Автор: Денис Аветисян
Новое исследование показывает, что фундаментальные принципы, лежащие в основе предсказуемого поведения больших языковых моделей, могут быть обнаружены и в гораздо более простых системах.
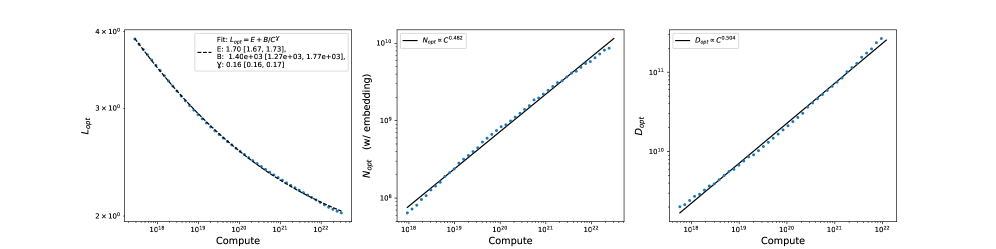
Работа демонстрирует, что законы масштабирования нейросетей возникают не только из-за сложности данных, но и из фундаментальных свойств обучения, что подтверждается анализом случайных блужданий по графам.
Закономерности масштабирования, наблюдаемые в современных нейронных сетях, часто рассматриваются как следствие особенностей структуры данных. В работе ‘On the origin of neural scaling laws: from random graphs to natural language’ авторы исследуют происхождение этих закономерностей, демонстрируя их появление даже в упрощенных условиях — при обучении на случайных графах и последовательностях, генерируемых упрощенными языковыми моделями. Полученные результаты указывают на то, что закономерности масштабирования могут возникать не только из-за сложности данных, но и из фундаментальных принципов обучения. Не является ли это ключом к созданию более эффективных и масштабируемых моделей искусственного интеллекта?
Законы масштабирования: Путь к совершенству систем
Современные достижения в области глубокого обучения демонстрируют предсказуемые взаимосвязи между размером модели, объемом обучающих данных и достигнутой производительностью, что получило название «Законов масштабирования нейронных сетей». Эти законы предполагают, что простое увеличение масштаба — количества параметров модели и объема данных — может привести к существенным улучшениям в различных задачах, от распознавания изображений до обработки естественного языка. Исследования показывают, что зависимость между этими факторами не является линейной, а описывается степенными функциями, что позволяет прогнозировать производительность модели при различных масштабах. Понимание этих закономерностей имеет решающее значение для оптимизации процесса обучения и эффективного использования вычислительных ресурсов, позволяя разработчикам принимать обоснованные решения о размере модели и необходимом объеме данных для достижения желаемого уровня точности.
Законы масштабирования в области глубокого обучения демонстрируют, что простое увеличение размеров модели и объёма обучающих данных может приводить к существенному повышению производительности. Однако, эти же законы указывают на наличие принципиальных ограничений, препятствующих неограниченному улучшению характеристик. Исследования показывают, что увеличение масштаба не является панацеей, и существует точка, после которой дальнейшее наращивание ресурсов приносит всё меньше выгоды. Это связано с тем, что сложность решаемых задач и архитектурные особенности моделей также оказывают значительное влияние на итоговые результаты, формируя своего рода «потолок» производительности, достижение которого требует более сложных и инновационных подходов, нежели простое масштабирование.
Изучение динамики масштабирования имеет решающее значение для эффективной разработки моделей и рационального распределения ресурсов. Полученные результаты демонстрируют, что закономерности масштабирования проявляются даже в упрощенных условиях, что подтверждает их фундаментальную значимость. Значение среднего показателя α (Data), характеризующего зависимость производительности от объема данных, варьируется от 0.3 до 2.4 в зависимости от типа графа и стратегии обучения. Такая вариативность подчеркивает необходимость учета специфики задачи и архитектуры модели при планировании масштабирования, позволяя оптимизировать затраты и добиться максимальной эффективности. Понимание этих закономерностей позволяет предсказывать улучшение производительности при увеличении размеров модели и обучающих данных, что является важным шагом на пути к созданию более мощных и эффективных систем искусственного интеллекта.
