Автор: Денис Аветисян
Обзор текущего состояния исследований в области Queer NLP выявляет значительные пробелы, предвзятости и отсутствие разнообразия в подходах к обработке естественного языка.

Анализ существующих исследований в области Queer NLP с акцентом на пробелы в литературе, предвзятости, тенденции и необходимость вовлечения представителей сообщества.
Несмотря на стремительное развитие технологий обработки естественного языка (NLP), вопросы справедливости и инклюзивности в отношении ЛГБТК+ сообществ остаются недостаточно изученными. Данная работа, озаренная названием ‘Queer NLP: A Critical Survey on Literature Gaps, Biases and Trends’, представляет собой критический обзор существующих исследований, выявляя преобладание реактивного подхода к выявлению предвзятостей и недостаток проактивных решений. Анализ показывает, что большинство работ сосредоточено на английском языке, игнорируя вопросы пересечения идентичностей и недостаточно вовлекая представителей сообщества в процесс разработки и оценки. Какие шаги необходимо предпринять для создания действительно инклюзивных и справедливых NLP-технологий, учитывающих многообразие языков и опыта?
Пределы Доминирующих Парадигм в Обработке Естественного Языка
Современные модели обработки естественного языка (NLP) демонстрируют существенные ограничения, обусловленные их преобладающей ориентацией на английский язык и использование огромных объемов данных, преимущественно англоязычного происхождения. Этот фактор приводит к тому, что сложные грамматические конструкции и семантические нюансы, характерные для других языков, часто игнорируются или упрощаются, что снижает точность и адекватность анализа неанглийских текстов. Более того, алгоритмы, обученные на англоязычных данных, могут испытывать трудности при обработке языков с отличным синтаксисом, морфологией или культурными особенностями, что приводит к ошибкам в переводе, классификации или генерации текста. В результате, существующие NLP-системы не всегда способны адекватно понимать и обрабатывать информацию, представленную на других языках, что создает барьеры для глобального доступа к языковым технологиям и усиливает цифровое неравенство.
Сосредоточенность современных моделей обработки естественного языка преимущественно на английском языке приводит к игнорированию лингвистического разнообразия и усугубляет неравенство в доступе к технологиям. Многие языки мира обладают уникальными грамматическими структурами, семантическими нюансами и культурными особенностями, которые не учитываются в алгоритмах, разработанных и обученных в основном на английском языке. Это приводит к снижению эффективности и точности обработки неанглийских текстов, а также к тому, что носители других языков оказываются лишены возможности полноценно использовать преимущества современных лингвистических технологий, что создает цифровой разрыв и ограничивает возможности коммуникации и доступа к информации.
Традиционные методы обработки естественного языка часто оказываются неспособными адекватно отразить многогранность гендерной и сексуальной идентичности, что приводит к искажениям и потенциальному нанесению вреда. Анализ существующих моделей показывает, что они склонны к упрощенному представлению этих категорий, игнорируя разнообразие самовыражения и индивидуальных переживаний. Это проявляется, например, в автоматическом присвоении гендерных ролей на основе стереотипных ассоциаций или в нечувствительности к небинарным идентичностям. В результате, системы обработки языка могут непреднамеренно увековечивать предрассудки, дискриминировать определенные группы людей или даже причинять эмоциональный ущерб, подчеркивая важность разработки более инклюзивных и осознанных подходов к лингвистическому анализу и моделированию.
Всесторонний анализ 8686 научных работ, представленных в базе данных ACL Anthology, выявил острую необходимость переосмысления основополагающих принципов и методологий обработки естественного языка. Исследование показало, что существующие подходы часто опираются на устаревшие предположения и не учитывают сложность и многообразие языковых структур. Обнаруженные пробелы в исследованиях указывают на потребность в разработке более инклюзивных и адаптивных моделей, способных эффективно работать с различными языками и лингвистическими явлениями. Такой пересмотр позволит создать более справедливые и точные инструменты для анализа и понимания языка, открывая новые возможности для развития технологий обработки естественного языка во всем мире.
