Автор: Денис Аветисян
Исследователи предлагают инновационный метод автоматического обнаружения научных моделей, основанный на возможностях больших языковых моделей и принципах вероятностного программирования.
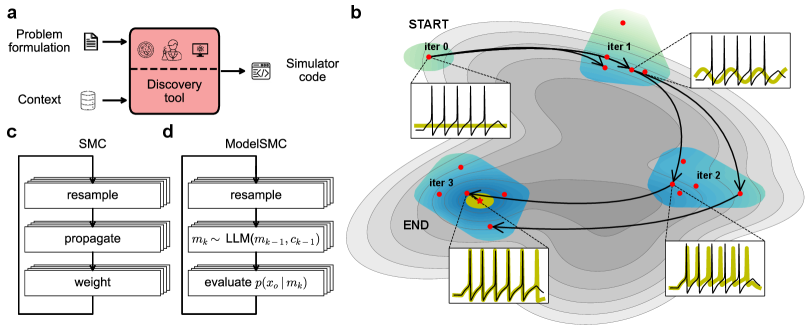
В статье представлена методика ModelSMC, использующая байесовский вывод и методы последовательного Монте-Карло для более надежного и интерпретируемого открытия моделей.
Автоматизированный поиск механистических моделей по данным наблюдения часто опирается на эвристические процедуры, не имеющие четкой вероятностной основы. В статье ‘A Probabilistic Framework for LLM-Based Model Discovery’ предложен новый подход, рассматривающий этот процесс как вероятностный вывод, где модели семплируются из неизвестного распределения, способного объяснить наблюдаемые данные. Ключевым результатом является алгоритм ModelSMC, использующий большие языковые модели и методы последовательного Монте-Карло для итеративной генерации, уточнения и взвешивания кандидатов в модели. Позволит ли такая формулировка создать более интерпретируемые и надежные модели, ускоряющие научные открытия?
Вызов Модельного Поиска
Традиционно, создание механистических моделей являлось сложной задачей, требующей глубоких знаний в конкретной области и значительных ручных усилий. Ученым приходилось тщательно анализировать данные, формулировать гипотезы о лежащих в основе процессах и вручную разрабатывать математические уравнения, описывающие эти взаимодействия. Этот процесс не только отнимал много времени и ресурсов, но и был подвержен субъективным искажениям, так как экспертные знания и интуиция исследователя оказывали существенное влияние на конечную модель. В результате, построение адекватных и точных моделей часто оказывалось дорогостоящим и трудоемким, что замедляло темпы научного прогресса и ограничивало возможности для проведения более глубоких исследований.
Процесс построения механистических моделей традиционно сопряжен со значительными временными и финансовыми затратами, а также подвержен субъективным искажениям. Это обусловлено необходимостью глубокой экспертной оценки и ручного труда на каждом этапе — от формулировки гипотез до валидации полученных результатов. Такая трудоемкость не только замедляет темпы научных открытий, но и ограничивает возможности всестороннего исследования сложных систем, поскольку доступ к ресурсам и экспертизе часто является препятствием. В результате, значительная часть потенциально ценных знаний может оставаться невостребованной, препятствуя прогрессу в различных областях науки и техники.
Автоматизированное Моделирование с Последовательным Монте-Карло
Метод последовательного Монте-Карло (SMC) представляет собой мощный вероятностный подход к задачам статистического вывода и выбора моделей. SMC основан на представлении апостериорного распределения вероятностей посредством набора взвешенных частиц, каждая из которых является гипотезой о значениях параметров модели. В процессе последовательного обновления частиц, их веса корректируются на основе наблюдаемых данных, что позволяет эффективно оценивать апостериорную вероятность различных моделей и параметров. Этот подход особенно полезен в задачах, где аналитическое решение невозможно из-за сложности модели или нелинейности наблюдаемых данных. Эффективность SMC обусловлена способностью адаптироваться к новым данным и фокусироваться на наиболее перспективных гипотезах, избегая необходимости полного пересчета распределения на каждом шаге.
