Автор: Денис Аветисян
Исследователи представили MoCha — систему, позволяющую реалистично заменять персонажей в видео, используя лишь маску одного кадра и современные методы машинного обучения.

Предлагаемый фреймворк MoCha использует диффузионные модели и обучение с примерами для замены персонажей в видео без необходимости в плотных ориентирах или структурных априорных знаниях.
Замена лица в видеоматериалах остаётся сложной задачей из-за отсутствия размеченных данных и необходимости в детальном отслеживании структуры сцены. В данной работе, посвященной проблеме ‘End-to-End Video Character Replacement without Structural Guidance’, предлагается новый подход, позволяющий осуществлять замену лица, опираясь лишь на маску из одного кадра, без использования дополнительных структурных ориентиров. Ключевым элементом предложенного фреймворка MoCha является применение диффузионных моделей и обучение с подкреплением для адаптации входных данных и сохранения идентичности. Не откроет ли это новые возможности для более гибкого и реалистичного видеомонтажа и создания цифровых двойников?
Задача Реалистичной Замены Персонажей в Видео: Вызов для Современных Технологий
Бесшовная замена персонажей в видеоматериале играет ключевую роль в современной виртуальной производстве и создании контента, однако представляет собой сложную техническую задачу. Возможность реалистично интегрировать цифрового актера в существующие кадры требует не только высокой точности в отслеживании движений и реконструкции геометрии, но и сохранения визуальной достоверности, включая освещение, тени и взаимодействие с окружением. Несмотря на значительные достижения в области компьютерного зрения и графики, достижение полной иллюзии правдоподобия остается непростой задачей, особенно в динамичных сценах с быстрыми движениями и сложными взаимодействиями. Успешное решение этой проблемы откроет новые горизонты для кинематографа, игровой индустрии и создания интерактивного контента, позволяя значительно расширить творческие возможности и снизить производственные затраты.
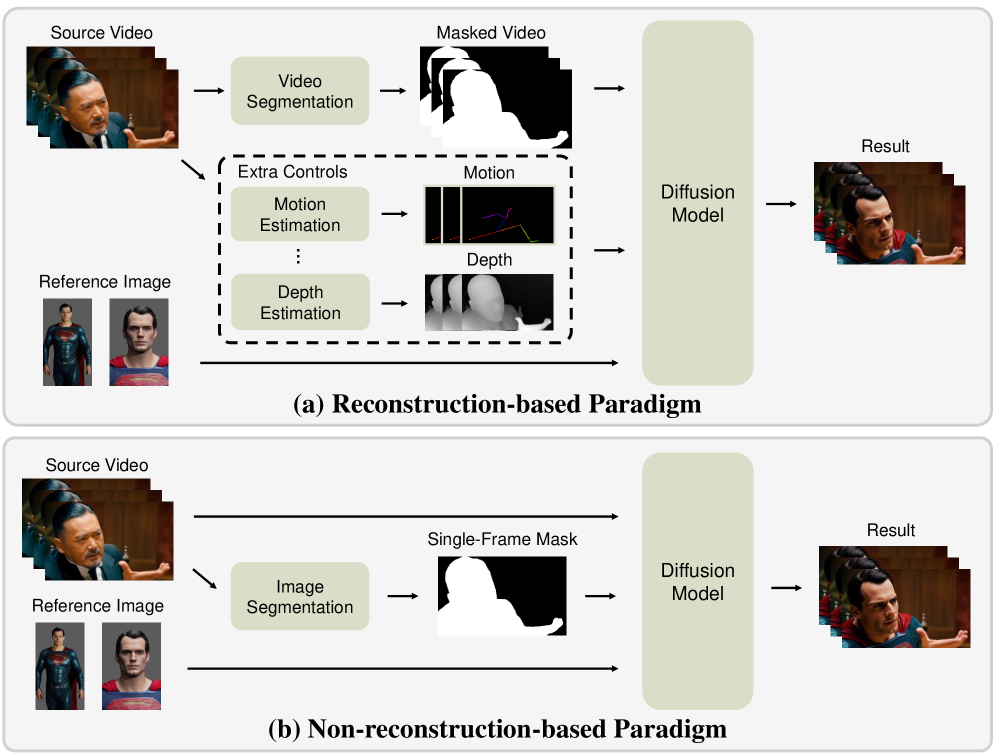
Традиционные методы замены персонажей в видео, такие как парадигма, основанная на реконструкции, требуют создания масок для каждого кадра и предоставления структурной информации, что значительно усложняет рабочий процесс и зачастую делает его нереалистичным. Этот подход предполагает кропотливую ручную работу по выделению и отслеживанию объекта замены в каждом кадре видео, а также необходимость предоставления дополнительных данных о его структуре, например, о форме лица или позе тела. Такой трудоемкий процесс не только требует значительных временных затрат, но и подвержен ошибкам, особенно в динамичных сценах, что приводит к снижению качества и реалистичности финального результата. В результате, применение данных методов ограничено статичными кадрами или сценами с минимальным движением, что существенно препятствует развитию виртуального производства и создания контента.
Существующие методы замены персонажей в видео, несмотря на свою технологическую сложность, часто сталкиваются с проблемой сохранения временной согласованности и высокой детализации изображения. В динамичных сценах, где персонажи активно двигаются и взаимодействуют с окружением, даже незначительные несоответствия между кадрами становятся заметными и разрушают иллюзию реалистичности. Особенно это проявляется в сохранении мельчайших деталей, таких как текстура кожи, волосы и складки одежды, которые требуют точной передачи во времени. Ограничения в поддержании как временной, так и пространственной достоверности существенно снижают применимость этих подходов в ситуациях, где требуется правдоподобная замена персонажей в сложных и быстро меняющихся видеорядах.

