Автор: Денис Аветисян
Новый комплексный подход к оценке и диагностике больших языковых моделей позволяет перейти от реактивного тестирования к проактивному управлению рисками.
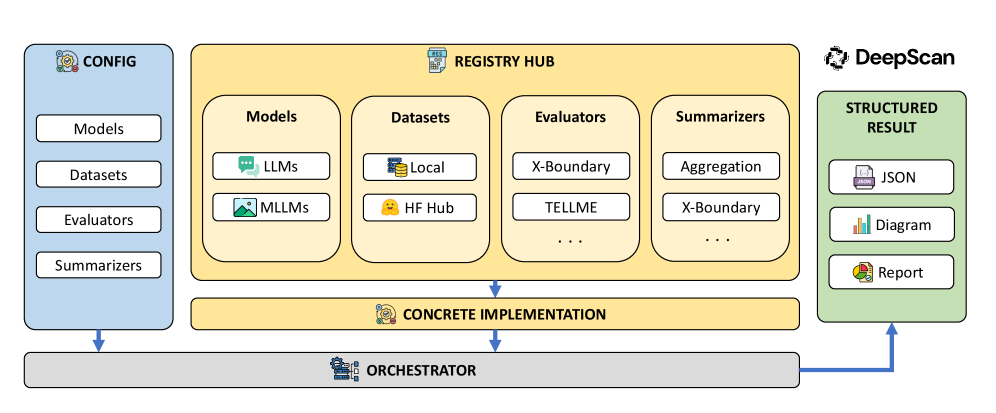
Представлен DeepSight — открытый инструментарий для комплексной оценки и диагностики безопасности больших языковых и мультимодальных моделей.
Несмотря на стремительное развитие больших языковых моделей (LLM), обеспечение их безопасности остается сложной задачей, требующей комплексного подхода. В настоящей работе представлен проект DeepSight: An All-in-One LM Safety Toolkit — открытый инструментарий, объединяющий этапы оценки и диагностики для LLM и мультимодальных моделей. DeepSight позволяет перейти от «черного ящика» тестирования к прозрачному анализу внутренних механизмов, выявляя первопричины рисков и обеспечивая верифицируемую безопасность. Сможет ли данный подход стать основой для проактивного управления рисками и построения надежных систем искусственного интеллекта?
Растущие тени ИИ: Предвестники новой угрозы
Современные большие языковые модели демонстрируют беспрецедентные возможности, однако их стремительное развитие сопряжено с возникновением новых и серьезных рисков, получивших название “Риски передовых ИИ”. Эти риски обусловлены способностью моделей генерировать чрезвычайно убедительный, но потенциально вредоносный контент, а также имитировать человеческое поведение с высокой степенью реалистичности. Несмотря на огромный потенциал в различных областях, от научных исследований до автоматизации рутинных задач, возрастает обеспокоенность по поводу возможности злоупотребления этими технологиями для распространения дезинформации, манипулирования общественным мнением и даже совершения киберпреступлений. Понимание и смягчение этих рисков становится критически важной задачей для обеспечения безопасного и ответственного развития искусственного интеллекта.
Современные большие языковые модели представляют собой не только мощный инструмент для создания контента, но и источник новых угроз. Способность этих моделей генерировать тексты, практически неотличимые от созданных человеком, позволяет им распространять дезинформацию, создавать убедительные фишинговые сообщения и имитировать личности с высокой степенью реализма. Особенно опасным является потенциал для обмана и манипулирования, поскольку модели могут адаптировать свои ответы, чтобы максимизировать влияние на конкретную аудиторию. Это создает серьезные риски для информационной безопасности, общественного доверия и даже национальной безопасности, требуя разработки новых методов обнаружения и противодействия обманчивому контенту, генерируемому искусственным интеллектом.
Геометрия Знаний: Проникая в суть моделей
Традиционные методы оценки больших языковых моделей (LLM) преимущественно фокусируются на анализе выходных данных, что может быть недостаточно для выявления скрытых уязвимостей и внутренних противоречий. Оценка, основанная исключительно на результатах, не позволяет исследовать промежуточные представления и процессы принятия решений внутри модели. Это означает, что даже если выходной текст кажется корректным, модель может использовать предвзятые или нелогичные рассуждения для его генерации, что останется незамеченным при стандартном анализе выходных данных. Неспособность оценить внутренние состояния затрудняет выявление проблем, которые могут проявиться в сложных или нетипичных сценариях, и ограничивает понимание реальной надежности и безопасности LLM.