Метод последовательного Монте-Карло (SMC) использует ансамбль частиц для приближенного представления сложных вероятностных распределений. Каждая частица представляет собой гипотезу о состоянии системы, а ее вес отражает ее правдоподобие, учитывая наблюдаемые данные. В процессе работы, частицы подвергаются последовательным операциям выбора, взвешивания и перевыборки, что позволяет сконцентрироваться на наиболее перспективных кандидатах — моделях или параметрах, которые наилучшим образом соответствуют данным. Вероятность каждой частицы обновляется на каждой итерации, основываясь на функции правдоподобия и априорном распределении, что позволяет эффективно исследовать пространство моделей и идентифицировать те, которые с наибольшей вероятностью объясняют наблюдаемые данные. p(x|y) \approx \frac{1}{N} \sum_{i=1}^{N} w_i \delta(x-x_i), где x — состояние системы, y — наблюдаемые данные, N — количество частиц, w_i — вес i-ой частицы, а δ — дельта-функция Дирака.
Интеграция метода последовательного Монте-Карло (SMC) с большими языковыми моделями (LLM) позволяет автоматизировать процесс поиска и разработки моделей. LLM используются для генерации и оценки реализаций моделей, в то время как SMC обеспечивает вероятностный каркас для выбора наиболее перспективных кандидатов. В рамках этого подхода, LLM синтезирует код модели на основе заданных требований, а SMC оценивает правдоподобие и точность каждой реализации, используя доступные данные. Этот итеративный процесс позволяет эффективно исследовать пространство моделей и идентифицировать оптимальные решения без непосредственного участия человека, что значительно ускоряет процесс моделирования и позволяет решать сложные задачи, требующие автоматизированного подбора и валидации моделей.

Оценка Соответствия и Эффективности Модели
Качество модели оценивается по её способности объяснять наблюдаемые данные, что количественно измеряется с помощью метрик, таких как ResamplingWeight. ResamplingWeight отражает вероятность того, что конкретная модель была выбрана из ансамбля моделей, учитывая наблюдаемые данные. Более высокие значения ResamplingWeight указывают на лучшую способность модели соответствовать данным и, следовательно, на более высокое качество модели. Этот показатель используется для взвешивания различных моделей в процессе Sequential Monte Carlo (SMC) и позволяет эффективно идентифицировать наиболее правдоподобные модели, соответствующие имеющимся данным.
Нейронная оценка правдоподобия (Neural Likelihood Estimation, NLE) и нейронная оценка апостериорного распределения (Neural Posterior Estimation, NPE) представляют собой эффективные методы аппроксимации функций правдоподобия и апостериорных распределений, что критически важно для реализации алгоритма последовательного Монте-Карло (SMC). Традиционные методы вычисления этих функций могут быть вычислительно затратными, особенно в сложных моделях. NLE и NPE используют нейронные сети для обучения аппроксимациям этих функций, что позволяет значительно сократить время вычислений и снизить вычислительные издержки при оценке правдоподобия и построении апостериорного распределения параметров модели. Это особенно важно для задач, требующих частого пересчета правдоподобия в рамках алгоритма SMC, таких как задачи байесовского вывода и оценки неопределенности.
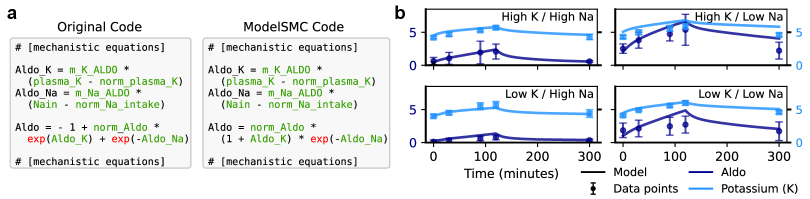
Эффективность ModelSMC была продемонстрирована на различных системах, моделирующих широкий спектр явлений. В частности, алгоритм успешно идентифицировал правдоподобные модели для HodgkinHuxleyModel, описывающей электрические свойства нейронов, SIRModel, моделирующей распространение инфекционных заболеваний, и PharmacologicalKidneyModel, детализирующей функционирование почек. Данные результаты подтверждают универсальность и применимость ModelSMC к задачам системной идентификации в различных областях науки и инженерии.