Квир НЛП: Рамки Инклюзивности и Критического Анализа
Квир НЛП (Queer NLP) представляет собой применение принципов квир-теории к области компьютерной лингвистики. Данный подход предполагает критический анализ и деконструкцию нормативных предположений, заложенных в лингвистические технологии, включая алгоритмы обработки естественного языка и системы машинного перевода. Целью является выявление и устранение предвзятостей и стереотипов, которые могут приводить к дискриминации или неадекватному представлению различных социальных групп. Анализ фокусируется на том, как языковые модели воспроизводят и усиливают существующие властные структуры, и предлагает методы для создания более инклюзивных и справедливых технологий.
В рамках Queer NLP особое внимание уделяется репрезентации маргинализированных идентичностей и опыта, что предполагает отход от упрощенных или вредоносных стереотипов в лингвистических технологиях. Это включает в себя критический анализ существующих языковых моделей и наборов данных на предмет предвзятости и недостаточной представленности различных групп. Целью является создание более инклюзивных и справедливых систем, которые отражают разнообразие человеческого опыта и избегают увековечивания дискриминационных практик. Акцент делается на разработке методов, позволяющих учитывать нюансы и сложность идентичности, а также на создании инструментов для выявления и смягчения предвзятости в языковых данных и алгоритмах.
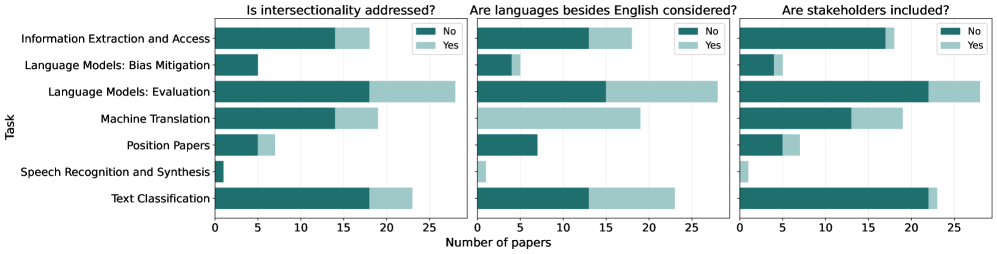
В основе Queer NLP лежит понимание интерсекциональности — концепции, описывающей, как пересекающиеся системы власти формируют язык и создают неравенства. Интерсекциональность признает, что идентичности и переживания людей формируются не только одной характеристикой (например, гендером или сексуальной ориентацией), но и сложным взаимодействием различных социальных категорий, таких как раса, класс, инвалидность и другие. Это взаимодействие приводит к уникальным формам дискриминации и предвзятости, которые проявляются в языке и могут быть усилены или увековечены технологиями обработки естественного языка. Анализ языка с учетом интерсекциональности позволяет выявить и смягчить эти предвзятости, обеспечивая более справедливое и инклюзивное представление различных социальных групп.
При разработке и оценке систем обработки естественного языка (NLP) ключевое значение имеет вовлечение заинтересованных сторон. Результаты исследований показывают, что согласованность оценок, полученных от различных участников, достигает 90.09%. Данный показатель согласованности, измеренный с использованием коэффициента Коэна κ равного 0.79, свидетельствует о высокой степени консенсуса в оценках и подтверждает надежность применяемых методик и критериев оценки, учитывающих разнообразные перспективы и потребности различных групп пользователей.
Обнаружение и Смягчение Предвзятости в Языковых Моделях
Методы обнаружения предвзятости, такие как шаблонные методы и анализ данных, последовательно демонстрируют наличие вредных стереотипов в языковых моделях. Шаблонные методы, например, используют заранее определенные структуры предложений для выявления предвзятых ассоциаций, в то время как анализ данных исследует статистические закономерности в выходных данных модели. Результаты показывают, что модели часто воспроизводят и усиливают существующие социальные стереотипы, связанные с полом, расой, религией и другими категориями. Эти предвзятости могут проявляться в различных формах, включая гендерные предубеждения в профессиональных ролях, расовые стереотипы в описаниях личностей и негативные ассоциации с определенными группами населения. Обнаружение этих предвзятостей является критически важным шагом в разработке более справедливых и этичных языковых моделей.
