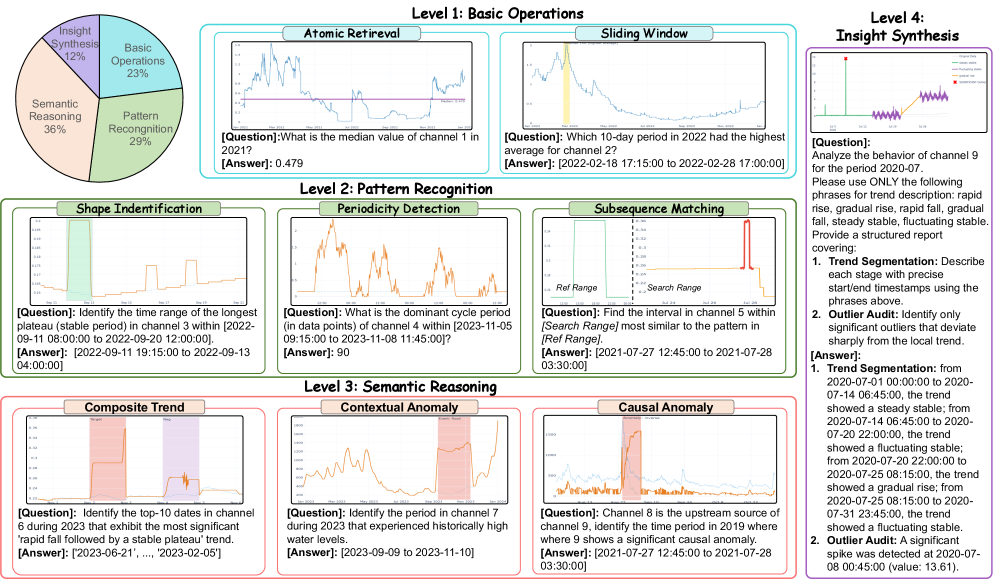
Иерархический подход к оценке: NLQTSBench
NLQTSBench представляет собой комплексный эталонный набор данных, предназначенный для оценки систем NLQ4TSDB (Natural Language Querying for Time Series Databases). Он включает в себя задачи различной сложности, охватывающие широкий спектр сценариев запросов к временным рядам. В отличие от существующих эталонов, NLQTSBench не ограничивается простыми операциями поиска, а включает в себя задачи, требующие распознавания закономерностей, семантического рассуждения и синтеза информации. Такая иерархическая структура позволяет проводить детальную оценку возможностей различных систем, выявляя их сильные и слабые стороны в различных аспектах обработки естественного языка и анализа временных рядов. Комплексность задач в NLQTSBench обеспечивает более реалистичную оценку производительности систем в практических приложениях.
Иерархическая структура NLQTSBench, включающая уровни от 1 (Базовые операции) до 4 (Синтез информации), обеспечивает детальную оценку возможностей систем NLQ4TSDB. Каждый уровень предназначен для проверки конкретного аспекта функциональности: от выполнения простых запросов к данным временных рядов на уровне 1, до анализа сложных паттернов и логических связей на уровнях 2 и 3, и, наконец, до генерации осмысленных выводов и синтеза информации на уровне 4. Такая структура позволяет точно определить сильные и слабые стороны различных систем, выявляя области, требующие улучшения, и обеспечивая объективное сравнение их производительности в различных сценариях анализа данных временных рядов.
Задачи второго уровня в NLQTSBench направлены на оценку способности систем распознавать закономерности во временных рядах, а именно — сопоставлять морфологические концепции с данными. В рамках этих задач система Sonar-TS продемонстрировала значительное улучшение метрики Intersection over Union (IoU) по сравнению с базовыми методами. IoU измеряет степень перекрытия между предсказанными и фактическими интервалами, что позволяет количественно оценить точность распознавания шаблонов во временных данных. Улучшение метрики IoU указывает на более эффективное сопоставление морфологических признаков с конкретными интервалами времени в рядах.
