Автор: Денис Аветисян
Новый масштабный набор данных и эталонный тест NMRGym призван ускорить разработку алгоритмов машинного обучения для точного определения молекулярной структуры по данным ЯМР-спектроскопии.
Представлен комплексный эталонный набор данных для оценки и улучшения методов машинного обучения в области структурной элюцидации на основе спектров ядерного магнитного резонанса.
Несмотря на значительный прогресс в области машинного обучения, автоматическое определение молекулярной структуры по данным ядерного магнитного резонанса (ЯМР) остается сложной задачей из-за нехватки качественных, экспериментальных данных. В настоящей работе представлена платформа ‘NMRGym: A Comprehensive Benchmark for Nuclear Magnetic Resonance Based Molecular Structure Elucidation’, включающая в себя крупнейший на сегодняшний день стандартизированный набор данных и эталонный комплекс, основанный на высококачественных экспериментальных ЯМР-спектрах, содержащий 269\,999 уникальных молекул. Предложенный ресурс призван преодолеть разрыв между синтетическими данными и реальным разнообразием спектров, обеспечивая строгий контроль качества и предотвращая утечку данных благодаря использованию scaffold-based разделения. Не откроет ли это новые возможности для разработки более точных и надежных методов определения молекулярной структуры с использованием машинного обучения?
Основы молекулярной структуры: вызов и возможности
Определение молекулярной структуры является краеугольным камнем всей химической науки, однако традиционные методы анализа зачастую требуют значительных временных затрат и высокой квалификации специалиста для корректной интерпретации результатов. Процесс идентификации и подтверждения расположения атомов в молекуле, будь то с использованием рентгеноструктурного анализа, масс-спектрометрии или спектроскопии ядерного магнитного резонанса, предполагает сложные процедуры и глубокое понимание принципов, лежащих в основе этих методов. Необходимость ручного анализа данных, особенно для соединений со сложной структурой, создает узкое место в исследовательских процессах и ограничивает скорость открытия новых материалов и лекарственных средств. Вследствие этого, разработка автоматизированных и более эффективных подходов к определению молекулярной структуры представляет собой важную задачу современной химии.
Ядерный магнитный резонанс (ЯМР) предоставляет исключительную информацию о молекулярной структуре, однако ручной анализ ЯМР-спектров становится серьезным препятствием при исследовании сложных органических соединений. Интерпретация сигналов, требующая глубоких знаний и опыта, занимает значительное время даже у квалифицированных специалистов. Проблема усугубляется при наличии большого числа перекрывающихся пиков, характерных для молекул с множеством атомов, что делает определение точной структуры крайне трудоемким процессом. Вследствие этого, скорость открытия и анализа новых соединений, особенно в областях фармацевтики и материаловедения, существенно ограничивается необходимостью кропотливой ручной обработки данных, что подталкивает к разработке автоматизированных методов анализа ЯМР-спектров.
Существующие базы данных спектров ядерного магнитного резонанса, такие как NMRShiftDB, несмотря на свою ценность, сталкиваются с проблемой ограниченного охвата химического пространства. Это означает, что спектральные данные для значительной части известных и потенциально существующих молекул остаются недоступными, что существенно затрудняет автоматическое определение структуры. Ограниченность данных не позволяет в полной мере обучать и тестировать алгоритмы, предназначенные для автоматического сопоставления спектров с молекулярными структурами. В результате, эффективность этих алгоритмов снижается, особенно при анализе новых или сложных соединений, для которых отсутствуют референсные данные в базах. Создание и расширение спектральных баз данных, включающих разнообразные классы соединений и условия измерений, является ключевым фактором для продвижения автоматического определения структуры молекул и ускорения химических исследований.
Отсутствие исчерпывающих и стандартизированных наборов данных серьезно ограничивает прогресс в разработке и валидации новых вычислительных методов для определения молекулярной структуры. Без надежных эталонных данных, которые охватывают широкий спектр молекул и условий, алгоритмы машинного обучения и другие вычислительные подходы испытывают трудности в достижении высокой точности и надежности. Это создает замкнутый круг: недостаток качественных данных замедляет развитие алгоритмов, а неразвитость алгоритмов препятствует созданию более полных и точных наборов данных. Преодоление этого препятствия требует совместных усилий по созданию открытых, тщательно проверенных и стандартизированных баз данных, которые будут доступны научному сообществу для обучения и валидации новых методов, способствуя тем самым ускорению исследований в области химии и смежных наук.
