Автор: Денис Аветисян
Новый подход, объединяющий обучение с подкреплением и регрессию на основе генеративных моделей, позволяет значительно повысить точность численных прогнозов.
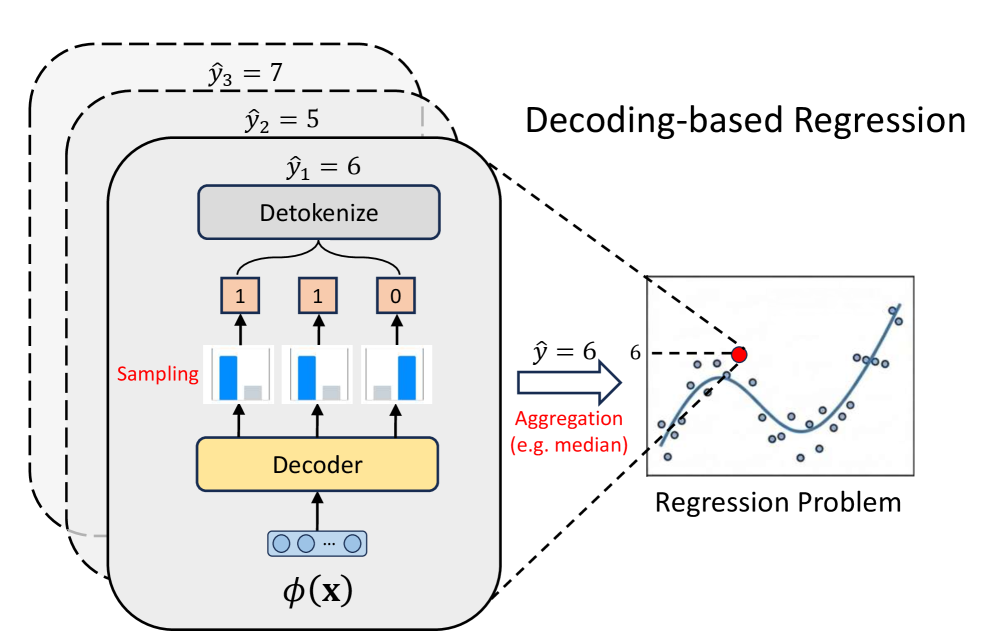
В статье представлена модель Generative Reinforced Regressor (GenRe2), использующая обучение с подкреплением и последовательные награды для улучшения регрессии на основе генерации.
Несмотря на перспективность подхода, преобразующего регрессию в задачу генерации последовательностей, традиционные методы обучения, ориентированные на токеновую точность, зачастую упускают из виду общую числовую согласованность. В работе ‘Beyond Token-level Supervision: Unlocking the Potential of Decoding-based Regression via Reinforcement Learning’ предложен новый подход, использующий обучение с подкреплением и последовательные награды для улучшения декодируемой регрессии. Данный метод позволяет добиться более высокой точности и эффективности выборки по сравнению с существующими подходами и традиционными регрессионными моделями. Способны ли подобные методы обучения с подкреплением открыть путь к созданию универсальных и надежных моделей для численного предсказания?
Пределы Традиционной Регрессии: Поиск Математической Чистоты
Традиционные методы регрессии, такие как гауссовские процессы и модели на основе деревьев, зачастую демонстрируют ограниченную эффективность при работе со сложными, многомерными данными. Проблема заключается в том, что эти алгоритмы испытывают трудности с захватом нелинейных зависимостей и взаимодействий между признаками, особенно когда количество признаков значительно превышает объем доступных данных. Это приводит к переобучению, снижению обобщающей способности модели и, как следствие, к ухудшению точности прогнозов. В условиях экспоненциального роста объемов данных и сложности задач, необходимость в более эффективных подходах к регрессионному анализу становится все более очевидной, подталкивая исследователей к поиску альтернативных парадигм и методов.
Традиционные методы регрессии, такие как гауссовские процессы и модели, основанные на деревьях решений, зачастую демонстрируют ограниченные возможности при моделировании сложных взаимосвязей в данных. Неспособность уловить тонкие, нелинейные зависимости приводит к снижению точности прогнозов, особенно при работе с высокоразмерными наборами данных. Это связано с тем, что данные, содержащие скрытые факторы или сложные взаимодействия между признаками, могут не быть адекватно представлены линейными или простыми нелинейными моделями. В результате, предсказания, полученные с помощью этих методов, могут содержать значительную погрешность и не отражать реальную картину, что особенно критично в задачах, требующих высокой степени надежности и точности, например, в медицине или финансах. Поэтому, для анализа таких данных требуются более сложные и гибкие подходы.
