Автор: Денис Аветисян
Новое исследование показывает, что развитие технологий искусственного интеллекта создает глобальное неравенство в отношении языков, концентрируя преимущества в руках немногих.
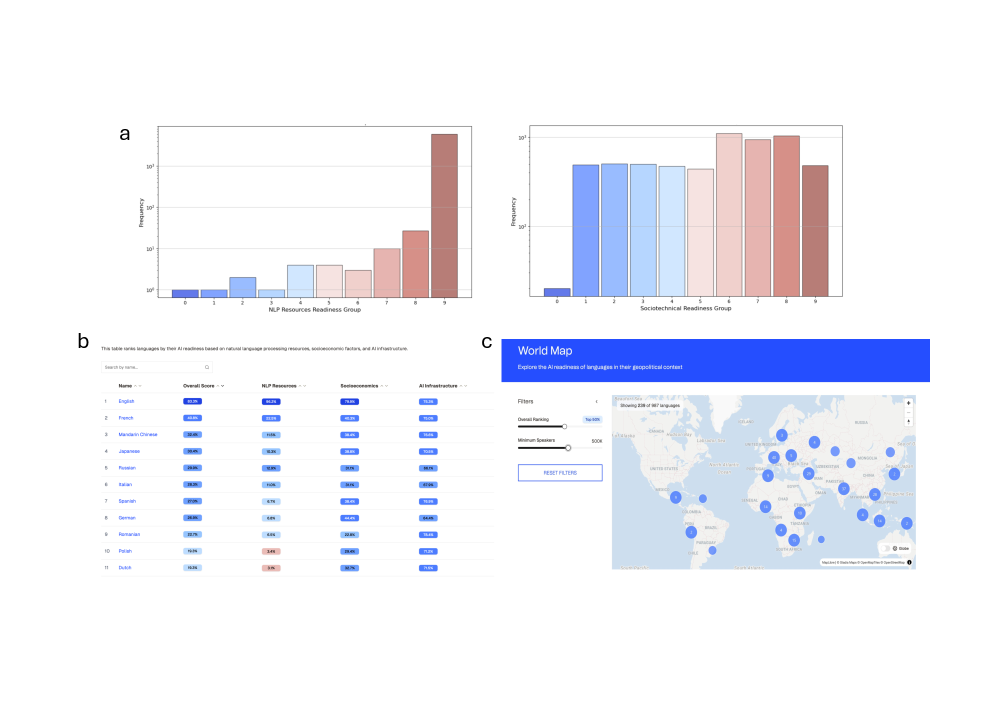
В статье представлен индекс EQUATE для оценки готовности языков к внедрению технологий искусственного интеллекта и выявления цифрового разрыва.
Несмотря на огромный потенциал искусственного интеллекта в трансформации различных сфер, от здравоохранения до образования, его преимущества непропорционально распределены между языками. В работе «Искусственный интеллект создает новую глобальную языковую иерархию» представлен анализ социально-экономических и инфраструктурных условий, определяющих неравенство в доступе к технологиям обработки естественного языка. Исследование выявило, что доминирование небольшого числа языков усугубляет цифровое неравенство, а предложенный индекс EQUATE позволяет оценить готовность языковых сообществ к внедрению ИИ. Сможем ли мы обеспечить более справедливое распределение преимуществ языкового ИИ и преодолеть растущую цифровую пропасть между различными языковыми группами?
Языковой Разлом: Неравномерность Преимуществ Искусственного Интеллекта
Несмотря на стремительное развитие искусственного интеллекта, его преимущества распределяются крайне неравномерно между языками мира, формируя цифровой языковой разрыв. В то время как некоторые языки, такие как английский и китайский, активно поддерживаются и постоянно совершенствуются в системах машинного перевода и обработки естественного языка, тысячи других языков остаются заброшенными и лишены доступа к этим технологиям. Этот дисбаланс не просто технологическая проблема, но и социальная, поскольку он ограничивает возможности для миллионов людей, лишая их доступа к информации, образованию и участию в цифровом обществе. По сути, формируется новая форма цифрового неравенства, где владение определенным языком становится определяющим фактором доступа к знаниям и возможностям.