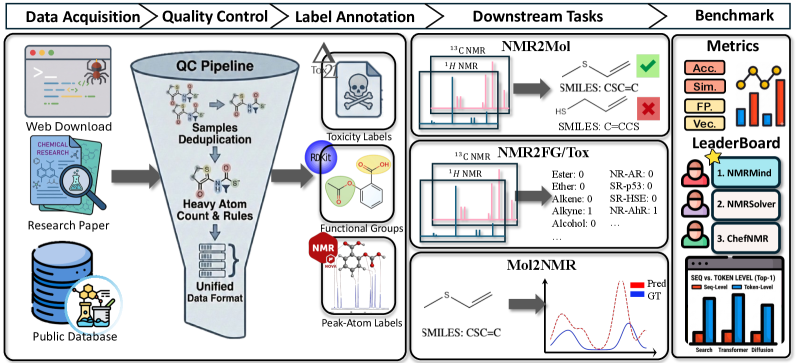
NMRGym: Фундамент для исследований, основанных на данных
NMRGym представляет собой масштабный экспериментальный набор данных ЯМР и эталон, состоящий из 269 999 пар «молекула-спектр». Данный набор данных устанавливает новый стандарт для исследований в области анализа ЯМР, предоставляя беспрецедентный объем данных для обучения и оценки алгоритмов. Размер набора данных позволяет проводить статистически значимые сравнения различных методов и подходов к анализу спектров ЯМР, что существенно для объективной оценки прогресса в данной области. Доступность такого масштаба данных облегчает разработку и валидацию новых моделей машинного обучения, предназначенных для автоматизации интерпретации спектров и решения задач, связанных со структурным анализом молекул.
Для обеспечения надежной оценки производительности моделей, используемых в анализе ЯМР, в NMRGym применяется строгий метод разделения данных — Scaffold Splitting. Этот подход предотвращает переобучение моделей на структурно схожих соединениях путем разделения набора данных таким образом, чтобы тренировочная и тестовая выборки не содержали молекул с общими каркасами (scaffolds). Каркас определяется как наибольший общий подграф молекулы, исключая боковые цепи и функциональные группы. Использование Scaffold Splitting гарантирует, что модель, обученная на определенном наборе соединений, будет адекватно оценена на совершенно новых, структурно отличающихся молекулах, что позволяет получить более реалистичную оценку ее обобщающей способности и избежать ложноположительных результатов.
Стандартизированный набор данных NMRGym предоставляет единую платформу для сравнительного анализа различных вычислительных методов в области ядерного магнитного резонанса. Возможность объективно сопоставлять производительность алгоритмов, используя унифицированный набор молекул и соответствующих спектров, позволяет количественно оценивать прогресс в разработке новых методов, например, в задачах предсказания спектров или определения структуры молекул. Такой подход обеспечивает воспроизводимость результатов и способствует ускорению исследований, поскольку позволяет исследователям сосредоточиться на улучшении алгоритмов, а не на подготовке и валидации данных. Наличие общедоступного эталона позволяет отслеживать эволюцию методов машинного обучения и других вычислительных подходов в данной области.
Платформа NMRGym предоставляет возможности для разработки автоматизированных рабочих процессов, предназначенных для установления структуры молекул, что позволяет снизить зависимость от ручной интерпретации спектральных данных. Это достигается за счет предоставления большого набора данных, включающего пары «молекула-спектр», которые могут быть использованы для обучения и оценки алгоритмов автоматического определения структуры. Автоматизация процесса не только повышает скорость анализа, но и снижает вероятность ошибок, связанных с субъективной интерпретацией данных человеком, что особенно важно при работе с большими объемами данных и сложными молекулярными структурами.