Задачи уровня 3 в NLQTSBench предназначены для оценки семантического рассуждения систем, что подразумевает необходимость комбинирования логических операций и понимания взаимосвязей в данных временных рядов. Эти задачи требуют от системы не просто идентификации паттернов, но и построения сложных запросов, учитывающих, например, условия «больше чем», «меньше чем», или «равно». Оценка проводится на основе способности системы правильно интерпретировать запросы, содержащие логические связки, такие как «И», «ИЛИ», и «НЕ», применительно к временным рядам, что демонстрирует уровень понимания семантики данных, а не только синтаксического анализа запроса.
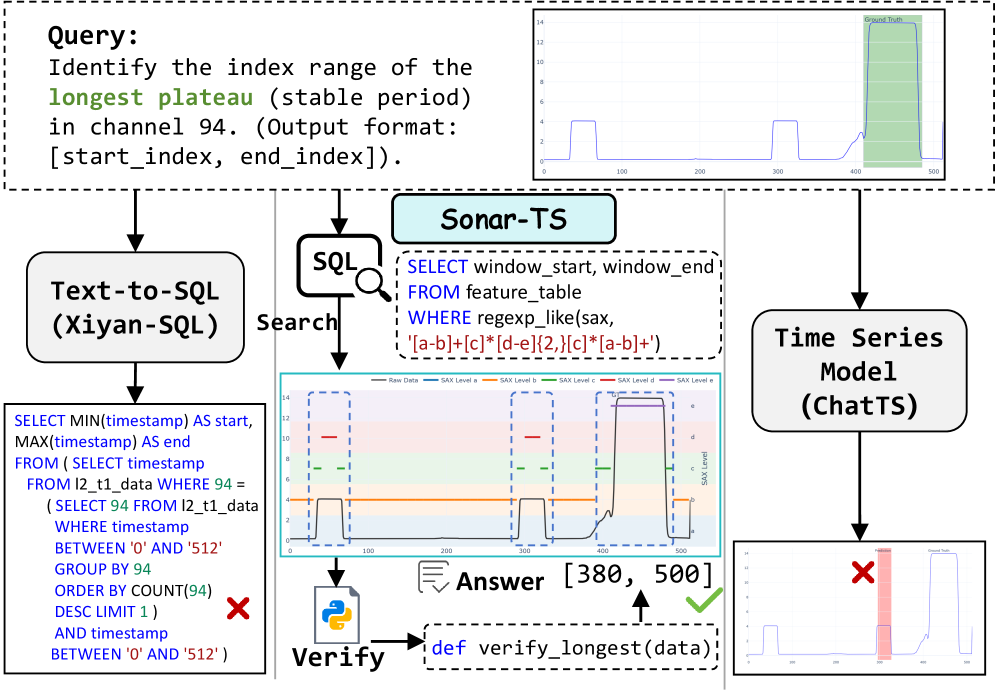
Sonar-TS: Нейро-символический подход к верификации
Sonar-TS представляет собой новый нейро-символический фреймворк для задачи NLQ4TSDB (Natural Language Querying for Time Series Databases). В его основе лежит конвейер “Поиск-Затем-Проверка” (Search-Then-Verify), который позволяет повысить точность и надежность ответов на запросы на естественном языке. На первом этапе конвейера выполняется поиск кандидатов на основе SQL-запросов к базе данных временных рядов. Далее, полученные данные подвергаются проверке с использованием Python-скриптов, работающих непосредственно с необработанными данными. Такой двухэтапный подход позволяет отфильтровать неверные результаты, полученные на этапе поиска, и обеспечить более высокую точность ответа.
В основе системы Sonar-TS лежит конвейер “Поиск-Затем-Проверка”, использующий SQL для первоначального извлечения кандидатов из базы данных временных рядов. Извлеченные данные затем подвергаются верификации с использованием Python, работающего непосредственно с сырыми данными. Такой двухэтапный подход позволяет повысить точность и надежность ответов на запросы на естественном языке (NLQ4TSDB) за счет фильтрации нерелевантных результатов, полученных на этапе SQL-поиска, и более детального анализа на этапе верификации с использованием Python. Это позволяет системе эффективно обрабатывать сложные запросы и минимизировать количество ложных срабатываний.