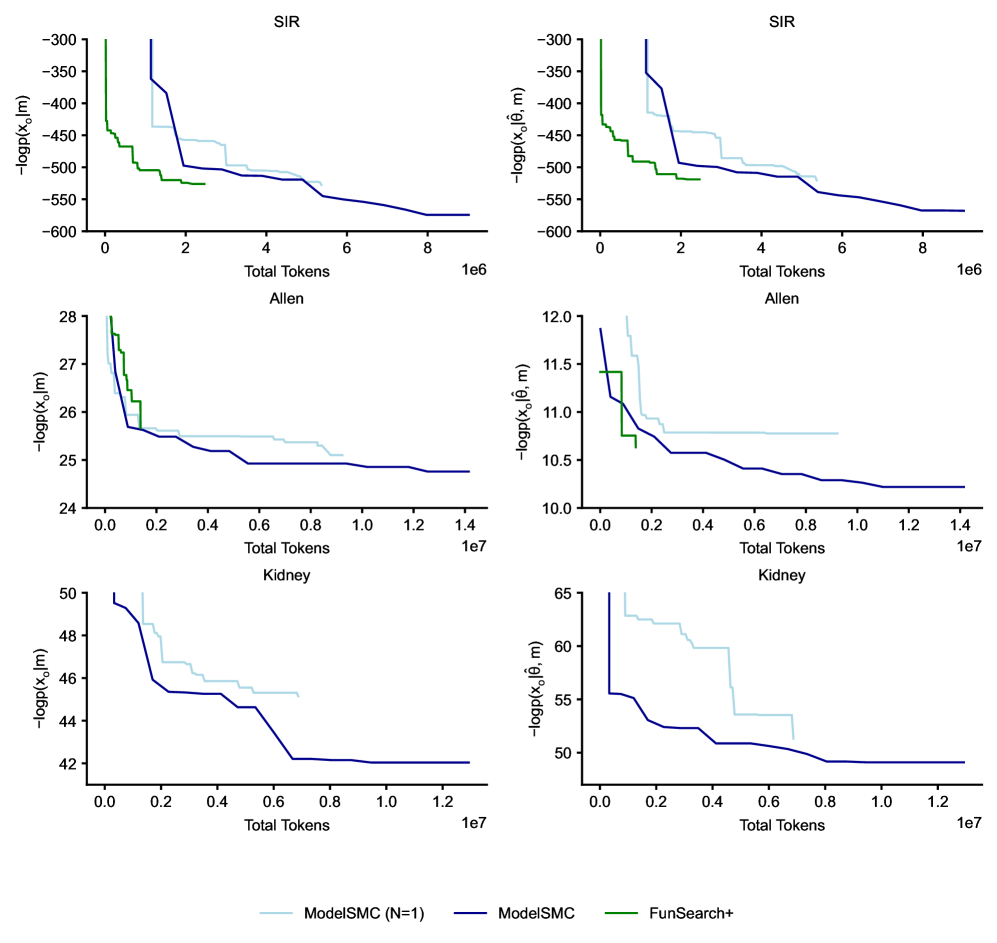
Эффективность автоматизированного процесса оценки моделей количественно оценивается показателем TokenUsage, отражающим вычислительные затраты. В ходе экспериментов с моделями SIR, Hodgkin-Huxley и PharmacologicalKidneyModel, ModelSMC демонстрирует сопоставимую производительность с базовыми методами, такими как FunSearch+ и ModelSMC NN=1, при аналогичном бюджете токенов. Это указывает на то, что ModelSMC обеспечивает конкурентоспособную эффективность при решении задач идентификации моделей в различных областях, сохраняя приемлемые вычислительные издержки.
В ходе оценки производительности ModelSMC было показано, что он достигает сопоставимого значения Negative Log Likelihood (NLL) на моделях SIR, Hodgkin-Huxley и PharmacologicalKidney, что свидетельствует о конкурентоспособности его эффективности. При этом, затраты на вычислительные ресурсы, измеряемые количеством использованных токенов (TokenUsage), остаются сопоставимыми с альтернативными методами, такими как FunSearch+ и ModelSMC NN=1. Достижение сравнимого NLL при аналогичном бюджете токенов подтверждает, что ModelSMC обеспечивает эффективное приближение к истинным значениям параметров моделей без значительного увеличения вычислительной сложности.
Влияние на Научные Открытия
Автоматизация процесса открытия моделей позволяет исследователям значительно расширить горизонты гипотез, которые можно изучить, и тем самым ускорить научный прогресс. Традиционно, поиск подходящей модели для объяснения наблюдаемых данных требовал значительных временных затрат и ручного труда. Теперь, благодаря новым методам, алгоритмы способны самостоятельно исследовать различные варианты, оценивать их соответствие данным и выявлять наиболее перспективные направления для дальнейшего изучения. Это особенно важно в областях, где количество возможных моделей огромно, а ручной анализ становится практически невозможным. В результате, ученые могут сосредоточиться на интерпретации полученных результатов и формулировке новых вопросов, а не тратить время на утомительный процесс поиска подходящей модели, что открывает новые возможности для прорывных открытий в различных научных дисциплинах.