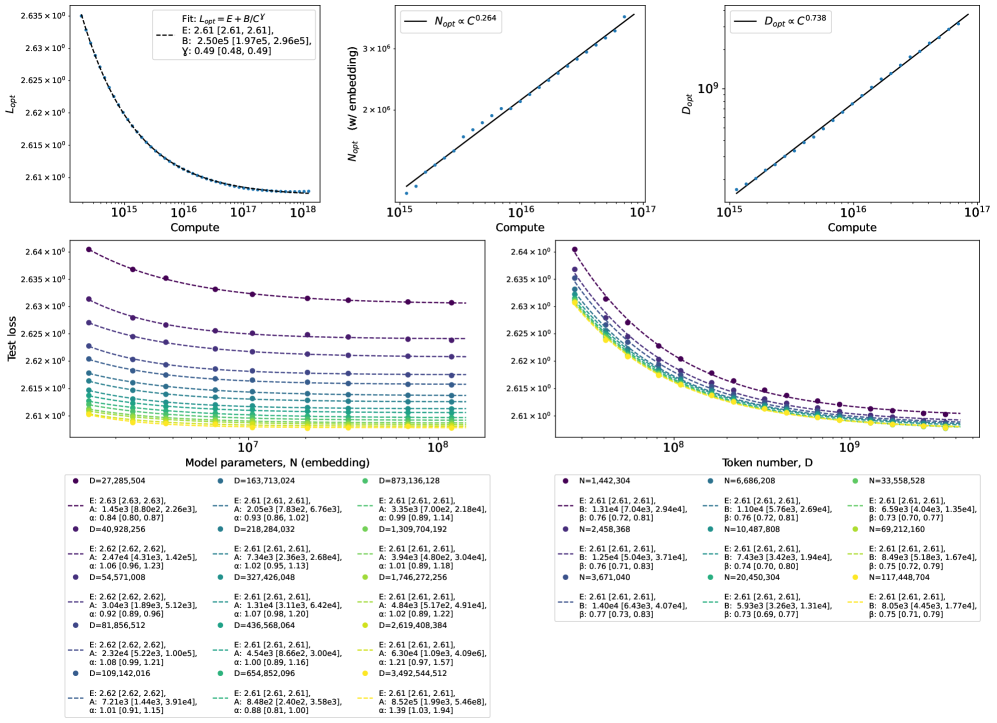
Сложность данных и устойчивые функции потерь: Ключ к надёжности моделей
Сложность данных, или их «Data Complexity», оказывает существенное влияние на эффективность масштабирования моделей в соответствии с закономерностями масштабирования (scaling laws). Более сложные наборы данных требуют больше вычислительных ресурсов и времени для достижения аналогичной производительности, что снижает эффективность масштабирования. На практике, это проявляется в том, что для сложных данных требуется больший объем данных для обучения и/или более сложные архитектуры моделей для достижения приемлемой точности. Недооценка сложности данных может привести к неоптимальному распределению ресурсов и замедлить прогресс в обучении модели. R^2 и другие метрики качества модели часто демонстрируют более низкие значения для сложных наборов данных при фиксированном объеме обучения.
Устойчивые функции потерь, такие как HuberLoss, играют критическую роль в смягчении влияния выбросов и зашумленных данных при обучении моделей. В отличие от среднеквадратичной ошибки (MSE), которая чувствительна к выбросам из-за квадратичной зависимости, HuberLoss комбинирует квадратичную функцию потерь для малых ошибок и линейную функцию потерь для больших ошибок. Это позволяет снизить влияние отдельных аномальных значений на процесс обучения, обеспечивая более стабильную и надежную сходимость модели. Применение HuberLoss особенно полезно в задачах, где данные содержат значительное количество шума или выбросов, поскольку позволяет избежать переобучения на аномальных данных и улучшить обобщающую способность модели.