Современные разработки в области языковых технологий демонстрируют явный перекос в пользу небольшого числа языков, обладающих обширными цифровыми ресурсами. Этот дисбаланс не просто отражает существующее неравенство в доступе к технологиям, но и усугубляет его. Языки с ограниченными цифровыми данными, такие как многие африканские и коренные языки, остаются в значительной степени исключенными из сферы развития искусственного интеллекта. В результате, носители этих языков сталкиваются с ограничениями в доступе к информации, образованию и возможностям, что создает цифровой разрыв и препятствует полноценному участию в глобальном информационном обществе. Отсутствие адекватной языковой поддержки в цифровой сфере может привести к дальнейшей маргинализации и утрате культурного разнообразия.
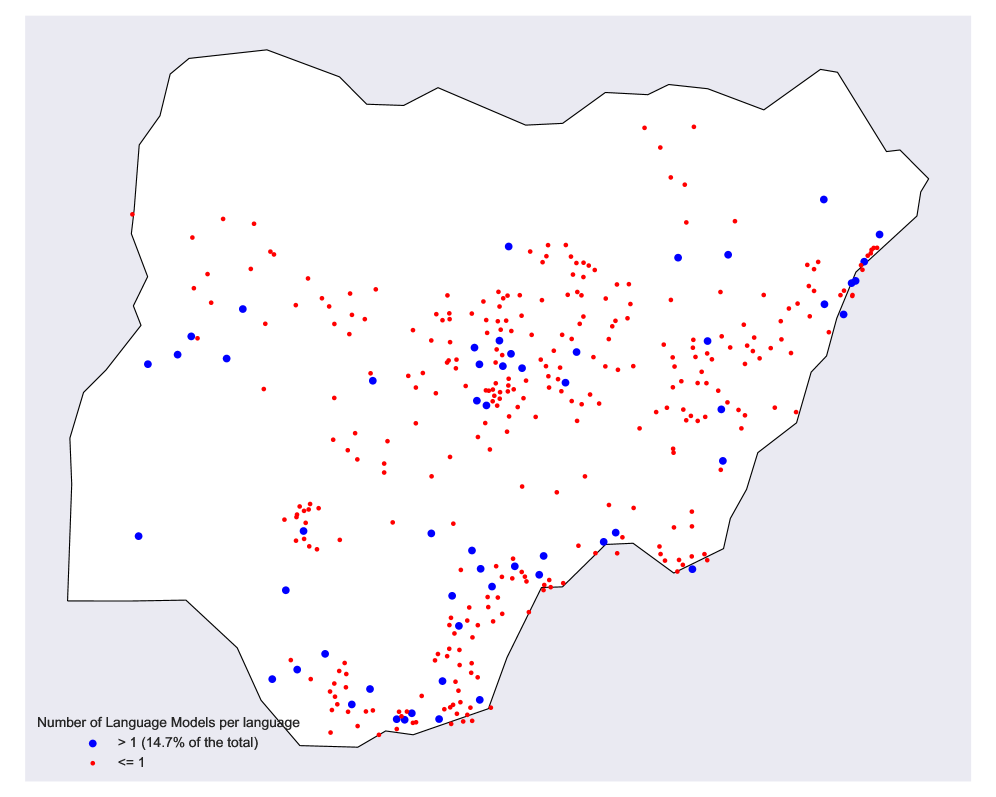
Анализ показал неожиданную картину распределения языкового охвата моделями искусственного интеллекта. Нигерия, несмотря на кажущиеся экономические и технологические различия, демонстрирует более высокий процент языков, представленных хотя бы одной языковой моделью — 14.7%, в то время как в Соединенных Штатах этот показатель составляет 14%, а в Австралии — всего 6.8%. Данный факт наглядно иллюстрирует неравномерность доступа к современным языковым технологиям и указывает на то, что разработка и внедрение искусственного интеллекта не всегда соответствует глобальным потребностям, а может, напротив, усиливать существующее неравенство в информационном пространстве.
Неравномерное развитие технологий обработки языка создает реальную угрозу маргинализации для носителей малоресурсных языков. Отсутствие адекватной поддержки в цифровой среде ограничивает доступ к информации, образованию и возможностям трудоустройства, усугубляя существующее социальное и экономическое неравенство. Это приводит к тому, что целые сообщества оказываются исключенными из глобального информационного пространства, лишаясь возможности полноценно участвовать в современной жизни и использовать преимущества цифровых технологий, доступных носителям доминирующих языков. В результате, языковое разнообразие, являющееся ценным культурным наследием, находится под угрозой исчезновения, а потенциал инноваций и развития, заключенный в этих языках, остается нереализованным.
