Автор: Денис Аветисян
Новая платформа позволяет автоматизировать сложные задачи лингвистической разметки, включая выявление метафор, используя возможности больших языковых моделей.
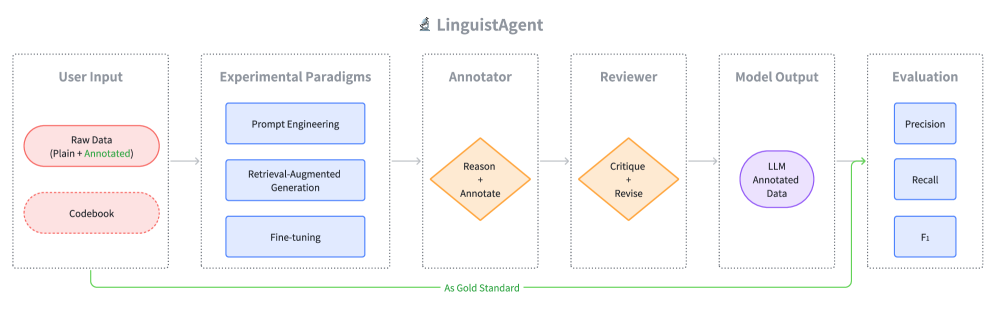
LinguistAgent — это платформа на основе многоагентных систем, предназначенная для масштабируемой и прозрачной автоматической лингвистической аннотации с использованием LLM и RAG.
Автоматизация лингвистической аннотации, особенно для сложных задач вроде выявления метафор, остается сложной проблемой в гуманитарных и социальных науках. В данной работе представлена платформа ‘LinguistAgent: A Reflective Multi-Model Platform for Automated Linguistic Annotation’, реализующая многоагентную архитектуру для автоматизации лингвистической разметки. Система, основанная на взаимодействии агентов-аннотатора и рецензента, позволяет проводить сравнительный анализ различных подходов, включая prompt engineering, retrieval-augmented generation и fine-tuning. Достигнутая прозрачность и воспроизводимость результатов, продемонстрированные на примере идентификации метафор с использованием токельной оценки (Precision, Recall, и F_1 score), открывают новые перспективы для масштабирования лингвистических исследований?
Преодоление Узких Мест: Вызовы Масштабирования Лингвистического Анализа
Для обучения надежных моделей обработки естественного языка (NLP) требуется масштабная лингвистическая аннотация данных, однако традиционные методы сталкиваются с существенными ограничениями по скорости и стоимости. Ручная разметка, хотя и обеспечивает определенную точность, требует значительных временных и финансовых ресурсов, особенно при работе с большими объемами текста. Автоматические методы, стремящиеся ускорить процесс, зачастую уступают в качестве, не учитывая тонкости и контекстуальные нюансы языка. В результате, создание достаточно больших и точных наборов размеченных данных становится серьезным препятствием для дальнейшего развития и внедрения NLP-технологий, требуя поиска новых, более эффективных подходов к аннотированию.
Ручное аннотирование лингвистических данных, несмотря на кажущуюся точность, часто подвержено субъективным расхождениям между разными аннотаторами, что снижает надежность и воспроизводимость результатов. Автоматизированные подходы, напротив, сталкиваются с трудностями при распознавании сложных языковых явлений, таких как метафоры, где требуется понимание контекста и неявного смысла. В то время как алгоритмы успешно справляются с прямыми значениями слов, тонкие оттенки и переносные значения, характерные для метафорического языка, зачастую остаются вне зоны их досягаемости, что приводит к неточным или ошибочным результатам анализа. Это особенно критично для задач, требующих глубокого понимания языка и интерпретации намерений автора.