Появление глубокого обучения и обучения представлениям значительно улучшило возможности регрессионного анализа, особенно при работе со сложными данными. Однако, эти методы привнесли новые трудности, связанные с интерпретируемостью и эффективностью вычислений. Модели глубокого обучения, хотя и способны выявлять сложные закономерности, часто функционируют как “черные ящики”, что затрудняет понимание причинно-следственных связей и обоснование прогнозов. Кроме того, обучение и применение таких моделей требует значительных вычислительных ресурсов и больших объемов данных, что ограничивает их применимость в условиях ограниченных ресурсов или при небольшом размере выборки. Необходимость баланса между точностью, интерпретируемостью и вычислительной эффективностью становится ключевой задачей при выборе подходящего метода регрессионного анализа.
Ограничения традиционных методов регрессии, таких как гауссовские процессы и древовидные модели, при работе со сложными и многомерными данными, стимулировали поиск альтернативных подходов к решению регрессионных задач. Ученые обратились к парадигмам, выходящим за рамки стандартных алгоритмов, чтобы преодолеть проблемы, связанные с моделированием тонких взаимосвязей и обеспечением высокой точности прогнозирования. Исследования в области непараметрических методов, основанных на ядре, и алгоритмов, использующих идеи обучения представлений, позволили добиться определенных успехов. Однако, параллельно с этим возникла необходимость в разработке новых метрик и инструментов для оценки качества и интерпретируемости полученных моделей, что подчеркивает сложность и многогранность данной области исследований. Развитие этих альтернативных подходов открывает новые возможности для анализа данных и прогнозирования в различных областях науки и техники.

Декодирование Регрессии: Новый Подход к Точности
Метод регрессии на основе декодирования переформулирует задачу непрерывного предсказания как задачу генерации дискретной последовательности, используя возможности больших языковых моделей (LLM). Вместо прямого предсказания числового значения, модель генерирует последовательность токенов, представляющих это значение. Этот подход позволяет использовать LLM, обученные на обработке естественного языка, для решения задач регрессии, что открывает новые возможности для использования их способности к обобщению и пониманию контекста. Фактически, непрерывная величина преобразуется в дискретное представление, которое затем может быть сгенерировано моделью, подобно генерации текста.
Для представления непрерывных значений в дискретный вид, подход Decoding-Based Regression использует различные методы токенизации. IEEE Tokenization кодирует значения с плавающей точкой в дискретные токены, используя стандарт IEEE 754. P10 Tokenization применяет равномерное квантование, разделяя диапазон значений на 10000 интервалов и присваивая каждому интервалу уникальный токен. Normalized Tokenization нормализует входные данные к диапазону $[0, 1]$ и затем применяет равномерное квантование, что позволяет эффективно обрабатывать данные с разным масштабом. Все эти методы преобразуют непрерывные значения в дискретные токены, пригодные для обработки языковыми моделями, что позволяет применять методы, разработанные для задач генерации последовательностей.
Преобразование задачи регрессии в задачу генерации последовательностей позволяет использовать функцию потерь Cross-Entropy (CE), являющуюся ключевым элементом в моделях последовательного моделирования. Традиционно, регрессия оперирует с метриками, такими как среднеквадратичная ошибка (MSE). Однако, переформулировка задачи как генерации дискретных токенов, представляющих непрерывные значения, позволяет применять CE Loss, которая оптимизирует вероятность генерации правильной последовательности токенов. CE Loss, определяемая как $ — \sum_{i} y_{i} \log(p_{i})$, где $y_{i}$ — истинное значение, а $p_{i}$ — предсказанная вероятность, эффективно оценивает разницу между предсказанным распределением вероятностей и фактическим значением, что приводит к более эффективной оптимизации модели в контексте генеративных задач.
