Автор: Денис Аветисян
Исследователи предлагают принципиально новый подход к обработке языка, позволяющий повысить эффективность и качество логических выводов.
В статье представлена архитектура Dynamic Large Concept Models (DLCM), использующая иерархическое моделирование и динамическую сегментацию текста для оптимизации вычислений и улучшения концептуального рассуждения.
Несмотря на впечатляющие возможности больших языковых моделей, их равномерное применение вычислительных ресурсов ко всем токенам текста представляется неэффективным, учитывая неравномерную информационную плотность языка. В статье ‘Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space’ предложена новая иерархическая модель, Dynamic Large Concept Models (DLCM), перераспределяющая вычисления с токенов на сжатое концептуальное пространство для повышения эффективности рассуждений. DLCM обнаруживает переменные по длине концепты без использования предопределенных лингвистических единиц, что позволяет сформулировать закон масштабирования, учитывающий как токельную ёмкость, так и концептуальные возможности. Возможно ли, используя подобные адаптивные подходы, создать принципиально новые архитектуры языковых моделей, существенно превосходящие существующие по производительности и эффективности?
Преодолевая Узкое Место Токенизации
Современные большие языковые модели, основанные на архитектуре Transformer, обрабатывают язык на уровне токенов, что создает значительные вычислительные узкие места. Каждое слово или его часть разбивается на отдельные токены, и модель последовательно анализирует их один за другим. Этот подход, хотя и позволяет эффективно обрабатывать большие объемы текста, требует огромных вычислительных ресурсов, особенно при работе с длинными последовательностями. По мере увеличения количества токенов, необходимых для обработки, вычислительная сложность растет экспоненциально, что ограничивает возможности модели по глубокому анализу и пониманию контекста. В результате, даже самые мощные языковые модели сталкиваются с трудностями при обработке сложных предложений или длинных текстов, что подчеркивает необходимость поиска более эффективных методов представления и обработки информации.
Последовательная обработка языка токен за токеном, характерная для современных больших языковых моделей, существенно ограничивает глубину рассуждений и способность улавливать связи между удаленными элементами текста. Данный подход создает трудности при понимании сложных предложений и длинных отрывков, поскольку модель вынуждена обрабатывать информацию последовательно, не имея возможности одновременно учитывать весь контекст. Это особенно заметно при решении задач, требующих установления причинно-следственных связей или выявления скрытых смыслов, где игнорирование долгосрочных зависимостей приводит к неточным или неполным выводам. В результате, эффективность понимания текста, особенно при работе с большими объемами информации, значительно снижается, подчеркивая необходимость разработки альтернативных методов обработки, способных преодолеть эти ограничения.
По мере увеличения масштаба языковых моделей, построенных на архитектуре Transformer, неэффективность обработки на уровне токенов становится все более выраженной. Увеличение числа параметров не только требует экспоненциального роста вычислительных ресурсов, но и усугубляет проблему “узкого горлышка”, препятствуя глубокому рассуждению и удержанию долгосрочных зависимостей в тексте. Это создает потребность в принципиально новых подходах к представлению информации, которые позволят перейти от обработки отдельных токенов к более абстрактным и компактным формам, способным эффективно кодировать смысл и контекст. Исследования в этой области направлены на разработку методов, позволяющих моделировать язык не как последовательность символов, а как сеть взаимосвязанных концепций, что обещает значительное повышение эффективности и способности к обобщению.
DLCM: Переход к Переменной Длине Концептов
Традиционная обработка последовательностей токенами имеет ограничения, связанные с неспособностью учитывать семантическую целостность фрагментов текста. DLCM (Discrete Latent Concept Model) решает эту проблему путем обучения модели определять семантические границы внутри последовательности. Это достигается путем выявления точек, где меняется семантический контекст, позволяя модели разбивать входную последовательность на более значимые единицы, чем отдельные токены. Идентификация этих границ является ключевым этапом в процессе формирования концептуальных векторов, представляющих собой семантические единицы, что позволяет модели оперировать более абстрактными и осмысленными представлениями данных.
Определение семантических границ позволяет реализовать сжатие последовательностей (Sequence Compression) путем объединения токенов в концептуальные векторы переменной длины. Эти векторы представляют собой семантические единицы, формируемые на основе выявленных границ. В отличие от обработки отдельных токенов, формирование концептуальных векторов позволяет объединить несколько токенов, объединенных по смыслу, в единый вектор, тем самым уменьшая размер входной последовательности и объем вычислений. Длина каждого вектора зависит от длины семантической единицы, что обеспечивает гибкость и адаптацию к различным структурам текста.