Существующие методы лингвистической аннотации сталкиваются с трудностями в одновременном обеспечении высокой скорости, точности и детализированного обоснования каждого решения. В стремлении к быстрой обработке больших объемов данных часто страдает качество аннотаций, приводя к неточностям и ошибкам в обученных моделях. В то же время, попытки добиться максимальной точности и подробного описания причин каждой разметки требуют значительных временных затрат и ресурсов, замедляя процесс обучения и ограничивая масштабируемость. Таким образом, возникает необходимость в разработке новых подходов, которые позволят найти оптимальный баланс между этими ключевыми параметрами, обеспечивая не только корректность, но и прозрачность процесса аннотации для дальнейшего анализа и улучшения моделей обработки естественного языка.
LinguistAgent: Многоагентная Система для Улучшенной Аннотации
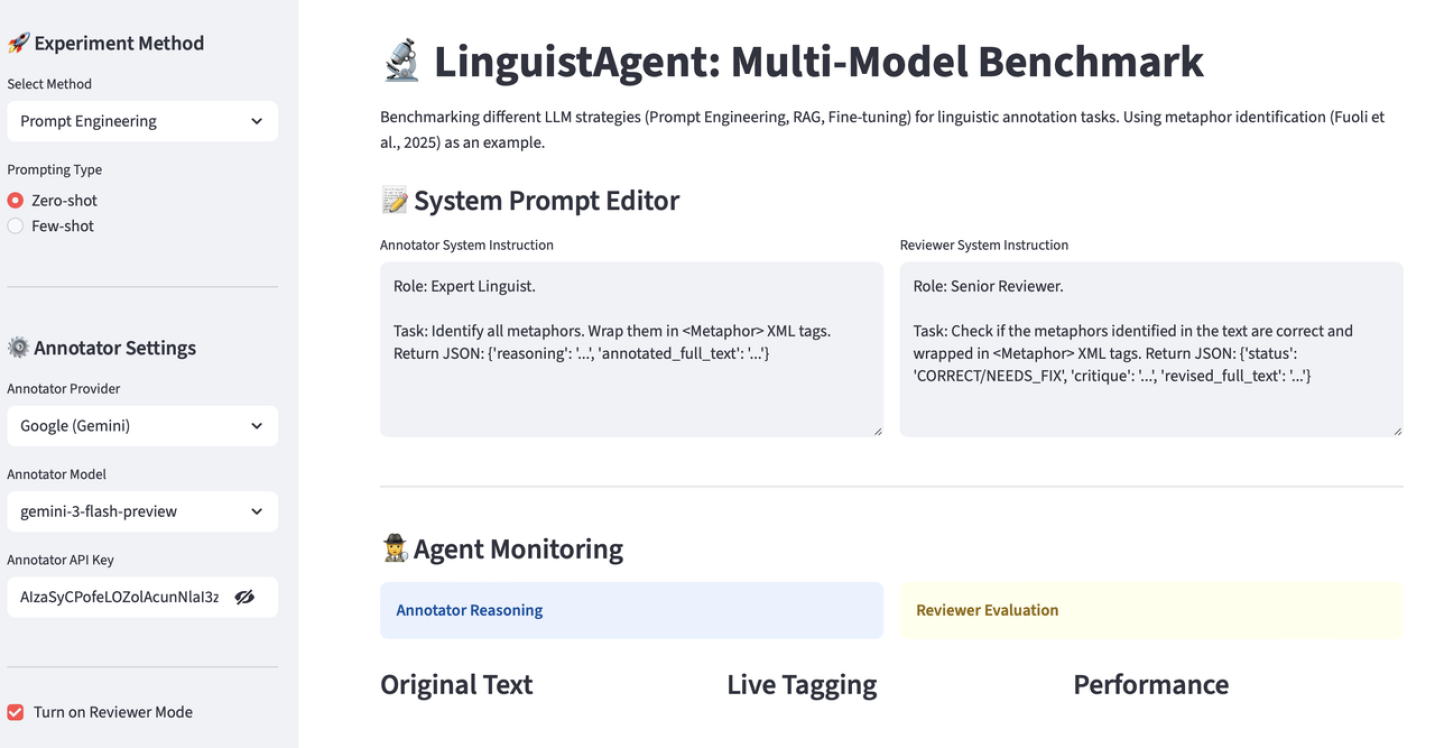
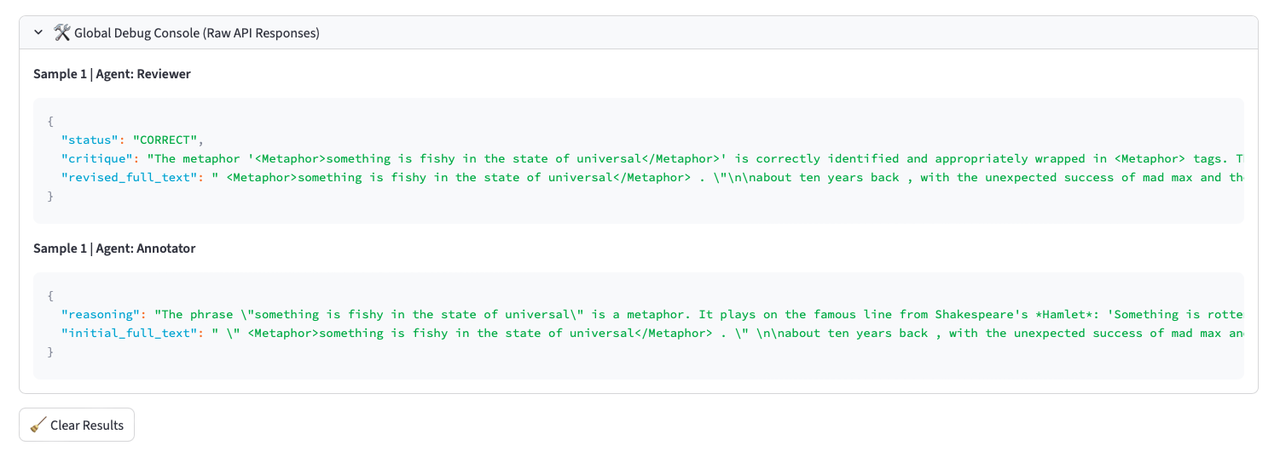
Система LinguistAgent использует рефлексивный многоагентный рабочий процесс, состоящий из двух ключевых компонентов: агента-аннотатора и агента-рецензента. Агент-аннотатор отвечает за первоначальную разметку данных, в то время как агент-рецензент выполняет проверку результатов, выявляя и исправляя потенциальные ошибки или галлюцинации. Взаимодействие между этими агентами позволяет значительно повысить качество разметки, обеспечивая более надежные и точные данные. Такой подход, основанный на взаимном контроле и коррекции, минимизирует риски, связанные с субъективностью или неточностью одного агента, и обеспечивает более стабильный и воспроизводимый результат.
Система LinguistAgent использует режим Native JSON для организации логических цепочек рассуждений, что обеспечивает структурированный и прозрачный процесс аннотации. В этом режиме все промежуточные шаги и обоснования, приведшие к конечному результату аннотации, сохраняются в формате JSON. Это позволяет не только отслеживать ход мыслей агента, но и проводить детальный аудит принятых решений, выявлять потенциальные ошибки и улучшать качество аннотаций. Использование структурированного формата данных обеспечивает возможность автоматизированной проверки и анализа цепочек рассуждений, повышая надежность и воспроизводимость результатов.
Система LinguistAgent имеет динамичный веб-интерфейс, разработанный с использованием фреймворка Streamlit. Это обеспечивает удобное взаимодействие пользователя с конвейером аннотирования, позволяя легко запускать, контролировать и анализировать процесс разметки данных. Интерфейс позволяет визуализировать ход выполнения задач, просматривать промежуточные результаты и вносить необходимые корректировки в режиме реального времени, что значительно упрощает работу и повышает эффективность разметки.