Эффективность конвейера «Поиск-Проверка» в Sonar-TS обеспечивается использованием Таблиц Признаков, содержащих предварительно вычисленные статистические сводки и морфологические сигнатуры. Эти таблицы позволяют значительно ускорить процесс поиска релевантных данных, поскольку статистические сводки предоставляют агрегированную информацию о данных, а морфологические сигнатуры — компактное представление временных рядов. Предварительное вычисление этих признаков снижает вычислительную нагрузку во время выполнения запроса, позволяя системе быстро идентифицировать и извлекать наиболее вероятные кандидаты для последующей верификации на основе исходных данных. Использование Таблиц Признаков является ключевым фактором, обеспечивающим масштабируемость и производительность системы Sonar-TS при работе с большими объемами данных временных рядов.
В основе повышения точности на задачах первого уровня в Sonar-TS лежит использование Symbolic Aggregate approXimation (SAX) в составе Feature Tables. SAX представляет собой метод, позволяющий сжимать временные ряды данных, сохраняя при этом их характерные особенности. В рамках Sonar-TS, SAX применяется для генерации компактных «сигнатур» из сырых данных временных рядов, хранящихся в Feature Tables. Эти сигнатуры значительно ускоряют процесс сопоставления паттернов и поиска релевантных данных, поскольку сравнение коротких SAX-представлений требует значительно меньше вычислительных ресурсов, чем работа с полными временными рядами. Эффективность SAX обусловлена его способностью к представлению данных в виде дискретных символов, что позволяет использовать алгоритмы быстрого поиска и сравнения строк для выявления соответствий.
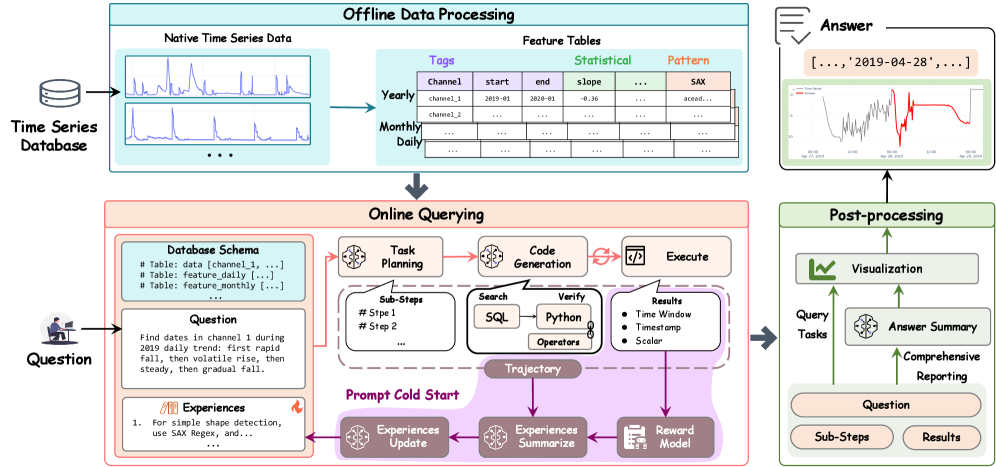
Оркестрация и извлечение инсайтов: роль LLM и обобщение опыта
Система Sonar-TS использует планировщик на базе больших языковых моделей (LLM) для преобразования сложных запросов, сформулированных на естественном языке, в последовательность исполняемых операций. Этот подход позволяет существенно упростить процесс обработки запросов, поскольку LLM способна анализировать смысл вопроса и автоматически разбивать его на более простые, атомарные шаги. Вместо того, чтобы требовать от пользователя знания специфического синтаксиса или структуры данных, система интерпретирует намерение, выраженное в запросе, и генерирует план выполнения, который затем используется для извлечения и анализа информации из временных рядов. Такой механизм значительно расширяет возможности взаимодействия с данными, делая анализ доступным для более широкого круга пользователей и позволяя решать сложные аналитические задачи с высокой степенью автоматизации.