Оценка сложности данных позволяет проводить целенаправленный дизайн и оптимизацию моделей. В ходе исследований было установлено, что отношение среднеквадратичной ошибки (MSE) для степенных (power-law) и экспоненциальных моделей составляет от 50 до 100 раз лучше для конфигурации L(D)N и от 5 до 10 раз лучше для L(N)D. Данные результаты демонстрируют значительно более точное соответствие степенного масштабирования эмпирическим данным, что подтверждает его преимущество при моделировании зависимости производительности от масштаба данных и размера модели. MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2
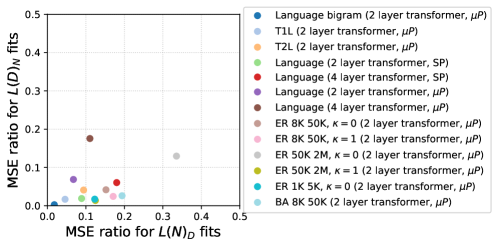
Эффективные обновления параметров и обучение: Путь к экономии ресурсов
Традиционные схемы параметризации, такие как StandardParameterization, характеризуются тем, что каждый параметр модели обновляется индивидуально в процессе обучения. При увеличении размера модели — числа параметров — вычислительные затраты на эти индивидуальные обновления экспоненциально возрастают. Это связано с необходимостью вычисления градиентов для каждого параметра и последующего применения алгоритма оптимизации, что требует значительных ресурсов памяти и процессорного времени. В частности, операции матричного умножения и вычисления градиентов становятся узким местом, ограничивающим скорость и масштабируемость обучения больших моделей. Следовательно, эффективность StandardParameterization снижается пропорционально увеличению числа параметров, что делает её непрактичной для обучения современных больших языковых моделей и других сложных нейронных сетей.
Максимальная параметризация обновлений (MaximalUpdateParameterization) представляет собой метод, направленный на повышение эффективности процесса обучения больших моделей. В отличие от стандартных схем параметризации, где обновления параметров могут быть ограничены вычислительными ресурсами, данная методика позволяет более эффективно использовать доступные ресурсы за счет оптимизации процесса вычисления градиентов и обновления весов. Это достигается за счет переформулировки структуры параметров и использования альтернативных алгоритмов оптимизации, что потенциально снижает количество необходимых операций и ускоряет сходимость модели. Применение MaximalUpdateParameterization особенно актуально при работе с моделями, содержащими большое количество параметров, где традиционные методы становятся вычислительно затратными.
Сочетание эффективных схем параметризации, таких как MaximalUpdateParameterization, с методами обучения, ориентированными на снижение вычислительных затрат (ParameterEfficientTraining), позволяет значительно уменьшить общую стоимость обучения больших моделей. ParameterEfficientTraining включает в себя техники, направленные на обучение лишь части параметров модели, например, адаптацию дополнительных слоев или использование низкоранговых представлений, что в сочетании с эффективными обновлениями параметров снижает требования к памяти и вычислительным ресурсам, особенно при работе с моделями, содержащими миллиарды параметров. Это позволяет обучать и развертывать модели большего размера на ограниченном оборудовании и сократить время обучения.
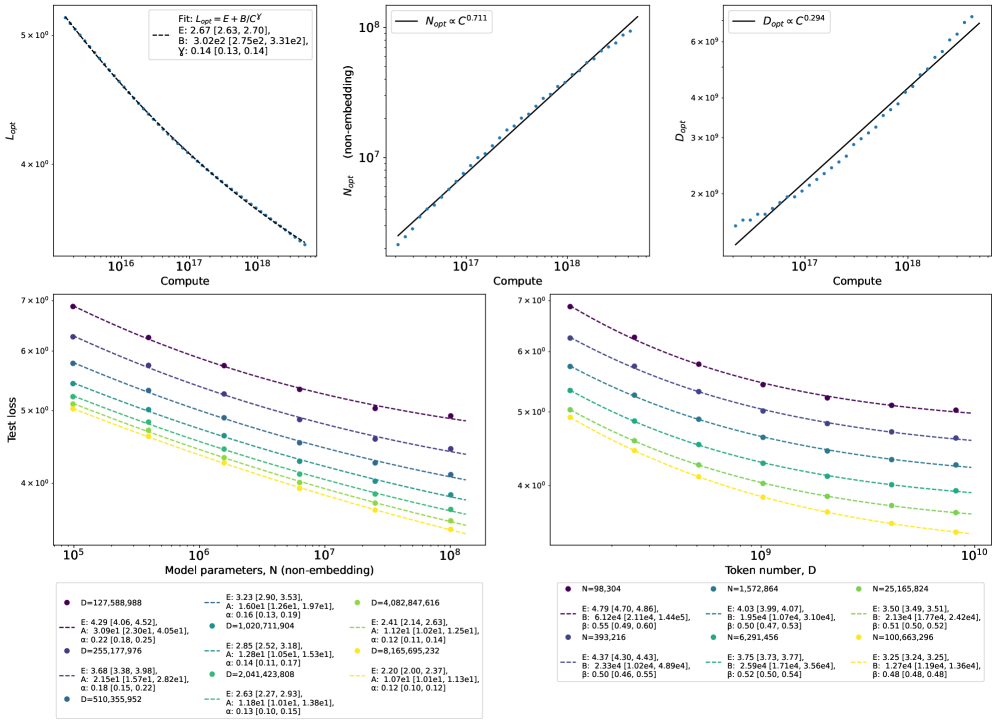
Коррекция смещения и статистическая строгость: Основа надёжных выводов
Статистические оценки часто подвержены смещению, что может искажать результаты и приводить к неверным выводам. Смещение возникает из-за различных факторов, включая систематические ошибки отбора, неполноту данных или предвзятость в процессе измерения. Например, при исследовании больших данных смещение выборки может возникнуть, если данные не представляют генеральную совокупность должным образом. Последствия смещения могут быть значительными, особенно в контексте научных исследований и принятия решений, поскольку оно может привести к неверной интерпретации результатов и ошибочным заключениям о взаимосвязях между переменными. Для минимизации влияния смещения применяются различные методы, такие как взвешивание данных, стратификация выборки и использование корректирующих факторов.