EQUATE: Индекс Языковой Готовности к Искусственному Интеллекту
Индекс языковой готовности к искусственному интеллекту (EQUATE) представляет собой комплексную методологию оценки потенциала языка для развития технологий ИИ. Данный индекс не ограничивается техническими аспектами, а учитывает широкий спектр факторов, позволяющих определить, насколько язык пригоден для обучения моделей искусственного интеллекта и использования в различных приложениях. Оценка проводится на основе анализа доступных данных и позволяет составить объективную картину готовности конкретного языка к интеграции с современными ИИ-технологиями, выявляя сильные и слабые стороны, а также области, требующие дополнительного развития.
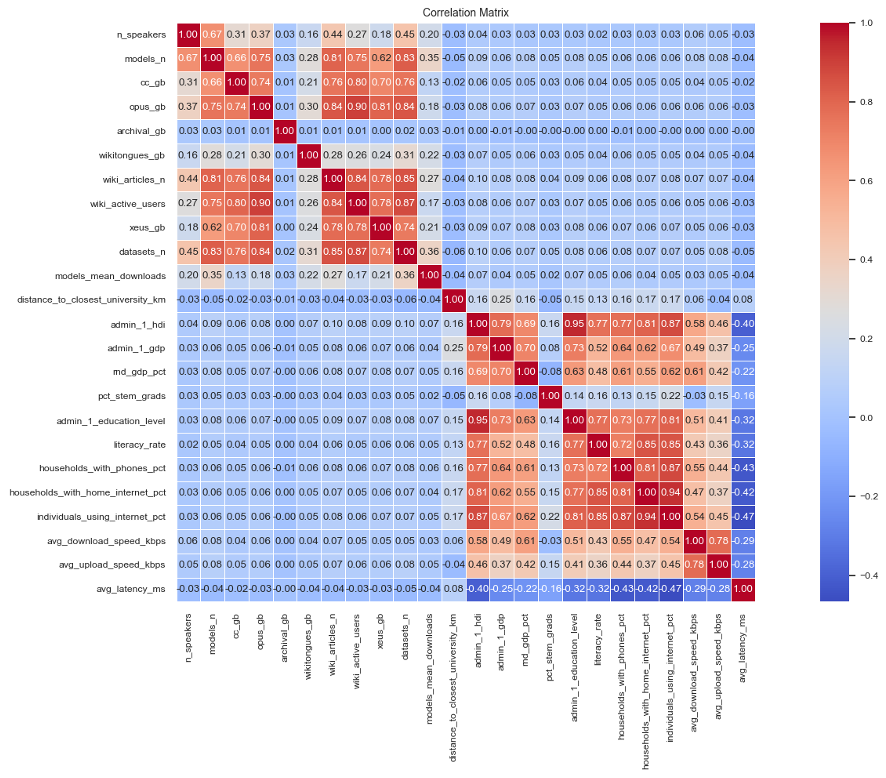
Индекс готовности языка к развитию ИИ (EQUATE) проводит комплексную оценку, опираясь на три ключевых столпа: доступность ресурсов ИИ, состояние цифровой инфраструктуры и социально-экономические условия. Доступность ресурсов ИИ включает в себя наличие квалифицированных специалистов, объемы размеченных данных и вычислительные мощности. Цифровая инфраструктура оценивается по показателям проникновения интернета, скорости соединения и уровня развития облачных технологий. Социально-экономические условия включают показатели ВВП на душу населения, уровень образования и индекс человеческого развития, отражающие общую способность общества к внедрению и адаптации к новым технологиям. Комбинация этих трех факторов позволяет получить всестороннее представление о потенциале языка для развития ИИ.
Анализ данных, полученных в рамках разработки индекса EQUATE, показал, что 58.4% вариативности в готовности языка к развитию искусственного интеллекта объясняется двумя основными компонентами. Эти компоненты позволяют отделить фундаментальное социально-экономическое развитие от доступности ресурсов, специфичных для искусственного интеллекта. Это разделение указывает на то, что общая готовность языка к ИИ в большей степени определяется базовыми показателями развития общества, чем исключительно наличием специализированных инструментов и экспертов в области ИИ.