Машинное обучение для интерпретации спектров: доказательства эффективности
Диффузионные модели и архитектура Transformer все активнее применяются в задачах установления структуры молекул, демонстрируя способность генерировать реалистичные спектры и интерпретировать сложные паттерны. Эти подходы, основанные на принципах машинного обучения, позволяют создавать модели, способные прогнозировать спектральные характеристики на основе молекулярной структуры и, наоборот, восстанавливать структуру по наблюдаемому спектру. Их эффективность обусловлена способностью улавливать сложные зависимости между структурой и спектральными данными, превосходя традиционные методы в задачах, требующих анализа нелинейных и многомерных данных. Особенностью является возможность обучения на больших объемах данных и последующего применения для анализа новых, ранее не встречавшихся молекул.
Методы машинного обучения, такие как диффузионные модели и архитектуры Transformer, используют обширный набор данных NMRGym для установления корреляции между молекулярной структурой и характеристиками спектра. NMRGym предоставляет большое количество синтетических спектров ядерного магнитного резонанса (ЯМР) и соответствующих молекулярных графов, что позволяет алгоритмам обучаться на взаимосвязи между этими двумя представлениями. Использование такого масштабного датасета позволяет моделям эффективно извлекать закономерности и предсказывать молекулярную структуру на основе спектральных данных, а также наоборот. Обучение на данных NMRGym позволяет повысить точность и надежность методов интерпретации спектров ЯМР, автоматизируя процесс определения структуры молекул.
Дополнительные методы, такие как HSQC (Heteronuclear Single Quantum Coherence) и COSY (Correlation Spectroscopy), значительно повышают эффективность установления структуры молекул, предоставляя важную информацию о связности атомов. HSQC позволяет установить прямые связи между атомами углерода и протонами, что упрощает идентификацию фрагментов молекулы. COSY, в свою очередь, выявляет корреляции между протонами, находящимися в непосредственной близости друг от друга, что позволяет определить последовательности протонов и их взаимное расположение в молекуле. Комбинированное использование HSQC и COSY в сочетании с другими спектроскопическими методами позволяет более точно и быстро определять структуру сложных органических соединений.
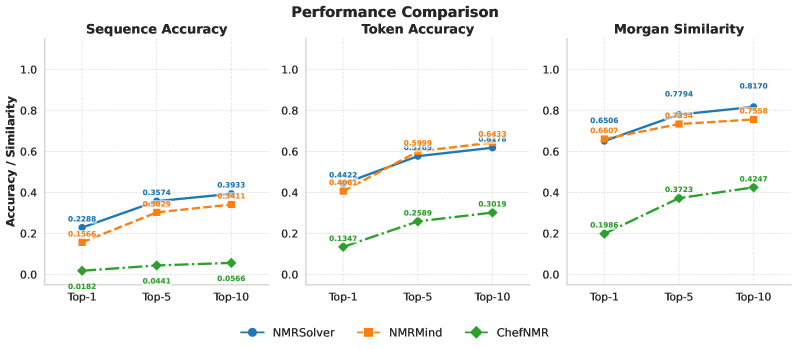
При использовании набора данных NMRGym, программный комплекс NMR-Solver достиг точности последовательности в 22.88% (Top-1), что превышает показатель NMRMind, составивший 15.66%. Данный результат демонстрирует превосходство NMR-Solver в задачах определения последовательности молекул на основе данных ядерного магнитного резонанса, при использовании указанного набора данных для обучения и оценки.
Прогнозирование молекулярных свойств по данным ЯМР: перспективы и влияние
Современные методы машинного обучения, такие как XGBoost и Random Forest, демонстрируют впечатляющую способность предсказывать токсичность молекул непосредственно на основе данных ядерного магнитного резонанса (ЯМР). Этот подход позволяет отказаться от необходимости проведения дорогостоящих и трудоемких лабораторных исследований, заменяя их анализом спектральных характеристик. Обученные на обширных наборах данных ЯМР, эти модели способны выявлять сложные корреляции между спектральными особенностями и потенциальной токсичностью вещества, предоставляя исследователям возможность оперативно оценивать безопасность новых соединений на ранних стадиях разработки. Такой анализ, основанный на данных ЯМР, открывает новые перспективы в области создания лекарственных препаратов и материалов, позволяя значительно ускорить процесс поиска и идентификации безопасных и эффективных соединений.
