Автор: Денис Аветисян
Новое исследование показывает, что современные языковые модели способны усваивать информацию о новых задачах, но испытывают трудности с ее практическим применением для гибкого решения проблем.
Несмотря на способность к обучению в контексте, языковые модели демонстрируют ограниченность в использовании полученных представлений для адаптивного рассуждения и решения задач.
Несмотря на значительные успехи больших языковых моделей (LLM) в решении широкого спектра задач, их способность к адаптации к принципиально новым контекстам остается ограниченной. В работе ‘Language Models Struggle to Use Representations Learned In-Context’ исследуется, насколько эффективно LLM могут использовать представления, сформированные на основе контекстной информации. Полученные результаты демонстрируют, что, несмотря на способность кодировать новую семантику в контексте, LLM испытывают трудности с ее применением для гибкого решения задач и адаптации к изменяющимся условиям. Какие новые подходы позволят создать модели, способные не только запоминать, но и эффективно использовать информацию, полученную в процессе обучения?
За пределами предсказания: рождение мировых моделей
Традиционные языковые модели демонстрируют впечатляющую способность предсказывать следующее слово в последовательности, однако эта функция базируется на статистическом анализе, а не на глубоком понимании окружающего мира. Они оперируют вероятностями появления слов, выученными на огромных объемах текста, но не формируют внутреннего представления о предметах, их свойствах и взаимосвязях. В результате, модели способны генерировать грамматически корректный и контекстуально уместный текст, но часто не обладают способностью к логическим умозаключениям или решению проблем, требующих понимания причинно-следственных связей. Их «знание» мира ограничивается информацией, заложенной в обучающих данных, и не включает в себя активное построение и проверку гипотез о реальности.
Несмотря на впечатляющий прогресс в увеличении размеров языковых моделей, простое наращивание параметров не является ключом к настоящему интеллекту. Исследования показывают, что модели, способные лишь распознавать статистические закономерности в данных, сталкиваются с ограничениями в решении задач, требующих понимания взаимосвязей между объектами и явлениями. Истинный интеллект предполагает способность к абстрагированию, обобщению и построению внутренних моделей мира, позволяющих делать выводы и предсказывать последствия действий, а не просто воспроизводить заученные последовательности. Таким образом, развитие способности к пониманию отношений, а не только паттернов, является критически важным шагом на пути к созданию действительно разумных систем.
Разработка внутренних “Мировых Моделей” представляет собой попытку выйти за рамки простого предсказания следующего слова, стремясь наделить языковые модели способностью к логическому выводу и прогнозированию, основанному на понимании взаимосвязей в окружающем мире. Вместо запоминания статистических закономерностей в тексте, такие модели стремятся создать внутреннюю репрезентацию реальности, позволяющую им не только завершать предложения, но и делать умозаключения о неявных последствиях действий, предсказывать развитие событий и даже планировать собственные действия в виртуальной среде. Это достигается путем обучения моделей не просто на текстовых данных, а на данных, описывающих взаимодействия объектов и субъектов, позволяя им формировать абстрактное представление о причинно-следственных связях и принципах функционирования мира, что является ключевым шагом к созданию действительно интеллектуальных систем.
Обучение в контексте: путь к гибкому представлению
Обучение с примерами в контексте (In-Context Learning, ICL) представляет собой перспективный подход к быстрой адаптации языковых моделей к новым задачам. Вместо традиционной тонкой настройки, требующей обновления параметров модели, ICL использует предоставленные в запросе примеры входных данных и соответствующих выходных результатов. Модель анализирует эти примеры непосредственно в контексте текущего запроса и, основываясь на выявленных закономерностях, генерирует ответ, соответствующий заданной задаче. Это позволяет модели демонстрировать новые возможности и представления без изменения ее внутренних параметров, обеспечивая гибкость и оперативность в применении к разнообразным задачам.