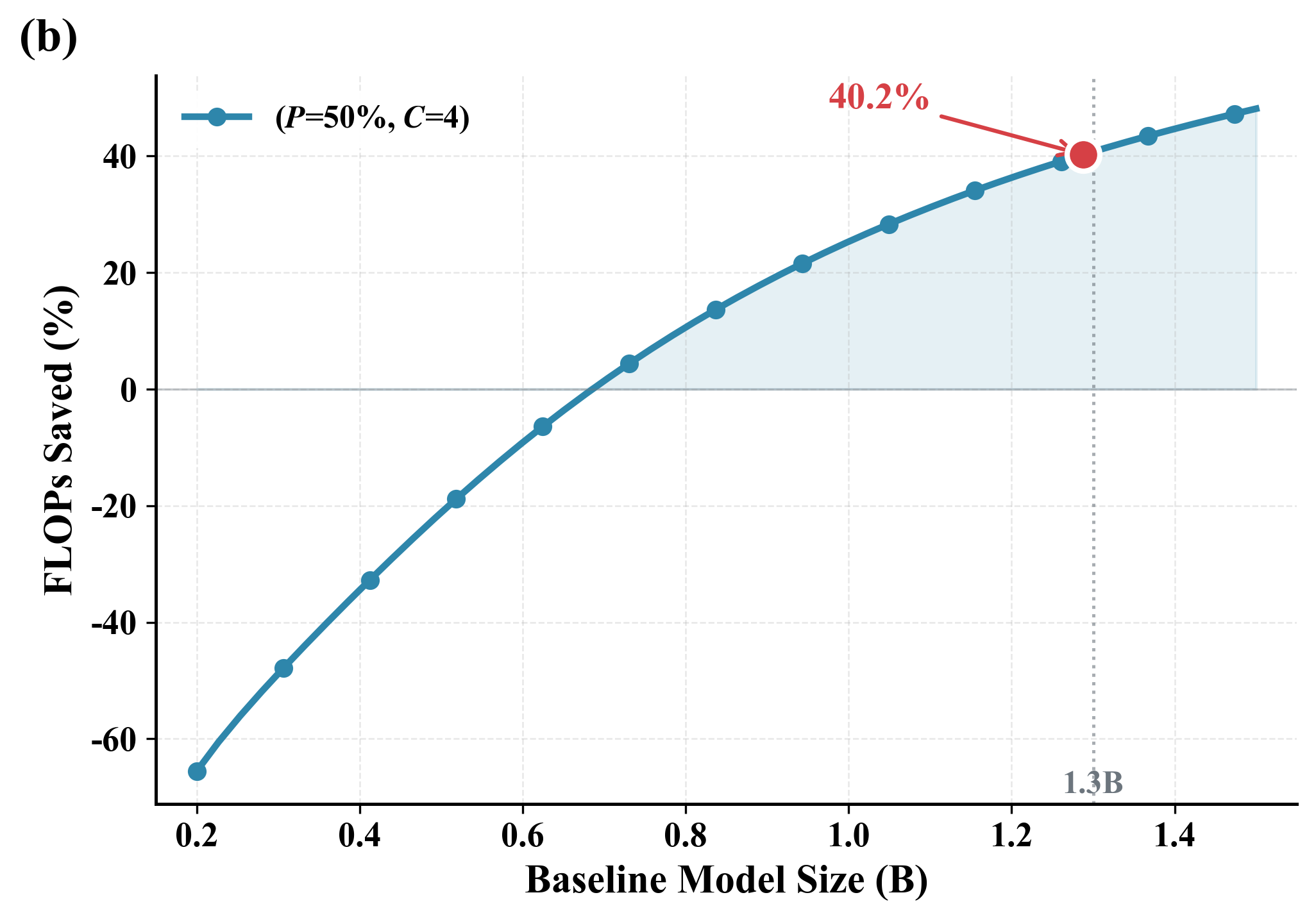
Использование концептов вместо отдельных токенов в DLCM позволяет значительно снизить вычислительную нагрузку и повысить глубину рассуждений. Вместо обработки каждого токена последовательности, DLCM оперирует с семантически значимыми единицами — векторами концептов. Это приводит к уменьшению количества операций с плавающей точкой (FLOPs) — до 34% при коэффициенте сжатия R=4. Снижение вычислительной сложности достигается за счет уменьшения размерности обрабатываемых данных, позволяя модели эффективнее анализировать и понимать семантическое содержание последовательности.