Усиление Производительности с RAG и Продвинутыми Моделями
Для повышения качества аннотаций внедрена технология Retrieval-Augmented Generation (RAG), предоставляющая агентам Аннотатору и Рецензенту доступ к внешним кодексам. RAG позволяет агентам динамически извлекать релевантную информацию из этих кодексов в процессе аннотирования, что значительно расширяет контекст и повышает точность определения и классификации данных. Внешние кодексы служат источником структурированных знаний, которые используются для улучшения понимания входных данных и обеспечения согласованности аннотаций. Данный подход позволяет агентам учитывать специфические термины, определения и правила, зафиксированные в кодексах, при выполнении задач аннотирования.
Агент LinguistAgent обеспечивает интеграцию с продвинутыми языковыми моделями, такими как Gemini 3 и Qwen3, что позволяет реализовать сложные процессы рассуждения и глубокое понимание контекста. Использование данных моделей значительно расширяет возможности анализа текста, позволяя учитывать нюансы значения и взаимосвязи между различными элементами информации. Это, в свою очередь, повышает точность и релевантность результатов обработки естественного языка, особенно в задачах, требующих сложного логического вывода и интерпретации.
Для оптимизации возможностей моделей, основанных на обучении с примерами (in-context learning), активно применяется инженерия запросов (Prompt Engineering). Этот подход предполагает тщательную разработку и настройку текстовых запросов, предоставляемых моделям Gemini 3 и Qwen3, с целью повышения точности аннотаций. Оптимизация включает в себя структурирование запросов, использование релевантных примеров в контексте запроса и контроль над длиной и сложностью формулировок. В результате, модели способны более эффективно использовать предоставленную информацию и генерировать более качественные и точные аннотации.
Строгая Оценка: Метрики и Результаты
Для оценки точности аннотаций используется токено-уровневая оценка, включающая расчет ключевых метрик: точности (Precision), полноты (Recall) и F1-меры. Точность определяет долю правильно аннотированных токенов среди всех токенов, помеченных системой. Полнота показывает, какая доля всех релевантных токенов была правильно идентифицирована. F1-мера является гармоническим средним между точностью и полнотой и позволяет оценить общее качество аннотации, учитывая баланс между ложноположительными и ложноотрицательными результатами. F1 = 2 <i> (Precision </i> Recall) / (Precision + Recall) Применение токено-уровневой оценки обеспечивает детальный анализ ошибок и позволяет выявить слабые места в процессе аннотирования.
Предлагаемая система оценки позволяет получить детальное представление о сильных и слабых сторонах системы, что достигается благодаря анализу результатов на уровне отдельных токенов. Такой гранулярный подход выявляет конкретные типы ошибок и области, где производительность системы снижается, например, при обработке определенных лингвистических конструкций или типов метафор. Полученные данные служат основой для целенаправленной оптимизации алгоритмов и моделей, позволяя повысить общую точность и надежность системы в процессе итеративного улучшения.
Результаты исследований демонстрируют значительное повышение эффективности выявления метафор при использовании LinguistAgent в цикле ‘Аннотация-Проверка-Оценка’. В частности, режим ‘Проверка’ (Reviewer Mode), включающий этап анализа и корректировки аннотаций, последовательно демонстрирует более высокие показатели точности по сравнению с режимом ‘Аннотация’ (Annotator-only mode), где данные предоставляются непосредственно без последующего анализа. Разница в производительности подтверждается метриками точности, полноты и F1-оценки, что указывает на существенное улучшение качества аннотированных данных благодаря этапу проверки.

Перспективы Развития: Адаптивность и За Ее Пределами
Модульная архитектура LinguistAgent обеспечивает бесшовную интеграцию методов тонкой настройки, позволяя пользователям адаптировать систему к специфическим требованиям аннотирования в различных областях. Такая гибкость достигается благодаря четкому разделению компонентов, что упрощает замену или модификацию отдельных модулей без влияния на общую функциональность. Это позволяет, например, обучить систему на специализированном корпусе текстов, относящихся к юридической или медицинской тематике, значительно повышая точность и релевантность аннотаций в этих областях. Возможность тонкой настройки открывает путь к созданию высокопроизводительных инструментов для решения узкоспециализированных задач обработки естественного языка, ранее требовавших значительных усилий по ручной адаптации и обучению.