Возможность предсказывать свойства молекул непосредственно по данным ЯМР-спектров открывает принципиально новые перспективы в области разработки лекарственных средств и материаловедения. Благодаря этому подходу становится возможен быстрый скрининг большого числа соединений с целью выявления веществ, обладающих заданными характеристиками, такими как биологическая активность или специфические физические свойства. Традиционные методы, требующие трудоемкого синтеза и экспериментальной проверки каждого соединения, могут быть значительно ускорены и оптимизированы, позволяя ученым концентрироваться на наиболее перспективных кандидатах. Такой подход не только сокращает время и затраты на исследования, но и способствует созданию более эффективных и инновационных материалов и лекарств.
Сочетание предсказания спектров и свойств молекул открывает принципиально новые возможности для рационального дизайна материалов и лекарственных средств. Вместо трудоемкого и дорогостоящего синтеза и экспериментальной проверки, исследователи получают инструмент для предсказания характеристик молекул непосредственно на основе их спектров ядерного магнитного резонанса. Это позволяет, например, быстро выявлять соединения с желаемой токсичностью или биологической активностью, значительно сокращая время и затраты на разработку новых продуктов. Такой подход, объединяющий спектральную информацию и предсказание свойств, позволяет целенаправленно конструировать молекулы с заданными параметрами, открывая путь к созданию инновационных материалов и лекарств с улучшенными характеристиками.
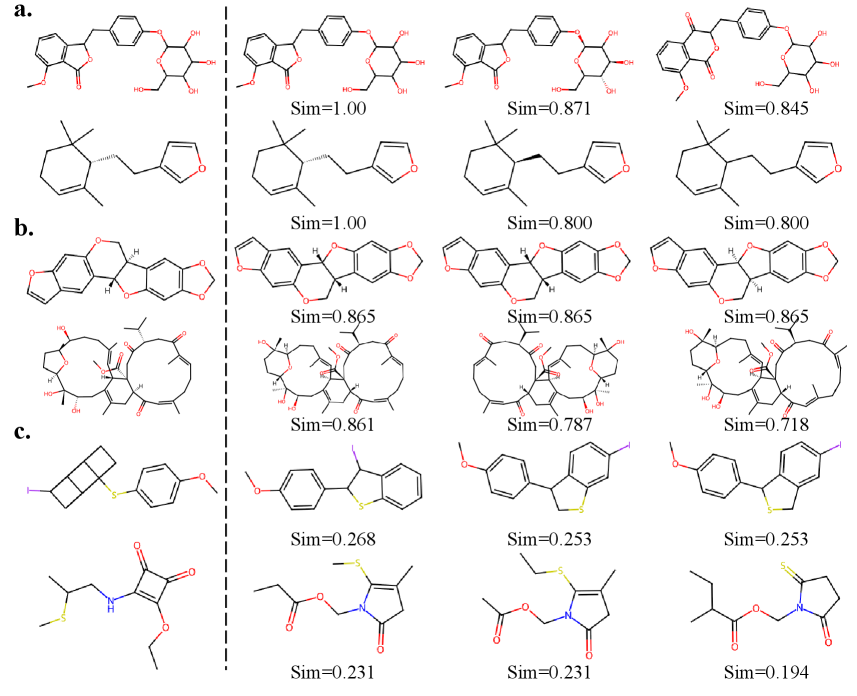
В ходе исследований, использующих датасет NMRGym, алгоритм NMR-Solver продемонстрировал превосходные результаты в задачах предсказания молекулярных свойств. Достигнутый показатель Morgan Tanimoto Similarity составил 0.78, что превзошло результат NMRMind, равный 0.73. Параллельно, модель NMRFormer показала высокую эффективность в определении функциональных групп, достигнув значения Macro F1-Score в 55.44%. Эти результаты подчеркивают значительный прогресс в области машинного обучения для анализа спектров ядерного магнитного резонанса и открывают новые возможности для быстрого и точного определения характеристик молекул, что особенно важно для разработки новых лекарственных препаратов и материалов.