Стабилизация Обучения с Продвинутыми Методами
DLCM использует параметризацию максимальных обновлений (MuP) для стабилизации процесса обучения в своей гетерогенной архитектуре. MuP позволяет отделить обновление параметров различных компонентов модели, что предотвращает взаимное влияние и снижает вероятность расхождения обучения. Данный подход особенно важен в DLCM, где компоненты имеют различную сложность и функциональность. Отделяя обновления, MuP позволяет более эффективно оптимизировать каждый компонент, обеспечивая стабильность и ускорение сходимости обучения, а также повышая общую производительность модели. В частности, MuP позволяет использовать разные скорости обучения для разных частей модели, адаптируясь к их специфическим требованиям.
Глобальный парсер в DLCM функционирует как стратегия регуляризации, вычисляя статистику сжатия для уточнения предсказаний границ. Этот процесс включает в себя анализ сжатых представлений данных, что позволяет модели оценивать информативность различных сегментов последовательности. На основе вычисленных статистик, парсер вносит корректировки в процесс предсказания границ, снижая переобучение и улучшая обобщающую способность модели. Вычисление статистики сжатия предоставляет меру избыточности данных, позволяя модели сосредоточиться на наиболее значимых элементах при определении границ между сегментами.
Для повышения эффективности вычислений в DLCM реализована интеграция Flash Attention Varlen, механизма, оптимизированного для обработки последовательностей переменной длины. Flash Attention Varlen значительно ускоряет процесс обработки, используя технику tiling и переупорядочивания вычислений для минимизации операций чтения/записи из глобальной памяти. Это особенно важно при работе с длинными последовательностями, характерными для задач обработки естественного языка и анализа временных рядов, где стандартные механизмы внимания могут создавать узкие места производительности. За счет уменьшения требований к памяти и оптимизации доступа к ней, Flash Attention Varlen позволяет обрабатывать более длинные последовательности с меньшими задержками и более высокой пропускной способностью.
Производительность и Масштабируемость: Новая Парадигма
Разработанная система DLCM демонстрирует значительное повышение вычислительной эффективности за счет обработки сжатых последовательностей данных. Вместо работы с полным объемом информации, система оперирует её компактным представлением, что существенно снижает требования к объему памяти и вычислительной мощности. Этот подход позволяет DLCM обрабатывать более крупные наборы данных и выполнять сложные вычисления быстрее, чем традиционные методы, не жертвуя при этом точностью результатов. Уменьшение нагрузки на ресурсы делает систему особенно привлекательной для применения на устройствах с ограниченными возможностями, а также для масштабных вычислений, где оптимизация ресурсов является критически важной.
В основе DLCM лежит способность к концептуальному рассуждению, что позволяет системе выходить за рамки простого сопоставления данных и осуществлять более глубокое понимание информации. Вместо обработки последовательностей на уровне отдельных токенов, DLCM оперирует концептами, что обеспечивает более точные прогнозы и, как следствие, повышение средней точности на 2.69% при тестировании на 12 задачах, где модель не проходила предварительное обучение (zero-shot benchmarks). Этот подход позволяет системе обобщать знания и успешно применять их к новым, ранее не встречавшимся ситуациям, демонстрируя значительный прогресс в области искусственного интеллекта и обработки естественного языка.
В основе повышения эффективности разработанной системы лежит следование принципам закона масштабирования, что позволяет оптимизировать распределение ресурсов и обеспечивать непрерывное улучшение результатов по мере увеличения объема данных. Исследования показали, что при увеличении объема обучающей информации, точность работы системы стабильно возрастает, демонстрируя прирост показателей от 1.64% до 3.00% на сложных эталонных задачах, таких как CommonsenseQA, OpenBookQA и ARC Challenge. Такой подход гарантирует не только текущую высокую производительность, но и потенциал для дальнейшего развития и совершенствования системы по мере поступления новых данных, что делает ее перспективным решением для задач, требующих глубокого логического мышления и анализа.