Для обеспечения точных математических вычислений над временными рядами на этапе верификации, система Sonar-TS использует специализированные операторы верификации. Эти операторы представляют собой атомарные функции, разработанные для выполнения конкретных задач, таких как расчет статистических показателей \mu, \sigma (среднего и стандартного отклонения), выявление трендов, обнаружение аномалий и проведение сложных вычислений на основе временных интервалов. Их применение позволяет избежать неоднозначности и ошибок, которые могут возникнуть при использовании общих математических библиотек, и гарантирует высокую точность результатов, необходимых для надежного анализа данных и принятия обоснованных решений. Такая модульная архитектура также способствует масштабируемости и упрощает добавление новых типов вычислений в будущем.
В системе Sonar-TS реализован компонент, именуемый “Обобщитель Опыта”, который анализирует следы выполнения запросов и извлекает из них ценные технические знания. Этот процесс позволяет не просто фиксировать результаты, но и выявлять закономерности, оптимизировать стратегии поиска и верификации, а также накапливать опыт для последующих запросов. Благодаря этому, система способна к самообучению и постоянному улучшению своей производительности, поскольку извлеченные знания повторно используются для повышения точности и эффективности обработки временных рядов. Фактически, “Обобщитель Опыта” функционирует как механизм неявного программирования, позволяющий системе адаптироваться к новым задачам и требованиям без прямого вмешательства человека.
Система демонстрирует способность к синтезу знаний и генерации комплексных отчетов, что подтверждается результатами выполнения задач четвертого уровня. В рамках этих задач система не просто обрабатывает данные временных рядов, но и формирует целостные аналитические сводки, предоставляя пользователю не только цифры, но и осмысленные выводы, пригодные для принятия решений. Оценка эффективности данной способности, основанная на структурированном формировании отчетов, показывает достижение комбинированной метрики F1-score, что свидетельствует о высокой точности и полноте сгенерированных аналитических материалов. Таким образом, система способна трансформировать сырые данные во ценную информацию, существенно облегчая процесс анализа и позволяя оперативно реагировать на изменения в динамике временных рядов.
Исследование, представленное в статье, демонстрирует стремление к преодолению ограничений существующих систем запросов к базам данных временных рядов. Авторы предлагают не просто интерпретировать естественный язык, но и верифицировать полученные результаты, используя возможности Python. Этот подход напоминает о словах Карла Фридриха Гаусса: «Если бы я мог объяснить, как я это сделал, то я бы не был волшебником». Ведь суть в том, чтобы не просто найти ответ, а убедиться в его корректности, как бы разобрать механизм, чтобы удостовериться в его работоспособности. Sonar-TS, как нейро-символическая система, стремится к этой прозрачности, позволяя удостовериться в логике, лежащей в основе ответа, что является важным шагом к созданию действительно надежных систем анализа данных временных рядов.
Что дальше?
Представленная работа, хоть и демонстрирует прогресс в области запросов к временным рядам на естественном языке, лишь обнажает глубину нерешенных проблем. Система, комбинирующая поиск в базе данных с верификацией на Python, — элегантное решение, но оно неизбежно наталкивается на фундаментальное ограничение: каждое исправление — это философское признание несовершенства исходной модели. По сути, система не столько “понимает” запрос, сколько ловко обходит его потенциальные двусмысленности.
Будущие исследования, вероятно, сконцентрируются на преодолении этой границы. Необходима разработка более устойчивых к неоднозначности методов, способных не просто находить “правильный” ответ, но и понимать почему этот ответ верен. Вместо слепой верификации требуется способность к генерации объяснений, к построению внутренней модели данных и логики запроса. В конечном итоге, задача сводится к созданию системы, способной к саморефлексии, к оценке собственной уверенности в ответе.
Возможно, истинный прогресс заключается не в совершенствовании алгоритмов, а в осознании того, как всё работает. И тогда лучший хак — это осознанность того, что каждая база данных, каждый запрос, каждый ответ — это лишь приближение к истине, ограниченное нашим пониманием и возможностями инструментов. А каждый “патч” — всего лишь признание этой хрупкости.
Оригинал статьи: https://arxiv.org/pdf/2602.17001.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
- Квантовый скачок: от лаборатории к рынку
2026-02-22 16:02