Методы увеличения объема данных (Data Augmentation) позволяют смягчить дисбаланс в обучающих наборах, что особенно важно для повышения репрезентативности недостаточно представленных групп. Данный подход заключается в создании модифицированных версий существующих данных, например, путем перефразирования, обратного перевода или замены синонимов, с целью увеличения разнообразия и объема данных, связанных с целевыми группами. Это позволяет модели получить больше примеров для обучения, снижая вероятность формирования предвзятых суждений, основанных на недостаточной информации. Важно отметить, что эффективное применение Data Augmentation требует тщательного анализа данных и контроля качества генерируемых модификаций, чтобы избежать внесения новых искажений или ухудшения общей производительности модели.
Эффективное устранение предвзятости в языковых моделях требует внимательного подхода к представлению местоимений и разрешению кореференции, что необходимо для обеспечения точного и уважительного использования языка. Анализ 8686 научных работ показал, что лишь 25 из них непосредственно исследовали аспекты, связанные с местоимениями. Недостаточное внимание к корректному определению и использованию местоимений может приводить к усилению стереотипов и неверной атрибуции характеристик, особенно в контексте гендерной, расовой или иной социальной идентичности. Это указывает на значительный пробел в исследованиях, требующий дальнейшего изучения и разработки методов, гарантирующих нейтральное и корректное представление информации.
Стратегии смягчения предвзятости в языковых моделях требуют сочетания с тщательной оценкой и постоянным мониторингом для предотвращения увековечивания вреда. Анализ существующих исследований показывает недостаточную проработку данной проблемы: из общего числа рассмотренных работ (8686) лишь 12 и 13 статей непосредственно посвящены анализу использования оскорбительных выражений/идентификационных терминов и стереотипов соответственно. Это указывает на необходимость более глубокого изучения и разработки методов оценки эффективности мер по снижению предвзятости, а также постоянного контроля за языковыми моделями после их развертывания для выявления и устранения потенциального вреда.
К Более Справедливому Будущему Обработки Естественного Языка
Применение принципов Queer NLP открывает возможности для создания более инклюзивных и справедливых языковых технологий, способных принести пользу маргинализированным сообществам. Этот подход предполагает критический анализ и деконструкцию гетеронормативных представлений, заложенных в лингвистические данные и алгоритмы обработки естественного языка. В результате, системы становятся способны более точно и уважительно отражать разнообразие гендерных идентичностей, сексуальных ориентаций и языковых практик. Вместо того, чтобы увековечивать предрассудки и стереотипы, Queer NLP стремится к созданию технологий, которые признают и ценят уникальность каждого пользователя, обеспечивая равный доступ к информации и коммуникации для всех.
Разработка систем обработки естественного языка, основанная на критике общепринятых норм и приоритете разнообразного представления данных, позволяет создавать более точные, уважительные и справедливые инструменты. Традиционно, алгоритмы часто обучаются на данных, отражающих доминирующие культурные и лингвистические особенности, что приводит к систематическим ошибкам и предвзятости в отношении маргинализированных групп. Переход к более инклюзивному подходу требует сознательного включения в обучающие наборы данных примеров, представляющих различные гендеры, расы, социально-экономические слои и языковые варианты. Это не только улучшает производительность систем в отношении этих групп, но и способствует созданию технологий, которые по-настоящему отражают сложность и многообразие человеческого языка и опыта, что, в свою очередь, повышает доверие к ним и обеспечивает более справедливое применение.