За Пределами Токенов: Будущее Языкового ИИ
Подход DLCM, основанный на концептах, представляет собой принципиально новый путь к достижению более человекоподобного понимания языка. В отличие от традиционных моделей, оперирующих токенами, DLCM стремится воспроизвести когнитивные процессы мозга, его способность к абстракции и сжатию информации. Этот механизм позволяет выделить ключевые концепты из текста, создавая компактное и эффективное представление смысла. Подобно тому, как человек не запоминает каждое слово, а оперирует общими идеями, DLCM формирует обобщенные представления, что потенциально обеспечивает более глубокое понимание контекста и сложных взаимосвязей в тексте. Такой подход позволяет не просто распознавать слова, но и понимать что они значат, открывая возможности для создания искусственного интеллекта, способного к более осмысленному и гибкому взаимодействию с языком.
Предлагаемая концептуальная структура открывает значительные перспективы в различных областях искусственного интеллекта. В частности, она способна качественно улучшить генерацию текстов большого объема, позволяя создавать более связные и логичные повествования, выходящие за рамки простого комбинирования токенов. Более того, данный подход обещает прогресс в сфере сложного рассуждения, предоставляя системам возможность анализировать информацию на более глубоком семантическом уровне и делать обоснованные выводы. Не менее важным является потенциал в области эффективного представления знаний — концептуальная организация информации позволяет сжимать данные, сохраняя при этом ключевые смысловые связи, что ведет к повышению производительности и снижению требований к вычислительным ресурсам.
Предстоящие исследования направлены на усовершенствование процесса определения границ концептов в рамках DLCM, что является ключевым для повышения точности и эффективности модели. Особое внимание уделяется разработке алгоритмов, способных более гибко и надежно выделять смысловые единицы из потока информации. Помимо этого, планируется активное изучение возможностей интеграции DLCM с другими модальностями искусственного интеллекта, такими как компьютерное зрение и обработка звука. Такое объединение позволит создать системы, способные комплексно воспринимать и интерпретировать информацию, приближая их к человеческому уровню понимания и взаимодействия с окружающим миром. Ожидается, что синергия DLCM с другими ИИ-технологиями откроет новые перспективы в разработке интеллектуальных систем, способных решать сложные задачи в различных областях.
Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных к адаптации и эффективной обработке информации на концептуальном уровне. Этот подход, фокусирующийся на динамической сегментации и иерархическом моделировании, перекликается с идеей о том, что устойчивость системы определяется не её статичной структурой, а способностью к медленным, постепенным изменениям. Андрей Колмогоров отмечал: «Математика — это искусство открывать закономерности в кажущемся хаосе». В контексте DLCM, концептуальный уровень обработки текста можно рассматривать как попытку выявления этих закономерностей, что позволяет снизить вычислительную сложность и повысить эффективность модели, делая её более приспособленной к постоянно меняющемуся информационному потоку.
Куда же дальше?
Представленная работа, касающаяся динамических концептуальных моделей, лишь осторожно приоткрывает дверь в пространство, где вычислительная эффективность не является антагонистом, а скорее, союзником глубинного семантического анализа. Очевидно, что переход к обработке текста на уровне концептов, а не токенов, позволяет снизить вычислительную нагрузку, но цена этого упрощения — потенциальная потеря нюансов, тонкостей, которые и составляют суть человеческого языка. Все системы стареют — и каждая архитектура, даже самая элегантная, обречена на накопление «технического долга» в виде неизбежных приближений.
Наиболее сложной задачей представляется не столько масштабирование предложенного подхода, сколько разработка надежных механизмов для динамической сегментации и адаптации семантического пространства. Как обеспечить, чтобы модель не «забывала» контекст, не теряла способность к обобщению, и, главное, — не начала конструировать собственную, искаженную версию реальности? Время — не метрика, а среда, в которой существуют системы, и любое вмешательство в эту среду влечет за собой непредвиденные последствия.
В конечном итоге, истинный прогресс в области языковых моделей будет заключаться не в увеличении их размера или скорости, а в углублении понимания принципов, лежащих в основе человеческого мышления. И, возможно, стоит признать, что некоторые упрощения — неизбежны, и лишь вопрос в том, как достойно с ними жить.
Оригинал статьи: https://arxiv.org/pdf/2512.24617.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые прорывы: Хорошее, плохое и смешное
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-02 07:51