Архитектура LinguistAgent демонстрирует значительную гибкость, выходящую за рамки задачи выявления метафор. Данный фреймворк способен адаптироваться к широкому спектру лингвистических задач, что открывает перспективы его применения в различных областях обработки естественного языка. Способность к модификации и расширению функциональности позволяет использовать систему для решения задач, связанных с анализом тональности, извлечением сущностей, автоматическим реферированием и многими другими. В отличие от специализированных инструментов, ориентированных на конкретные типы анализа, LinguistAgent предлагает универсальную платформу, способную эволюционировать вместе с потребностями исследователей и разработчиков в области NLP.
В дальнейшем планируется расширение функциональных возможностей агента LinguistAgent, с особым вниманием к интеграции знаний и развитию способностей к логическим умозаключениям в процессе аннотирования. Исследования сосредоточатся на внедрении инновационных методов, позволяющих агенту не только идентифицировать лингвистические явления, но и понимать контекст, делать выводы и учитывать различные источники информации. Это позволит существенно повысить точность и эффективность аннотирования, а также расширить область применения системы, сделав её полезной для решения более сложных задач в области обработки естественного языка. Разрабатываемые подходы направлены на создание интеллектуальной системы, способной к самообучению и адаптации к новым типам данных и задачам.
Платформа LinguistAgent, представленная в данной работе, стремится к созданию надежных и воспроизводимых систем лингвистической аннотации. Такой подход особенно важен в сложных задачах, как, например, идентификация метафор, где однозначность интерпретации критична. Это созвучно высказыванию Карла Фридриха Гаусса: «Если вы не можете решить задачу, разбейте ее на части, которые можно решить». Подобно тому, как Гаусс предлагал декомпозицию сложных проблем, LinguistAgent разбивает процесс аннотации на последовательность взаимодействующих агентов, каждый из которых отвечает за определенный аспект задачи. В результате достигается не только масштабируемость и автоматизация, но и прозрачность каждого шага, что позволяет верифицировать и улучшать качество результатов.
Куда Ведет Этот Путь?
Представленная платформа LinguistAgent, несомненно, демонстрирует потенциал автоматизации лингвистической аннотации. Однако, за кажущейся эффективностью кроется вопрос: действительно ли автоматизация, основанная на больших языковых моделях, приближает нас к истинному пониманию языка, или лишь создает иллюзию этого понимания? Идентификация метафор, хоть и кажется конкретной задачей, требует не просто сопоставления паттернов, а проникновения в семантические нюансы, которые пока остаются недоступными даже самым сложным алгоритмам.
Будущие исследования должны сосредоточиться не столько на увеличении масштаба автоматизации, сколько на повышении её доказуемости. Текущие подходы, основанные на prompt engineering и RAG, часто страдают от недостаточной прозрачности. Необходимо разработать метрики, позволяющие оценивать не просто точность, но и обоснованность принимаемых моделью решений. В противном случае, мы рискуем создать сложную систему, результаты которой будут столь же непрозрачны, как и сам язык.
Истинная элегантность лингвистической системы заключается не в её способности генерировать аннотации, а в её способности объяснить, почему эти аннотации были сгенерированы. Пока мы не достигнем этой цели, все наши усилия по автоматизации останутся лишь элегантными, но всё же несовершенными приближениями к истине.
Оригинал статьи: https://arxiv.org/pdf/2602.05493.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Графы и действия: новый подход к планированию для роботов
- Многокритериальная оптимизация: взгляд на народные методы
- В поисках оптимального дерева: новые горизонты GPU-вычислений
- Квантовые амбиции: Иран вступает в гонку
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Bibby AI: Новый помощник для исследователей в LaTeX
- Наука определений: Автоматическое извлечение знаний из научных текстов
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
2026-02-08 15:26