Переформулировка задачи регрессии как задачи генерации последовательности открывает новые возможности для преодоления ограничений традиционных методов. Традиционно, регрессия предполагает оптимизацию функций потерь, таких как среднеквадратичная ошибка (MSE), которые могут испытывать трудности при работе с выбросами или нелинейными зависимостями. В отличие от этого, подход на основе декодирования, используя функцию потерь кросс-энтропии (CE), позволяет LLM обучаться прогнозированию дискретных токенов, представляющих непрерывные значения. Это позволяет модели лучше справляться со сложными данными и потенциально достигать более высокой точности, особенно в случаях, когда традиционные методы испытывают трудности с обобщением или обработкой зашумленных данных. Использование CE Loss также облегчает использование методов регуляризации, разработанных для задач генерации последовательностей, что может улучшить устойчивость и обобщающую способность модели.

GenRe2: Оптимизация Регрессии с Обучением с Подкреплением
GenRe2 использует подход, основанный на декодировании, и преобразует задачу регрессии в Марковское Процесс принятия решений (MDP). В рамках MDP, каждое предсказание рассматривается как последовательность токенов, генерируемая агентом. Формулировка задачи как MDP позволяет применять методы обучения с подкреплением, в частности, методы градиентных оценок политики (Policy Gradient Methods), для оптимизации стратегии генерации токенов. Это позволяет модели обучаться, максимизируя функцию вознаграждения, которая напрямую связана с точностью предсказанных непрерывных значений. Таким образом, процесс регрессии рассматривается как последовательность действий, направленных на достижение оптимального результата, что позволяет использовать преимущества алгоритмов обучения с подкреплением.
В основе GenRe2 лежит обучение генерации оптимальных последовательностей токенов, представляющих непрерывные прогнозы, посредством использования фреймворка обучения с подкреплением. Вместо прямого предсказания численных значений, модель обучается генерировать дискретную последовательность токенов, которая затем декодируется в конечное непрерывное предсказание. Процесс обучения включает в себя определение политики, которая максимизирует ожидаемую награду, соответствующую точности прогноза. Таким образом, GenRe2 преобразует задачу регрессии в задачу последовательного принятия решений, где каждый токен в последовательности влияет на итоговую точность прогноза и, следовательно, на функцию вознаграждения.
GenRe2 использует методы ReMax (Reward-weighted Maximum Likelihood) и GRPO (Generalized Reward-weighted Policy Optimization) для снижения дисперсии при оценке градиента политики, что критически важно для стабильности обучения и повышения производительности. ReMax модифицирует функцию потерь, придавая больший вес примерам с более высокими наградами, что позволяет более эффективно направлять процесс обучения. GRPO, в свою очередь, является усовершенствованием алгоритмов Policy Gradient, направленным на уменьшение отклонения оценки градиента за счет использования взвешенных траекторий и клиппинга, предотвращающего слишком большие обновления политики. Комбинация этих методов позволяет GenRe2 более эффективно исследовать пространство стратегий и находить оптимальные последовательности токенов для точных непрерывных предсказаний, обеспечивая более стабильное и быстрое обучение по сравнению со стандартными алгоритмами обучения с подкреплением.
Интеграция компонентов GenRe2, включающая формулировку задачи регрессии как Марковского процесса принятия решений и использование методов оптимизации на основе градиентных стратегий, демонстрирует высокую эффективность подхода, основанного на обучении с подкреплением, для декодируемой регрессии. Эксперименты на наборе данных TALENT показали, что GenRe2 последовательно достигает наивысшего значения коэффициента детерминации $R^2$ по большинству наборов данных, превосходя показатели базовых методов регрессии. Это подтверждает, что применение принципов обучения с подкреплением к задаче декодируемой регрессии позволяет получить более точные и стабильные прогнозы.

Расширение Рамок: Регрессионные Головы и Перспективы
Метод регрессии на основе декодирования предоставляет уникальную гибкость в интеграции различных «голов» регрессии, позволяя адаптировать модель к специфическим требованиям задачи. В частности, «Pointwise Head» обеспечивает точечное предсказание, в то время как «Parametric Distribution Head» позволяет моделировать выходные данные в виде вероятностного распределения, что особенно полезно при работе с неопределенностью. Более сложная архитектура «Riemann Head» позволяет эффективно работать с многомерными данными и улавливать сложные зависимости между признаками. Возможность выбора и комбинирования этих «голов» значительно расширяет возможности модели и позволяет достигать более высокой точности и надежности предсказаний, особенно в задачах, где необходимо учитывать не только среднее значение, но и дисперсию или другие статистические характеристики выходных данных.