В отличие от традиционных методов обучения, требующих обновления параметров модели для адаптации к новым задачам, обучение в контексте (In-Context Learning, ICL) позволяет развертывать новые поведения и представления без модификации весов модели. Это достигается путем предоставления модели примеров желаемого поведения непосредственно в запросе, что позволяет ей быстро адаптироваться к новым задачам, не требуя дорогостоящих и трудоемких процессов переобучения. Такая особенность ICL обеспечивает гибкость развертывания и позволяет использовать одну и ту же модель для широкого спектра задач без необходимости ее повторной настройки для каждой из них.
Оценка эффективности обучения в контексте (In-Context Learning, ICL) требует разработки задач, специально предназначенных для проверки способности модели к изучению и использованию представлений в динамически изменяющейся среде. Эти задачи должны выходить за рамки простого распознавания паттернов и требовать от модели адаптации к новым данным и контексту непосредственно в процессе обработки запроса. Важно, чтобы оценивающие наборы данных содержали вариативность в представлении информации и требовали от модели обобщения знаний, полученных из примеров в контексте, на новые, ранее не встречавшиеся случаи. Для точной оценки необходимо учитывать такие параметры, как количество примеров в контексте, их релевантность и порядок, а также сложность самой задачи и степень новизны представленных данных.
Проверка качества представлений: задача трассировки графа
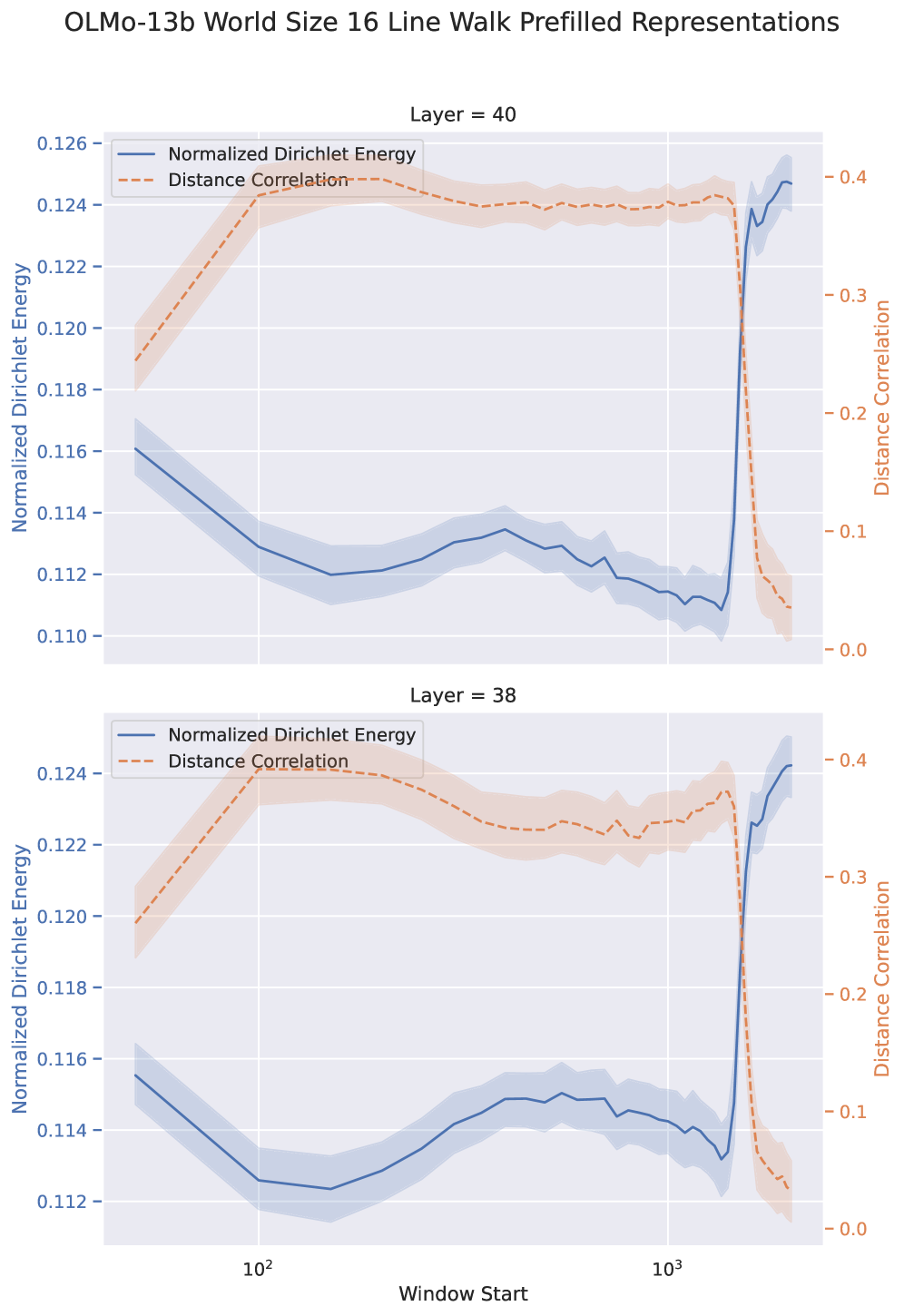
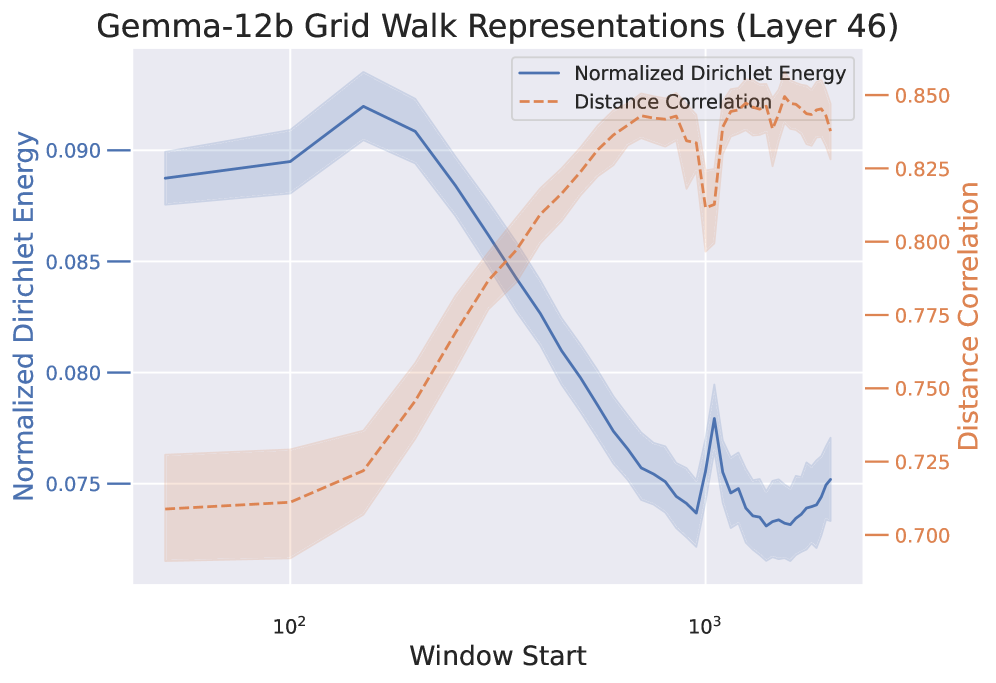
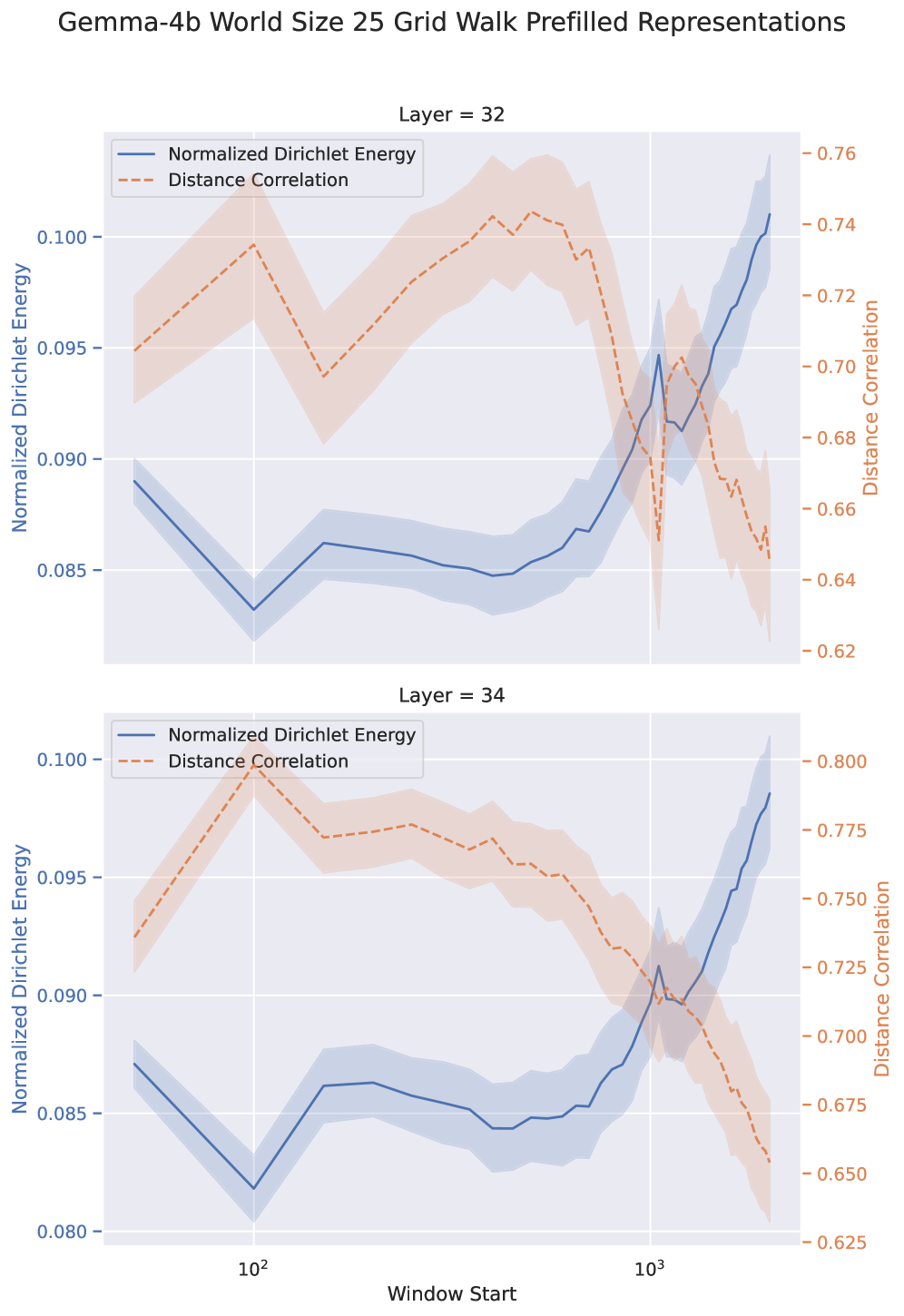
Задача прослеживания графа предоставляет контролируемую среду для оценки способности языковых моделей изучать и использовать представления, закодированные в запросе. В рамках этой задачи, модель получает последовательность состояний и должна предсказать следующее состояние, основываясь на предыдущих. Контролируемый характер задачи позволяет исследователям изолировать и оценить качество внутренних представлений модели, а не влияние других факторов, таких как сложность задачи или объем данных. Это достигается путем создания графа состояний, где узлы представляют состояния, а ребра — переходы между ними, что позволяет количественно оценить, насколько хорошо модель отражает структуру этого графа в своих представлениях.
Для оценки того, приводит ли обучение с примерами (In-Context Learning, ICL) к формированию осмысленных представлений, исследователи используют задачу прослеживания случайных блужданий в латентном пространстве состояний. Суть метода заключается в генерации случайных последовательностей состояний и последующей оценке способности языковой модели предсказывать следующее состояние в последовательности, основываясь на закодированном контексте. Низкая точность предсказания указывает на то, что модель не сформировала эффективные представления, отражающие структуру латентного пространства, в то время как высокая точность свидетельствует о наличии осмысленных представлений, полученных в процессе ICL. Данный подход позволяет количественно оценить качество представлений, формируемых моделью, без необходимости явного определения семантического значения каждого состояния.