Методы коррекции смещения, такие как бутстрап (Bootstrap), являются критически важными для получения более точных и надежных оценок в статистическом анализе. Бутстрап представляет собой метод повторной выборки с возвращением из исходного набора данных, позволяющий создать множество новых наборов данных, используемых для оценки стандартных ошибок и доверительных интервалов. В отличие от традиционных методов, требующих предположений о распределении данных, бутстрап является непараметрическим и может применяться к сложным статистическим моделям и ненормально распределенным данным. Применение бутстрапа позволяет уменьшить влияние смещения, вызванного особенностями выборки, и получить более реалистичные оценки неопределенности, что особенно важно при анализе данных, полученных в ходе нейронного масштабирования и других сложных экспериментах.
Применение методов коррекции смещения, таких как бутстрап, критически важно для обеспечения устойчивости и обобщаемости результатов, полученных на основе законов масштабирования нейронных сетей. Эти методы позволяют оценить статистическую погрешность и уменьшить влияние случайных колебаний в данных, что повышает достоверность выводов при экстраполяции результатов на новые, ранее не встречавшиеся данные или архитектуры нейронных сетей. Без коррекции смещения, оценки параметров и прогнозы, полученные из законов масштабирования, могут быть переоценены или недооценены, что приведет к неверным практическим решениям и неточным научным заключениям. Это особенно важно при использовании законов масштабирования для прогнозирования вычислительных требований и производительности будущих моделей искусственного интеллекта.
Влияние на модели обработки естественного языка нового поколения
Архитектура Transformer, являясь основополагающим элементом современных языковых моделей, активно использует закономерности масштабирования для достижения улучшенных результатов. В основе этого подхода лежит понимание того, как увеличение размера модели и объема обучающих данных влияет на её способность к обобщению и решению сложных задач. Исследования показывают, что производительность моделей Transformer нелинейно растет с увеличением этих параметров, демонстрируя предсказуемые зависимости, описываемые так называемыми законами масштабирования. Использование этих законов позволяет разработчикам эффективно планировать ресурсы, оптимизировать размеры моделей и предсказывать потенциальные улучшения производительности, избегая необоснованного увеличения вычислительных затрат и обеспечивая оптимальное соотношение между размером модели, объемом данных и достигнутой точностью. Таким образом, архитектура Transformer, опираясь на принципы масштабирования, предоставляет мощный инструмент для создания всё более совершенных и эффективных языковых моделей.
В основе функционирования современных языковых моделей лежит задача предсказания следующего токена в последовательности, и для обучения этим моделям широко используется функция потерь, известная как перекрестная энтропия (CrossEntropyLoss). Данный метод позволяет оценивать разницу между предсказанным распределением вероятностей следующего токена и истинным распределением, определяемым обучающими данными. Минимизация этой функции потерь посредством алгоритмов оптимизации, таких как стохастический градиентный спуск, обеспечивает постепенное улучшение способности модели генерировать связный и правдоподобный текст. Эффективность перекрестной энтропии обусловлена её способностью учитывать неопределенность в предсказаниях и штрафовать модель за уверенные, но неверные прогнозы, что способствует более надежной и точной генерации текста.