Возможность представления результатов предсказания не в виде единичного значения, а в виде распределения вероятностей или дискретизации непрерывного пространства, открывает новые перспективы в оценке неопределенности и повышении точности прогнозов. Вместо того, чтобы просто предсказывать одно конкретное число, модель способна оценить диапазон возможных значений и присвоить каждому из них вероятность. Такой подход особенно ценен в задачах, где точность критически важна, а игнорирование неопределенности может привести к серьезным последствиям. Например, при прогнозировании финансовых показателей или в задачах, связанных с безопасностью, знание о диапазоне возможных значений и их вероятностях позволяет принимать более обоснованные и взвешенные решения. Использование распределений, таких как гауссово ($N(\mu, \sigma^2)$) или другие, позволяет модели более полно отражать сложность и изменчивость реальных данных, что, в конечном итоге, приводит к более надежным и точным предсказаниям.
Интеграция методов нормализации квантилей и вычисления расстояния Вассерштейна позволяет существенно усовершенствовать как процесс токенизации, так и ландшафт функции потерь. Нормализация квантилей обеспечивает более стабильное распределение токенов, минимизируя влияние выбросов и повышая надежность предсказаний. В свою очередь, расстояние Вассерштейна, являясь метрикой, чувствительной к форме распределений, позволяет более точно оценивать различия между предсказанными и истинными значениями, что приводит к более эффективной оптимизации модели и повышению ее способности к обобщению. Такой подход позволяет не только улучшить точность непрерывных предсказаний, но и сделать процесс обучения более устойчивым и предсказуемым, особенно в задачах, где точность оценки неопределенности играет ключевую роль.
Исследования демонстрируют исключительную гибкость и потенциал регрессии на основе декодирования как универсальной основы для непрерывного предсказания. В ходе экспериментов, данный подход последовательно демонстрирует более высокую ранговую корреляцию по сравнению с традиционными методами, что свидетельствует о его способности более точно отражать взаимосвязи в данных. Важно отметить, что стабильная и надежная производительность достигается при использовании различных баз токенизаторов, подтверждая устойчивость и адаптивность предложенного фреймворка к различным типам данных и задачам. Это позволяет рассматривать регрессию на основе декодирования не просто как отдельный алгоритм, а как полноценную платформу для решения широкого спектра задач непрерывного предсказания, открывающую новые возможности в области анализа данных и машинного обучения.

Представленная работа демонстрирует стремление к элегантности в решении задач регрессии, выходя за рамки токено-ориентированного подхода. Авторы предлагают Generative Reinforced Regressor (GenRe2), систему, оцениваемую не по отдельным элементам, а по общей числовой точности — концепция, перекликающаяся с принципами математической чистоты. Как однажды заметил Джон Маккарти: «Искусственный интеллект — это область компьютерных наук, занимающаяся разработкой разумных машин». Это наблюдение подчеркивает необходимость поиска фундаментальных принципов, которые бы обеспечивали надежность и предсказуемость алгоритмов, подобно тому, как GenRe2 стремится к достижению общей точности, а не просто к удовлетворению локальным метрикам. Подход, описанный в статье, представляет собой попытку создать доказуемо корректное решение, а не просто систему, «работающую на тестах».
Куда Далее?
Без четкого определения критерия оптимальности, любое усовершенствование — лишь шум в данных. Данная работа, представляя подход Generative Reinforced Regressor, демонстрирует, что фокусировка на последовательном вознаграждении, оценивающем общую точность регрессии, превосходит традиционные методы, ориентированные на точечную точность. Однако, следует признать, что само понятие «точность» требует дальнейшей формализации. Что есть «достаточно точное» решение? И как это понятие соотносится с вычислительными издержками?
Очевидным направлением для будущих исследований является разработка более строгих метрик вознаграждения, учитывающих не только конечное значение, но и траекторию его достижения. Алгоритм, стремящийся к элегантному решению, должен минимизировать как ошибку, так и сложность. В настоящее время, существующие методы в значительной степени полагаются на эмпирические оценки. Доказательство сходимости и оптимальности алгоритмов регрессии, основанных на обучении с подкреплением, остается открытой проблемой.
В конечном счете, истинный прогресс в области регрессионных моделей, генерирующих последовательности, потребует перехода от простого «рабочего» решения к строго доказуемо оптимальному. Любое другое приближение — лишь иллюзия контроля над случайностью, а не реальное овладение математической красотой.
Оригинал статьи: https://arxiv.org/pdf/2512.06533.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-09 16:36