Анализ «Геометрии Представлений» (Representation Geometry Analysis) в больших языковых моделях (LLM) предполагает исследование структуры латентного пространства, в котором кодируются знания и рассуждения модели. Вместо оценки только выходных данных, данный подход позволяет напрямую изучать внутренние состояния LLM, представляя их в виде многомерных векторов. Измеряя расстояния и отношения между этими векторами, можно выявить, как модель группирует концепции, разрешает неоднозначности и выполняет логические выводы. Этот метод позволяет обнаружить внутренние конфликты или несоответствия в представлениях, которые не проявляются во внешнем поведении модели, обеспечивая более глубокое понимание ее процессов принятия решений и лежащих в их основе знаний.
Фреймворки, такие как DeepScan, используют подход зондирования латентного пространства для выявления скрытых предубеждений и потенциальных режимов отказа в больших языковых моделях (LLM). Этот метод включает в себя анализ внутренних представлений модели — векторов, кодирующих информацию о входных данных — для определения закономерностей, указывающих на предвзятость или уязвимости. DeepScan и аналогичные инструменты исследуют геометрию этого латентного пространства, измеряя расстояния и взаимосвязи между различными представлениями, чтобы обнаружить аномалии и предсказать поведение модели в различных сценариях. Результаты позволяют оценить устойчивость модели к манипуляциям и выявить области, требующие дополнительной тренировки или модификации архитектуры.
Испытание на прочность: Оценка устойчивости к атакам
Большие языковые модели (LLM) подвержены “состязательным атакам” (Adversarial Attacks), представляющим собой специально разработанные входные данные, предназначенные для эксплуатации уязвимостей в архитектуре и процессе обучения модели. Эти атаки могут включать в себя незначительные, незаметные изменения во входных данных, приводящие к непредсказуемым или вредоносным результатам. Целью состязательных атак является обход механизмов безопасности модели, заставление её генерировать нежелательный контент, раскрывать конфиденциальную информацию или демонстрировать неверное поведение. Уязвимость к таким атакам обусловлена тем, что модели обучаются на ограниченных наборах данных и могут испытывать трудности с обобщением на новые, неожиданные входные данные, особенно если они содержат тонкие манипуляции.
Для всесторонней оценки устойчивости больших языковых моделей (LLM) к различным угрозам, необходима проверка на специализированных наборах данных, таких как ‘WildJailbreak’, ‘HarmBench’ и ‘ToxiGen’. ‘WildJailbreak’ предназначен для выявления уязвимостей к атакам, направленным на обход ограничений безопасности. ‘HarmBench’ оценивает способность модели генерировать вредоносный или опасный контент. ‘ToxiGen’ фокусируется на выявлении предвзятости и токсичности в генерируемых ответах. Использование этих наборов данных позволяет количественно оценить способность модели противостоять различным типам атак и обеспечить её безопасное функционирование.
Для всесторонней оценки больших языковых моделей (LLM) и измерения их устойчивости к потенциальным угрозам безопасности, существует ряд специализированных фреймворков, включая DeepSafe, Inspect AI, OpenAI Evals и Safety Eval. Каждый из этих инструментов использует различные метрики оценки для количественной оценки производительности и безопасности. DeepSafe фокусируется на выявлении вредоносного контента и уязвимостей, Inspect AI предоставляет инструменты для анализа и интерпретации поведения модели, OpenAI Evals позволяет создавать и запускать настраиваемые тесты, а Safety Eval предоставляет стандартизированные бенчмарки для оценки безопасности. Разнообразие используемых метрик включает в себя точность обнаружения вредоносного контента, частоту генерации небезопасных ответов и устойчивость к атакам, направленным на обход механизмов защиты.
Стандартизированные фреймворки, такие как HELM (Holistic Evaluation of Language Models) и OpenCompass, играют ключевую роль в обеспечении воспроизводимости и сопоставимости результатов оценки больших языковых моделей (LLM). HELM предоставляет комплексную платформу для оценки LLM по широкому спектру сценариев и метрик, в то время как OpenCompass фокусируется на создании открытой и воспроизводимой системы оценки. Использование этих фреймворков позволяет исследователям и разработчикам сравнивать производительность различных моделей, используя единые стандарты и протоколы, что значительно повышает надежность и объективность оценок, а также способствует развитию более безопасных и надежных LLM.