Индекс готовности языков к ИИ (EQUATE) предоставляет детализированную оценку потенциала различных языков в контексте развития искусственного интеллекта. Анализ, учитывающий доступность ресурсов ИИ, состояние цифровой инфраструктуры и социально-экономические условия, позволяет выявить языки, обладающие наиболее благоприятными условиями для внедрения и развития ИИ-технологий. В частности, EQUATE определяет области, где необходимы целенаправленные инвестиции для улучшения инфраструктуры, увеличения доступности данных и повышения уровня цифровой грамотности населения, что критически важно для обеспечения равноправного доступа к преимуществам ИИ для носителей различных языков.
Методология EQUATE: Оценка и Анализ Данных
Индекс EQUATE использует взвешенное геометрическое среднее для комбинирования показателей по каждому столпу, что позволяет приоритизировать ключевые характеристики для точной оценки. В отличие от простого среднего арифметического, геометрическое среднее более чувствительно к минимальным значениям показателей, что отражает важность наличия базового уровня ресурсов для развития ИИ. Взвешивание показателей внутри геометрического среднего позволяет учесть относительную значимость каждого признака, определяемую на основе экспертных оценок и анализа данных. Формула взвешенного геометрического среднего выглядит следующим образом: \sqrt[n]{\prod_{i=1}^{n} x_i^{w_i}} , где x_i — значение i-го показателя, w_i — его вес, а n — общее количество показателей. Использование данной методологии обеспечивает более надежную и точную оценку готовности к использованию языковых моделей ИИ по сравнению с альтернативными подходами.
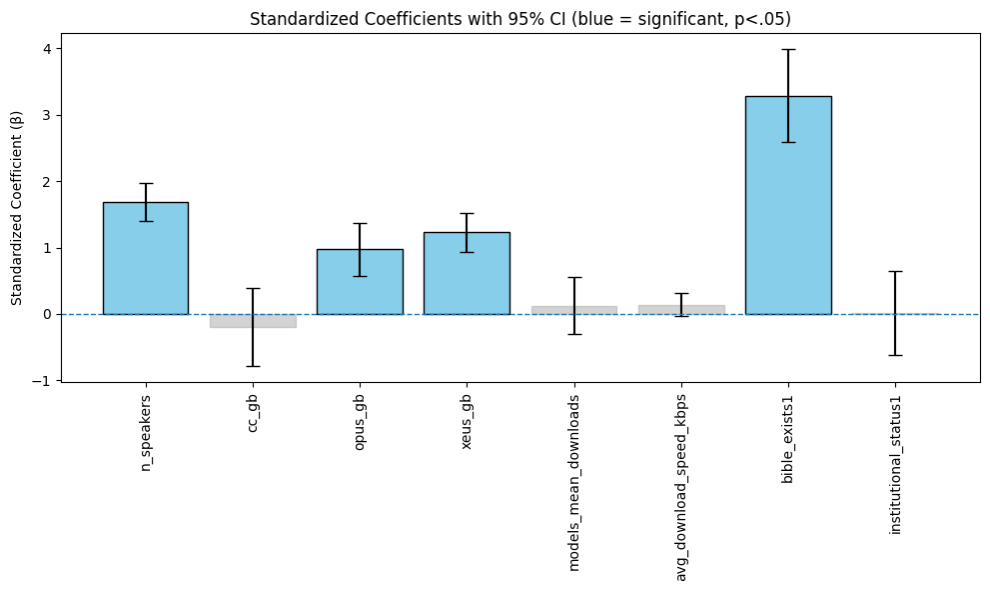
Для определения наиболее значимых предикторов готовности языков к использованию в системах искусственного интеллекта был применен метод пошаговой регрессии. Данный статистический метод позволяет последовательно добавлять или удалять переменные из регрессионной модели, основываясь на их статистической значимости и вкладе в объяснение дисперсии зависимой переменной. В процессе анализа, переменные с незначительным влиянием на прогнозирование готовности языка к ИИ исключались, а значимые — сохранялись, что позволило упростить модель и повысить ее прогностическую способность. Использование пошаговой регрессии позволило выделить ключевые факторы, определяющие готовность языков к использованию в системах ИИ, и оптимизировать модель для более точной оценки.
Для оценки доступности ресурсов для разработки и использования ИИ, индекс EQUATE использует данные из нескольких крупных корпусов текстов. Common Crawl предоставляет обширный веб-архив, охватывающий миллиарды страниц, что позволяет оценить объем текстовых данных, доступных для обучения моделей. OPUS — это коллекция параллельных корпусов, предоставляющая данные для задач машинного перевода и многоязыковой обработки. Корпус переводов Библии служит дополнительным источником для анализа языкового разнообразия и доступности религиозных текстов. Наконец, ACL Anthology содержит научные публикации в области компьютерной лингвистики, что позволяет оценить уровень исследований и разработок в данной сфере. Комбинация этих источников обеспечивает широкую и разнообразную базу данных для оценки ресурсов ИИ для различных языков.