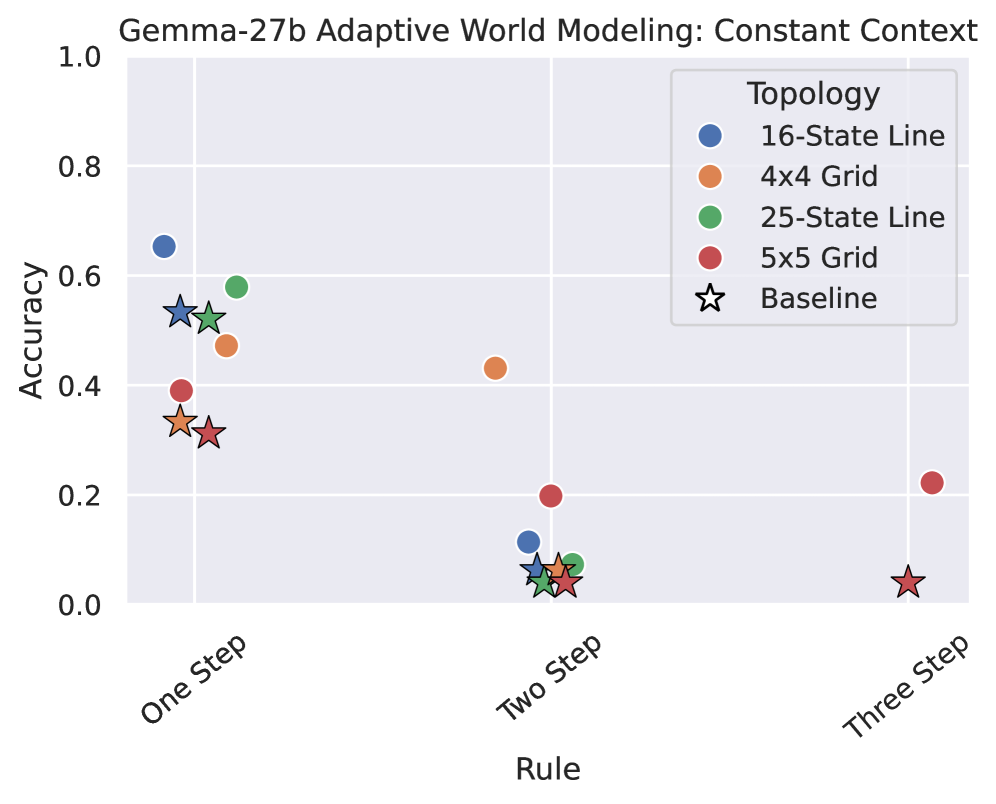
Анализ корреляции между расстояниями в пространстве представлений и базовым пространством состояний, осуществляемый с использованием метрик, таких как корреляция расстояний (Distance Correlation), позволяет оценить достоверность (fidelity) изученных представлений. Несмотря на то, что модели демонстрируют способность кодировать топологию пространства состояний, их точность на задаче адаптивного моделирования мира (Adaptive World Modeling, AWM) не превышает 50%. Это указывает на то, что хотя модели и способны улавливать общую структуру данных, они испытывают трудности с точным воспроизведением или использованием этой информации для решения конкретных задач, требующих высокой точности прогнозирования состояний.
Контекст и адаптивность: масштабирование семантики в контексте
Фундаментальным ограничением языковых моделей является длина контекста — объем информации, который они способны обработать одновременно. Этот параметр определяет, насколько сложную и детализированную задачу модель может решить, опираясь на предоставленные данные. В отличие от человеческого восприятия, которое способно адаптироваться и фокусироваться на наиболее релевантных деталях, языковые модели ограничены фиксированным «окном» внимания. Превышение этого лимита приводит к потере информации из начала контекста, что существенно снижает качество генерации или анализа текста. Поэтому, увеличение длины контекста является ключевой задачей в развитии современных языковых моделей, позволяющей им лучше понимать сложные взаимосвязи и генерировать более связные и осмысленные тексты, однако, это сопряжено со значительными вычислительными затратами и требует разработки новых алгоритмов для эффективной обработки больших объемов данных.