Для поступательного развития области обработки естественного языка, необходимы строгие научные исследования, опирающиеся на методологию PRISMA. Данный подход обеспечивает прозрачность и воспроизводимость результатов, что критически важно для построения надежных и справедливых языковых моделей. Особое внимание уделяется использованию ресурсов, таких как ACL Anthology, для всестороннего анализа существующих работ. Примечательно, что при оценке согласованности между экспертами в вопросах лингвистического разнообразия, достигнута абсолютная надежность — 100%, что свидетельствует о возможности объективной оценки и учета различных языковых нюансов при создании современных NLP-систем.
Применение принципов справедливости и инклюзивности в области обработки естественного языка (NLP) — это не просто вопрос социальной ответственности, но и фундаментальный шаг к созданию более совершенных и полезных технологий. Игнорирование разнообразия в лингвистических данных и алгоритмах приводит к предвзятости систем, что может усугубить существующее неравенство и исключить целые группы людей из сферы технологического прогресса. Вместо этого, осознанное стремление к разнообразию и справедливости позволяет разрабатывать инструменты, которые точно и уважительно отражают реальный мир, обеспечивая равный доступ к информации и возможностям для всех. Интеграция этих принципов является необходимым условием для построения будущего, в котором NLP служит инструментом расширения прав и возможностей, а не воспроизводит и усиливает существующие формы дискриминации.
Исследование, представленное в данной работе, подчеркивает важность целостного подхода к разработке систем обработки естественного языка. Как отмечал Карл Фридрих Гаусс: «Если бы я должен был выбрать одно слово, чтобы описать математику, я бы выбрал чистоту». Эта чистота проявляется не только в точности алгоритмов, но и в ясности понимания влияния каждого элемента на общую систему. В контексте Queer NLP, работа демонстрирует, что недостаточно просто исправить отдельные предвзятости; необходимо учитывать всю сложность языкового ландшафта и вовлекать представителей сообщества для обеспечения действительно инклюзивных и справедливых решений. Отсутствие внимания к пересечению различных идентичностей и преобладание англоязычных исследований лишь подтверждает необходимость комплексного подхода, где каждая деталь имеет значение.
Куда же дальше?
Представленный анализ, как и любое исследование границ, обнажает не столько пройденный путь, сколько зияющие провалы. Доминирование англоязычных исследований в области Queer NLP — не просто лингвистическая особенность, а отражение более широкой тенденции к централизации знания и игнорированию многообразия языковых ландшафтов. Всё ломается по границам ответственности — если не видеть, что за пределами доминирующего языка существуют и другие голоса, скоро станет больно. Структура, определяющая поведение этой области, пока что оставляет за бортом значительную часть квир-сообщества.
Недостаток пересеченческого подхода — это не просто упущение, а фундаментальная ошибка. Игнорирование того факта, что идентичности многослойны и переплетены, обрекает исследования на поверхностность и неспособность понять истинные потребности сообщества. Попытки “исправить” отдельные аспекты предвзятости, не понимая общей системы угнетения, напоминают лечение симптомов, игнорируя первопричину.
И, наконец, отсутствие прямого участия квир-сообщества в проектировании и оценке исследований — это не просто этическая проблема, но и методологическая ошибка. Знание, созданное “для” сообщества, но без его участия, обречено на оторванность от реальности. Элегантный дизайн рождается из простоты и ясности, а ясность — из диалога. Будущее Queer NLP видится в переходе от “исследования сообщества” к “исследованию вместе с сообществом”.
Оригинал статьи: https://arxiv.org/pdf/2602.16151.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Серебро и медь: новый взгляд на наноаллои
- Оживший аватар: Генерация видео в реальном времени по голосу
- Погода под контролем: Единая модель для прогнозирования и анализа
- Огонь и Безопасность: Основы Пожарной Оптимизации
- Конфиденциальный анализ больших данных: новый подход к быстрым ответам
- Научные эксперименты с ИИ: новая платформа для проверки интеллекта
- Обучение роботов стало проще: используем смартфон для мгновенной оптимизации
2026-02-20 05:21