Анализ данных показал крайне слабую (близкую к нулю) корреляцию Пирсона между объемом доступных ресурсов для ИИ и общеэкономическими показателями. Значение коэффициента корреляции, близкое к нулю, указывает на отсутствие статистически значимой связи между развитием инфраструктуры для искусственного интеллекта и общим уровнем социально-экономического развития. Это подтверждает гипотезу о том, что доступ к инструментам ИИ не является автоматическим следствием или индикатором общего прогресса, и что распределение этих ресурсов может быть неравномерным, не отражая общие тенденции экономического развития. r \approx 0
Влияние и Перспективы: На Пути к Инклюзивному Искусственному Интеллекту
Исследование EQUATE выявило существенную зависимость готовности к внедрению технологий искусственного интеллекта, работающих с естественным языком, от социально-экономических условий, оцениваемых индексом человеческого развития (ИЧР). Анализ показал, что страны с более высоким ИЧР демонстрируют значительно более высокую способность к адаптации и эффективному использованию этих технологий. Это указывает на то, что доступ к образованию, здравоохранению и достойному уровню жизни являются ключевыми факторами, определяющими возможность использования преимуществ, которые предоставляет развитие искусственного интеллекта в области обработки языка. Таким образом, неравенство в социально-экономическом развитии напрямую влияет на цифровое языковое неравенство, подчеркивая необходимость целенаправленных мер для обеспечения равного доступа к новым технологиям и снижения разрыва между развитыми и развивающимися странами.
Исследование углубляет понимание динамики цифрового языкового неравенства, демонстрируя, что неравномерный доступ к технологиям обработки языка не является случайным явлением, а обусловлен социально-экономическими факторами. Анализ показывает, что существующие диспропорции в применении языковых моделей усугубляют разрыв между развитыми и менее развитыми странами, создавая риски дальнейшей цифровой изоляции. В связи с этим, требуется разработка целенаправленных интервенций, направленных на преодоление этих дисбалансов, включая инвестиции в локализацию языковых ресурсов, поддержку разработки моделей для недостаточно представленных языков и обеспечение доступности технологий для образовательных и общественных организаций в регионах с низким уровнем развития. Игнорирование данной проблемы может привести к формированию «цифровой пропасти», в которой определенные сообщества будут лишены возможности полноценно участвовать в цифровой экономике и использовать преимущества, предоставляемые искусственным интеллектом.
Перспективные исследования планируют использовать модель Гомперца для анализа закономерностей распространения языковых технологий в различных регионах и сообществах. Этот математический подход позволит выявить ключевые факторы, влияющие на скорость и охват внедрения, такие как уровень цифровой грамотности, доступность инфраструктуры и экономические условия. Основываясь на полученных данных, можно будет разработать более эффективные стратегии обеспечения равного доступа к передовым языковым технологиям, направленные на сокращение цифрового неравенства и стимулирование социально-экономического развития в тех областях, где эти технологии пока недостаточно распространены. Применение модели Гомперца позволит не только прогнозировать темпы распространения, но и определять наиболее уязвимые группы населения, нуждающиеся в целенаправленной поддержке и образовательных программах.
Анализ показывает, что языковые модели демонстрируют наибольшую постоянную скорости роста (cc) среди сравниваемых технологий, что указывает на стремительную траекторию внедрения на ранних стадиях. Это означает, что распространение и адаптация этих моделей происходит значительно быстрее, чем у других цифровых инструментов. Такая динамика требует пристального внимания к потенциальным последствиям, как положительным, так и отрицательным, и подчеркивает необходимость проактивного подхода к управлению технологическим прогрессом. cc является ключевым параметром, отражающим скорость роста, и его высокое значение для языковых моделей указывает на значительный потенциал для трансформации различных областей, от образования и коммуникации до автоматизации и анализа данных.