Оптимизация моделей обработки естественного языка требует комплексного подхода, включающего анализ сложности данных, повышение эффективности использования параметров и строгость статистических методов. Исследования показали, что средний показатель β (ёмкость модели) варьируется от 0.7 до 1.4. Этот диапазон указывает на то, что существует оптимальная стратегия масштабирования, позволяющая достичь максимальной производительности при заданном объеме данных и вычислительных ресурсах. Понимание взаимосвязи между этими факторами является ключевым для разработки более мощных и эффективных языковых моделей нового поколения, способных решать сложные задачи с повышенной точностью и скоростью.
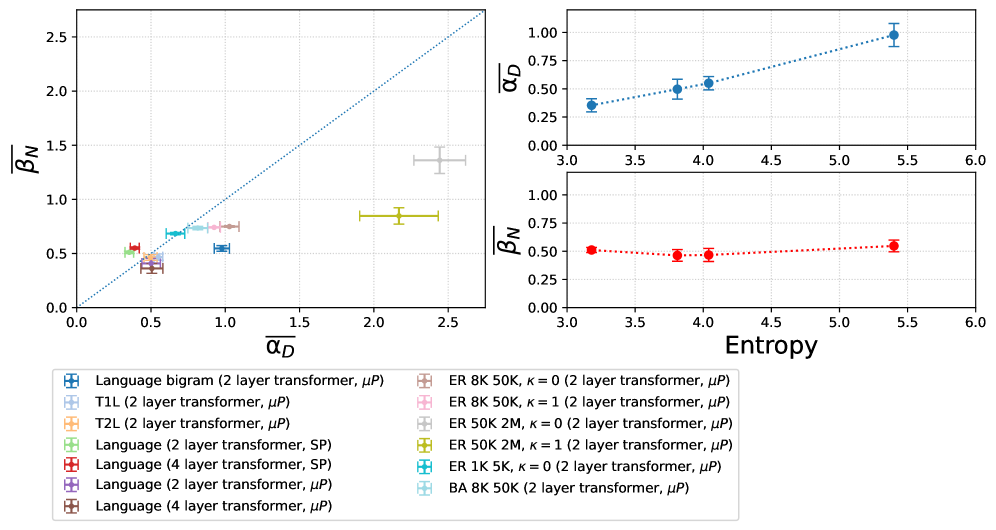
Исследование показывает, что закономерности масштабирования нейронных сетей, наблюдаемые в сложных моделях обработки естественного языка, проявляются и в более простых системах, таких как случайные блуждания по графам. Этот факт указывает на то, что эти закономерности могут быть не просто следствием сложности данных, а фундаментальным свойством самого процесса обучения. Как заметил Бертран Рассел: «Страх — это больше, чем просто отсутствие храбрости». В контексте данной работы, этот афоризм можно интерпретировать как указание на то, что даже в самых простых системах могут скрываться неожиданные и глубокие закономерности, требующие пристального внимания и исследования, подобно тому, как страх требует понимания и преодоления.
Что впереди?
Представленная работа, подобно любому коммиту в долгой истории версий, зафиксировала определенную точку понимания. Обнаружение масштабируемых законов в столь простых системах, как случайные блуждания по графам, неизбежно заставляет задуматься: не являемся ли мы свидетелями не закономерностей в данных, а эмерджентных свойств самого процесса обучения? Каждая версия модели — это глава, но что, если сюжет написан не данными, а внутренней логикой алгоритма?
Очевидно, что дальнейшее исследование требует выхода за рамки исключительно языковых моделей. Необходимо проверить, воспроизводятся ли эти законы в других областях — от компьютерного зрения до обучения с подкреплением. Задержка в исправлении ошибок, неминуемый налог на амбиции, заключается в том, что мы склонны искать ответы там, где они наиболее очевидны — в сложности данных, упуская из виду простоту лежащих в основе принципов.
В конечном итоге, вопрос не в том, насколько хорошо мы можем предсказывать поведение больших моделей, а в том, понимаем ли мы фундаментальные ограничения любой системы, стремящейся к оптимальности. Все системы стареют — вопрос лишь в том, делают ли они это достойно. Время — не метрика, а среда, в которой существуют системы, и в этой среде даже самые простые алгоритмы могут демонстрировать удивительную устойчивость.
Оригинал статьи: https://arxiv.org/pdf/2601.10684.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-19 03:43