Адаптивное моделирование мира углубляет понимание возможностей языковых моделей, исследуя, насколько эффективно они способны применять совершенно новые значения и концепции в рамках заданного контекста. Вместо простого запоминания и воспроизведения информации, модели подвергаются проверке на способность гибко адаптироваться к незнакомым семантическим пространствам, которые вводятся непосредственно в запрос. Это предполагает, что оценка ограничивается не только точностью предсказания следующего токена, но и способностью модели интегрировать и использовать новые понятия, не нарушая при этом целостность и когерентность генерируемого текста. Исследования в этой области направлены на определение пределов этой адаптивности и выявление факторов, которые способствуют или препятствуют успешному развертыванию новых семантических структур в рамках ограниченного контекстного окна.
Исследования в области обучения обучению (metalearning) направлены на повышение эффективности обучения в контексте (ICL), позволяя моделям не просто запоминать информацию, но и адаптироваться к новым задачам непосредственно в процессе работы. Однако, проведенное исследование выявило неожиданный результат: при представлении модели случайного блуждания в качестве части входных данных, точность предсказания следующего токена значительно снижается. Коэффициент энергии Дирихле (DE Ratio), оказавшийся меньше единицы, указывает на то, что полученные модели демонстрируют инертность усвоенных представлений, то есть, несмотря на потенциал адаптации, способность к эффективному обучению в контексте остается ограниченной. Данный факт подчеркивает сложность разработки действительно гибких и обучаемых моделей, способных эффективно использовать новые знания, представленные в контексте.
Исследование демонстрирует, что большие языковые модели способны кодировать информацию об окружающей среде в процессе обучения, однако испытывают трудности с применением этих представлений для гибкого решения задач. Этот процесс напоминает попытку собрать сложный механизм, обладая лишь схематичным пониманием его работы. Андрей Колмогоров однажды заметил: «Математика — это искусство находить закономерности в хаосе». В данном контексте, модели способны улавливать закономерности (кодировать информацию), но не всегда способны эффективно применять их в новых ситуациях, что подчеркивает разрыв между просто кодированием и адаптивным рассуждением, ключевой проблемой, исследуемой в статье. Обучение моделей требует не только запоминания информации, но и способности к её творческому применению.
Куда Ведет Этот Лабиринт?
Исследование, представленное в данной работе, обнажает любопытный парадокс: языковые модели способны аккумулировать информацию о новых средах, но испытывают затруднения в ее эффективном применении для адаптивного рассуждения. Это напоминает о том, что простое кодирование данных — лишь половина дела; истинное понимание требует способности к гибкой манипуляции этими данными, а не просто их пассивного хранения. По сути, модели учатся видеть карту, но не умеют по ней ходить.
Будущие исследования должны сосредоточиться не только на увеличении размера моделей или сложности архитектур, но и на разработке механизмов, позволяющих им выделять действительно значимые признаки из контекста и формировать устойчивые, обобщенные представления. Попытки «взломать» существующие модели, выявить узкие места в их способности к адаптации, могут оказаться более плодотворными, чем слепое наращивание вычислительных мощностей. Хаос, проявляющийся в неспособности моделей к гибкому применению знаний, — это не ошибка, а отражение внутренней архитектуры, намекающее на скрытые связи и потенциальные пути для улучшения.
Вероятно, настоящим прорывом станет создание моделей, способных к саморефлексии — к осознанию собственных ограничений и активному поиску способов их преодоления. Иначе говоря, модели, которые не просто решают задачи, но и учатся на своих ошибках, перестраивая внутренние представления о мире. В конечном итоге, задача состоит не в том, чтобы создать искусственный интеллект, имитирующий человеческий, а в том, чтобы понять принципы работы интеллекта вообще, пусть даже это потребует разрушения существующих парадигм.
Оригинал статьи: https://arxiv.org/pdf/2602.04212.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Искусственный интеллект в медицине: новый уровень самостоятельности
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Квантовые маршруты и гравитационные сенсоры: немного иронии от физика
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
2026-02-05 16:39