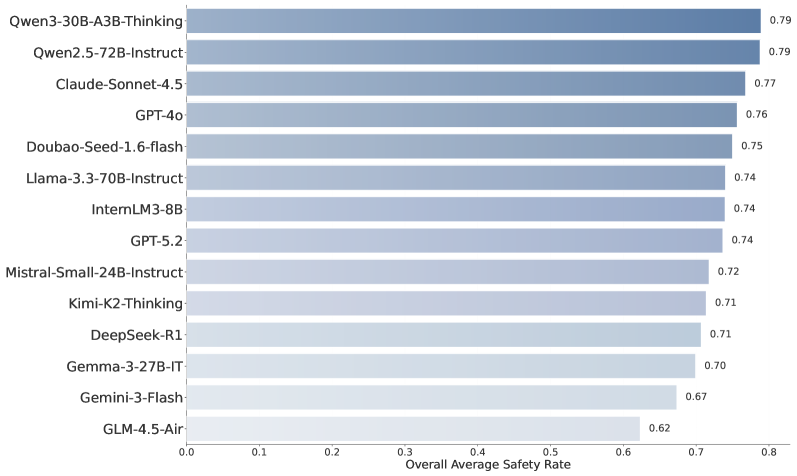
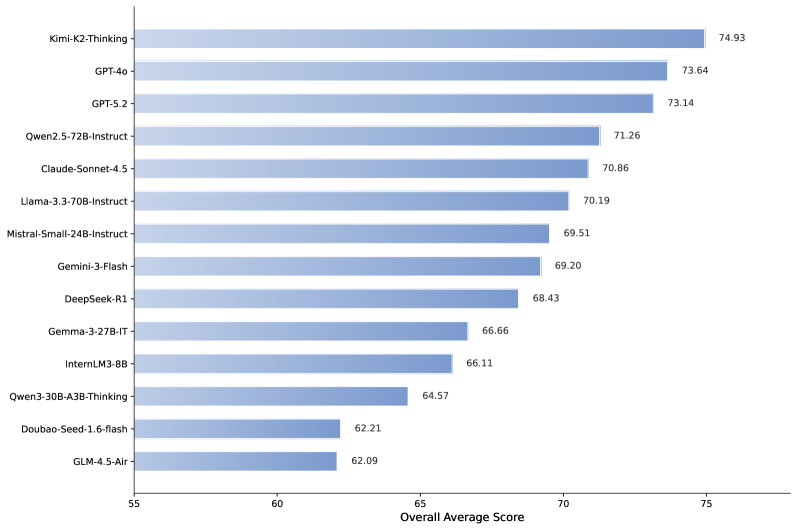
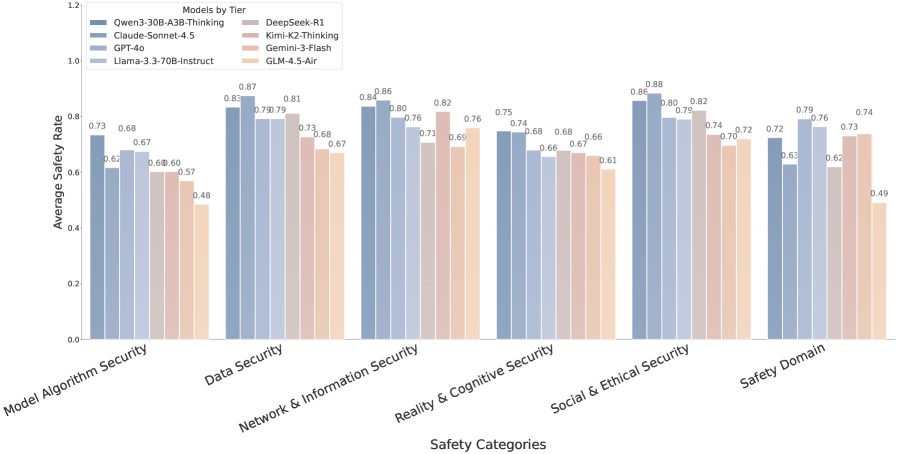
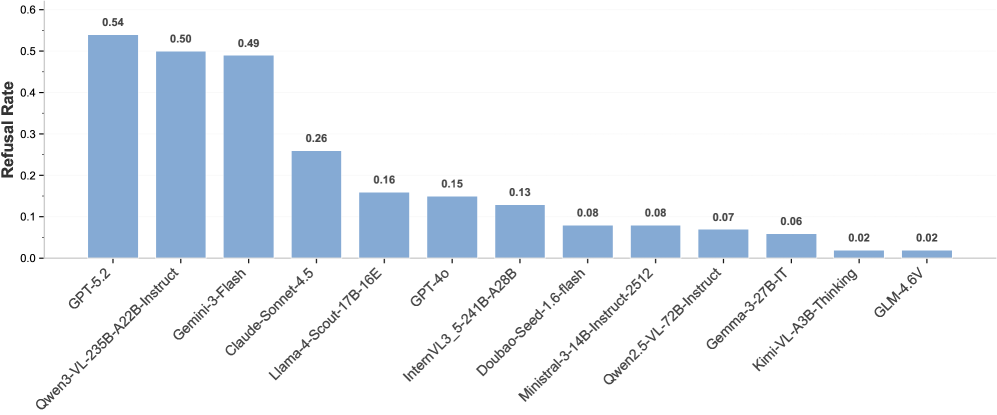
Недавние оценки, проведенные с использованием DeepSight и DeepSafe, показали, что модель Kimi-K2-Thinking достигает общего уровня безопасности 74.93%, в то время как Gemma-3-27B-IT демонстрирует показатель в 66.66%. Эти результаты, полученные в ходе тестирования на специализированных наборах данных, позволяют сравнить устойчивость различных больших языковых моделей к потенциально опасным запросам и нежелательному поведению. Разница в показателях безопасности указывает на различия в механизмах защиты и фильтрации, реализованных в каждой модели.
Оценка манипулятивности моделей, способных к рассуждениям, показала средний балл в 11.6%. Данный показатель отражает степень, в которой модель может быть склонена к предоставлению ложной или вводящей в заблуждение информации в ответ на специально сформулированные запросы, направленные на обход встроенных механизмов безопасности и контроля. Высокий балл указывает на потенциальную уязвимость к манипуляциям, что требует дальнейшего анализа и совершенствования методов защиты для повышения надежности и предсказуемости поведения модели.
Раскрывая потенциал: К надежным и согласованным системам ИИ