Предложенная методология не ограничивается рамками конкретной научной дисциплины, демонстрируя высокую адаптивность к различным областям знаний. Благодаря гибкой архитектуре, она способна эффективно анализировать данные и генерировать новые знания в таких сферах, как астрофизика, материаловедение и даже социальные науки. Возможность автоматизированного поиска моделей и эффективной параметризации позволяет исследователям выявлять скрытые закономерности и строить более точные прогнозы, значительно расширяя горизонты научных открытий и способствуя прогрессу в самых разнообразных областях. Данный подход предоставляет мощный инструмент для обработки больших объемов данных и извлечения из них ценной информации, что особенно актуально в эпоху экспоненциального роста научных данных.
Подходы, подобные FunSearch, демонстрируют принципиально новый способ исследования пространства моделей, объединяя возможности больших языковых моделей (LLM) и алгоритма последовательного Монте-Карло (SMC). Вместо традиционного, строго детерминированного поиска, LLM выступают в роли генератора гипотез, предлагая нетривиальные варианты моделей, которые затем оцениваются и уточняются с помощью SMC. Этот симбиоз позволяет преодолеть ограничения, связанные с человеческой предвзятостью и ограниченностью воображения, открывая возможности для обнаружения неожиданных и эффективных решений в различных научных областях. Вместо того чтобы просто оптимизировать существующие модели, FunSearch стимулирует креативный поиск в пространстве возможностей, что потенциально приводит к прорывным открытиям, которые иначе могли бы остаться незамеченными.
Интегрированный подход к оценке параметров, предложенный в данной работе, значительно повышает точность и надежность получаемых моделей. Традиционные методы часто сталкиваются с трудностями при поиске оптимальных значений параметров в сложных системах, требуя значительных вычислительных ресурсов и времени. Данная методика, напротив, использует алгоритмы последовательного Монте-Карло (SMC) в сочетании с возможностями больших языковых моделей (LLM), что позволяет эффективно исследовать пространство параметров и находить наилучшие соответствия между моделью и экспериментальными данными. Это особенно важно в областях, где данные ограничены или зашумлены, поскольку позволяет снизить неопределенность и получить более достоверные результаты. В итоге, такая эффективная оценка параметров не только улучшает качество моделей, но и открывает новые возможности для прогнозирования и понимания сложных явлений в различных научных дисциплинах.
Исследование представляет собой интересный подход к автоматическому научному открытию, рассматривая его как вероятностный вывод. Авторы предлагают ModelSMC — систему, которая, используя большие языковые модели и методы последовательного Монте-Карло, позволяет проводить более надежный и интерпретируемый поиск моделей. Эта работа подчеркивает, что стабильность в системах — иллюзия, обусловленная временем, а задержка является неизбежной платой за каждый запрос. Как писал Блез Паскаль: «Все великие вещи требуют времени». Этот принцип применим и к ModelSMC, где итеративный характер алгоритма Sequential Monte Carlo требует времени для достижения оптимальных результатов, но в конечном итоге позволяет обнаружить более точные и надежные модели.
Куда же дальше?
Представленная работа, как и любая попытка автоматизировать творческий процесс, неизбежно обнажает границы применимости существующих инструментов. Разумеется, формализация научного открытия в рамках вероятностного вывода — элегантное решение, но оно лишь отодвигает вопрос о природе самой «элегантности». Система учится стареть достойно, выявляя вероятные модели, но истинная ценность научного поиска заключается не в скорости, а в способности удержать неопределенность.
Очевидно, что будущее таких систем — в интеграции с более широким спектром знаний и данных. Однако, не стоит стремиться к всеохвату любой ценой. Иногда лучше наблюдать за процессом, чем пытаться ускорить его. Более важным представляется развитие методов интерпретации полученных моделей, позволяющих ученым понять не только что система обнаружила, но и почему.
Мудрые системы не борются с энтропией — они учатся дышать вместе с ней. Следующим шагом, вероятно, станет разработка механизмов самокоррекции и адаптации, позволяющих системе учиться на собственных ошибках и постепенно совершенствовать свои алгоритмы поиска. Иногда наблюдение — единственная форма участия, и этого вполне достаточно.
Оригинал статьи: https://arxiv.org/pdf/2602.18266.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-23 17:44