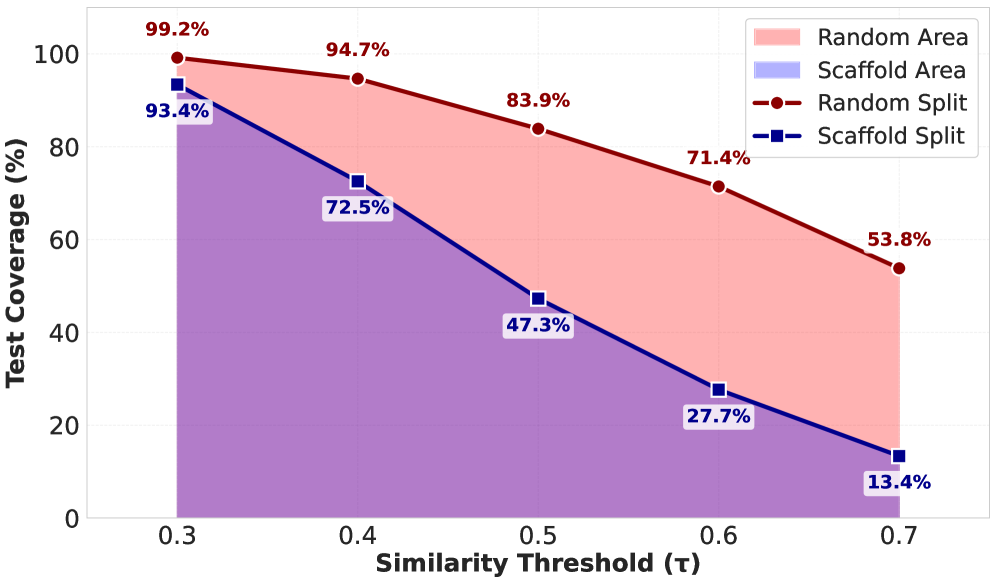
Представленная работа демонстрирует стремление к редукции сложности в задаче определения молекулярной структуры по данным ЯМР-спектроскопии. Создание стандартизированного набора данных NMRGym позволяет отделить фундаментальную проблему от шума, вносимого разнородностью экспериментальных условий. Как отмечал Г.Х. Харди: «Математика — это наука о том, что можно сделать, а не о том, что есть». Аналогично, NMRGym определяет рамки возможного прогресса в области применения методов глубокого обучения к анализу спектральных данных, фокусируясь на достижении предсказуемости и точности, а не на бесконечном усложнении моделей. Акцент на «scaffold splitting» — разделении молекулы на фрагменты — является примером поиска наиболее эффективного подхода к решению сложной задачи.
Куда же дальше?
Представленный набор данных, безусловно, представляет собой шаг к стандартизации, к упрощению ландшафта, загроможденного разнородными экспериментальными данными. Однако, не стоит обольщаться иллюзией полного охвата. Молекулярный мир бесконечно сложен, и любой, даже самый обширный, набор данных — это лишь его скромная проекция. Истинное понимание требует не накопления, а отсеивания лишнего, выявления фундаментальных принципов, лежащих в основе спектральных закономерностей.
Следующим этапом представляется не столько увеличение объема данных, сколько развитие алгоритмов, способных к обобщению, к экстраполяции за пределы тренировочной выборки. Необходимо сместить акцент с brute-force подходов, основанных на слепом переборе, к моделям, способным к логическому выводу, к построению гипотез о структуре молекулы на основе минимального набора спектральных признаков. Умение различать существенное от несущественного — вот истинный критерий интеллекта.
В конечном счете, задача предсказания структуры молекулы по спектрам — это не столько техническая проблема, сколько философский вызов. Это попытка воспроизвести в алгоритме интуицию опытного спектроскописта, его способность к улавливанию тонких нюансов, к распознаванию закономерностей в хаосе сигналов. И в этом смысле, путь к совершенству лежит не через усложнение, а через упрощение.
Оригинал статьи: https://arxiv.org/pdf/2601.15763.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 23:11