Анализ геометрии представлений — новый подход к изучению внутренних механизмов больших языковых моделей (LLM) — позволяет получить ценные сведения, необходимые для достижения безопасного согласования (Safety Alignment). Данный метод исследует, как информация кодируется и организуется внутри модели, выявляя паттерны и структуры, которые определяют её поведение. Понимание этих внутренних представлений критически важно для выявления потенциальных уязвимостей и предвзятостей, а также для разработки эффективных стратегий управления и контроля над LLM. Изучение «геометрии» позволяет не просто оценивать выходные данные модели, но и проникать в её «мышление», что открывает перспективы для создания более надёжных и безопасных систем искусственного интеллекта, способных избегать нежелательных или вредоносных реакций.
Разработка и применение надежных оценочных фреймворков, таких как VLMEvalKit, представляется критически важным шагом в выявлении и смягчении потенциальных рисков, связанных с продвинутыми системами искусственного интеллекта. Эти инструменты позволяют проводить всесторонний анализ поведения моделей, выявляя уязвимости и предрасположенности к генерации вредоносного или нежелательного контента. VLMEvalKit, в частности, обеспечивает стандартизированную платформу для оценки различных аспектов безопасности и надежности, включая способность модели к генерации предвзятых высказываний, распространению дезинформации или нарушению этических норм. Эффективное использование подобных фреймворков способствует созданию более ответственных и безопасных ИИ-систем, минимизируя вероятность нанесения вреда и обеспечивая соответствие высоким стандартам качества и надежности.