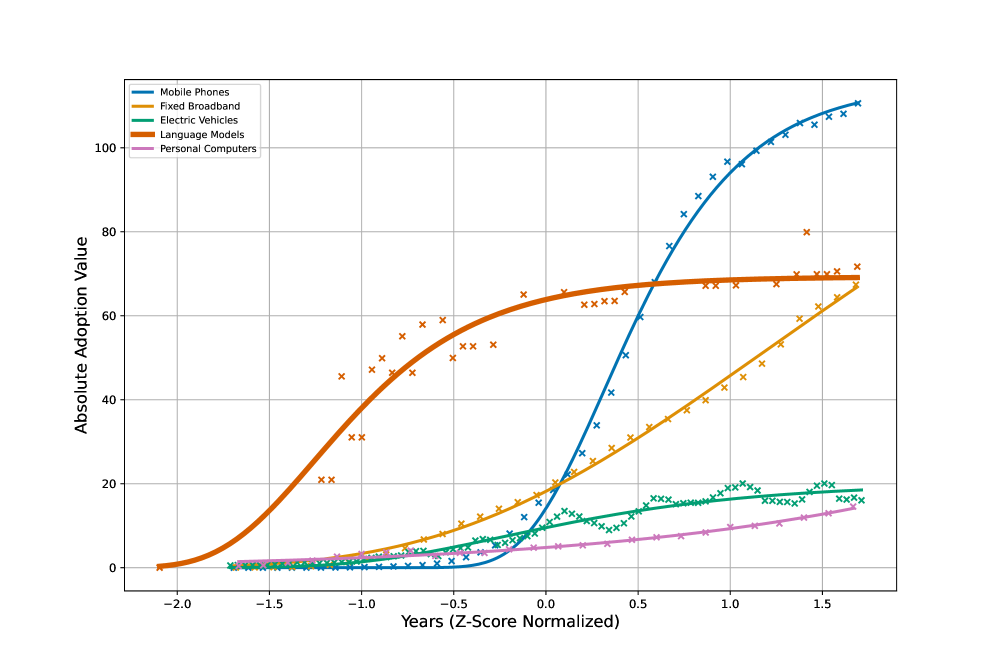
Исследование выявляет заметную иерархию в развитии языковых моделей искусственного интеллекта, где блага концентрируются лишь в узком круге языков. Эта концентрация, по сути, является проявлением цифрового разрыва, и данная работа предлагает метрику EQUATE для оценки готовности языков к внедрению ИИ. Как однажды заметил Дональд Дэвис: «Простота — это высшая степень совершенства». Эта фраза отражает стремление к ясности и эффективности, которые необходимы при создании действительно полезных технологий. Стремление к упрощению сложных систем позволяет обеспечить доступность и справедливость в распределении преимуществ от развития ИИ для максимально широкого круга языков и культур.
Что дальше?
Представленная работа, хотя и выявляет закономерности формирования новой лингвистической иерархии, лишь обнажает проблему, а не решает её. Индекс EQUATE — не панацея, а инструмент диагностики. Он фиксирует текущее положение, но не гарантирует будущей справедливости. Упрощение сложной реальности до единого числового показателя всегда сопряжено с риском, однако, отказ от попытки количественной оценки — еще больший грех против ясности.
Главный вопрос, требующий дальнейшего исследования, заключается не в том, как развивать языковые технологии для всех языков, а в том, нужно ли это делать в принципе. Закон Ципфа, проявляющийся и в этой сфере, неумолим: ресурсы всегда будут концентрироваться вокруг доминирующих языков. Попытки искусственно выровнять эту ситуацию могут оказаться не только неэффективными, но и контрпродуктивными, приводя к размыванию качества и удорожанию разработки.
Будущие исследования должны сосредоточиться на выявлении критической массы языковых ресурсов, необходимой для поддержания культурной идентичности в цифровую эпоху. Вместо погони за всеобщим охватом, возможно, более разумным будет сохранение и поддержка уникальности каждого языка, даже если он не станет объектом интенсивной разработки в области искусственного интеллекта. Сложность — не повод для упрощения, а призыв к осознанности.
Оригинал статьи: https://arxiv.org/pdf/2602.12018.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Искусственный интеллект на страже экологии: защита данных и справедливые алгоритмы
- Языковые модели и границы возможного: что делает язык человеческим?
- Разумные языковые модели: новый подход к логическому мышлению
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Новая формула для расчёта взаимодействий глюонов открывает горизонты для голографии пространства
- Взрыв скорости: Оптимизация внимания для современных GPU
- Конфиденциальный анализ больших данных: новый подход к быстрым ответам
2026-02-15 17:17