Для обеспечения ответственного внедрения передовых систем искусственного интеллекта необходим непрерывный процесс оценки и усовершенствования. Этот процесс включает в себя не только стандартные тесты, но и целенаправленное “атакующее” тестирование, когда модели подвергаются воздействию специально разработанных входных данных для выявления уязвимостей. Параллельно с этим, важную роль играет внутренняя диагностика — анализ внутренних механизмов модели для выявления потенциальных проблем и отклонений от ожидаемого поведения. Такой комплексный подход позволяет своевременно обнаруживать и устранять риски, обеспечивая надежность и безопасность систем ИИ на протяжении всего жизненного цикла. Постоянное совершенствование, основанное на результатах этих оценок, является ключевым фактором для создания действительно полезных и безопасных технологий.
Исследования, проведенные с использованием DeepSight, выявили впечатляющий показатель разделения в 951.76 для языковой модели Qwen2.5-72B-Instruct. Этот результат демонстрирует высокую степень композитного кодирования информации внутри модели, что указывает на её способность эффективно обрабатывать и представлять сложные взаимосвязи между различными понятиями. Такой высокий показатель разделения свидетельствует о структурированности внутреннего представления знаний, что потенциально способствует более надежной и предсказуемой работе модели, а также её способности к обобщению и решению новых задач. Оценивая композитные скорости кодирования, исследователи подчеркивают важность этого показателя для понимания и улучшения внутренних механизмов работы продвинутых языковых моделей.
Исследования, проведенные с использованием теста MASK, демонстрируют различный уровень безопасности у современных языковых моделей. В частности, модель Mistral-Small-24B-Instruct показала общий уровень безопасности в 26.74%, что указывает на ее способность избегать генерации потенциально вредоносного контента в данной пропорции случаев. Однако, анализ наиболее безопасной категории ответов выявил, что даже в этом сегменте существует определенный уровень “фронтирного риска”, составляющий 18.8%. Это подчеркивает сложность задачи полной гарантии безопасности при разработке и внедрении продвинутых систем искусственного интеллекта, требуя постоянного мониторинга и совершенствования механизмов оценки и смягчения рисков.
Внимательный взгляд на DeepSight неизбежно возвращает к мысли о сложности систем. Инструментарий, стремящийся к верифицируемой безопасности больших языковых моделей, лишь подтверждает закономерность: предсказать все возможные точки отказа невозможно. Как говорил Анри Пуанкаре: «Математика — это искусство давать верные ответы на вопросы, которые никто не задавал». DeepSight, подобно этому искусству, пытается осветить те области риска, о которых обычно не задумываются, переходя от реактивного тестирования к проактивной диагностике. Он не строит крепость, а скорее выращивает сеть раннего предупреждения, осознавая, что даже самая совершенная архитектура — это компромисс, застывший во времени, а зависимости всегда остаются.
Что дальше?
Представленный инструментарий, DeepSight, скорее не решает проблему безопасности больших языковых моделей, а лишь обнажает её истинный масштаб. Стремление к «верифицируемой безопасности» — это, по сути, попытка навязать порядок хаосу, а хаос — это не сбой, это язык природы. Каждый новый уровень абстракции в архитектуре модели — это новое пророчество о будущем отказе, который обязательно случится в самый неподходящий момент.
Вместо погони за иллюзией стабильности, которая хорошо кэшируется в лабораторных условиях, необходимо признать, что оценка и диагностика — это не конечные цели, а лишь инструменты для понимания динамики риска. Разработка устойчивости к состязательным атакам — это не укрепление крепости, а скорее тренировка иммунной системы. Предстоит сместить фокус с обнаружения «ошибок» на изучение того, как модель ошибается, и какие закономерности лежат в основе этих ошибок.
Будущее исследований в этой области — не в создании более сложных метрик, а в разработке методов, позволяющих моделировать и предсказывать поведение системы в условиях неопределённости. Гарантии — это договор с вероятностью, и только осознание этой договорённости позволит построить действительно надежные системы, способные адаптироваться к непредсказуемости окружающего мира.
Оригинал статьи: https://arxiv.org/pdf/2602.12092.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Ребусы для ИИ: новый масштабный тест на сообразительность
- Разумные языковые модели: новый подход к логическому мышлению
- Искусственный интеллект: разумно и эффективно
- Масштабная Интерпретация: Новый Взгляд на Надежность Нейросетей
- Генерируем изображения с умом: новая модель DeepGen 1.0
- Искусственный интеллект на службе правосудия: моделируя вопросы в судебных дебатах
- Взрыв скорости: Оптимизация внимания для современных GPU
2026-02-14 09:23