MoCha: Элегантное Решение Задачи Замены Персонажей в Видео
MoCha представляет собой сквозной фреймворк для замены персонажей в видео, использующий всего одну кадровую маску. Традиционные методы замены требуют создания и применения масок для каждого кадра видео, что является трудоемким и ресурсозатратным процессом. MoCha упрощает этот процесс, позволяя пользователям указать желаемый персонаж и предоставить лишь одну кадровую маску, определяющую область, которую необходимо заменить. Фреймворк автоматически распространяет эту информацию на все остальные кадры видео, генерируя реалистичную замену персонажа без необходимости ручного редактирования каждого кадра. Это значительно сокращает время и усилия, необходимые для создания видео с замененными персонажами, делая процесс доступным для более широкого круга пользователей и приложений.
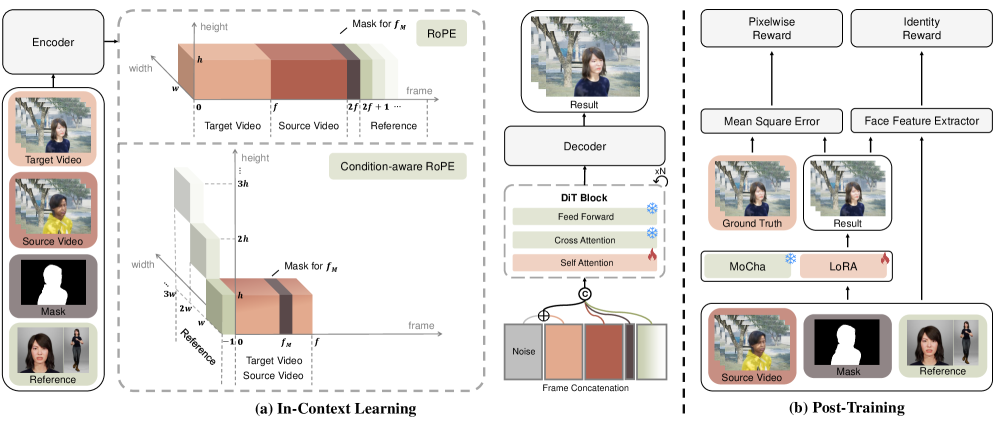
В основе MoCha лежит использование обучения с примерами (In-Context Learning), которое позволяет направлять процесс генерации видео и повышать степень контроля над результатом. Вместо традиционной тонкой настройки модели на конкретные сценарии, MoCha использует небольшое количество примеров (например, изображения или короткие видеоклипы) в качестве контекста для генерации. Это обеспечивает адаптацию к различным ситуациям и стилям без необходимости переобучения модели, что существенно упрощает и ускоряет процесс замены персонажей в видео. Предоставление соответствующих примеров позволяет MoCha понимать желаемые характеристики и стиль генерируемого видео, обеспечивая более точное и согласованное воспроизведение.
В основе MoCha лежит усовершенствованная техника позиционного кодирования — Condition-Aware RoPE, разработанная на базе RoPE (Rotary Positional Embedding). Condition-Aware RoPE позволяет эффективно объединять различные модальности входных данных, такие как маска лица, целевое изображение и видеокадры, за счет адаптации вращающихся позиционных кодировок к условным сигналам. Это обеспечивает сохранение когерентности и реалистичности при замене персонажа, так как модель учитывает пространственные взаимосвязи между различными элементами изображения и видео, а также контекстную информацию, предоставленную условными сигналами. Эффективное слияние мультимодальных данных посредством Condition-Aware RoPE является ключевым фактором, обеспечивающим стабильное и качественное генерирование видео с замененными персонажами.
В основе MoCha лежит мощный фреймворк Flow Matching, обеспечивающий генерацию высококачественного видео. Flow Matching — это вероятностный генеративный подход, который моделирует непрерывное преобразование данных путем обучения функции потока f(x, t), где x — исходные данные, а t — время. В отличие от диффузионных моделей, Flow Matching напрямую обучается отображению данных в шум и обратно, что позволяет достичь более высокой скорости генерации и стабильности. В MoCha этот фреймворк используется для моделирования динамики видео, что позволяет реалистично заменять персонажей, сохраняя при этом временную согласованность и визуальное качество.
Доказательство Эффективности: Оценка и Улучшение Качества
Оценка производительности MoCha проводилась с использованием VBench — комплексной системы оценки качества видео, включающей в себя стандартные метрики, такие как SSIM (Structural Similarity Index Measure), LPIPS (Learned Perceptual Image Patch Similarity) и PSNR (Peak Signal-to-Noise Ratio). VBench обеспечивает всестороннюю проверку различных аспектов качества видео, включая структурное сходство, перцептивное качество и уровень шума. Использование этих метрик позволяет объективно сравнить MoCha с другими существующими методами и подтвердить его эффективность в генерации высококачественного видеоконтента. Результаты, полученные с использованием VBench, служат количественным подтверждением улучшения качества видео, достигаемого с помощью MoCha.
В ходе оценки производительности MoCha показал передовые результаты на синтетических бенчмарках по показателям SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity) и PSNR (Peak Signal-to-Noise Ratio). Достигнутые значения по данным метрикам превосходят существующие аналоги, что подтверждается результатами сравнительного анализа с другими моделями обработки видео. SSIM измеряет структурное сходство между обработанным и исходным видео, LPIPS оценивает перцептивное сходство, а PSNR — отношение мощности сигнала к мощности шума, что позволяет объективно оценить качество восстановления видео и минимизацию искажений.
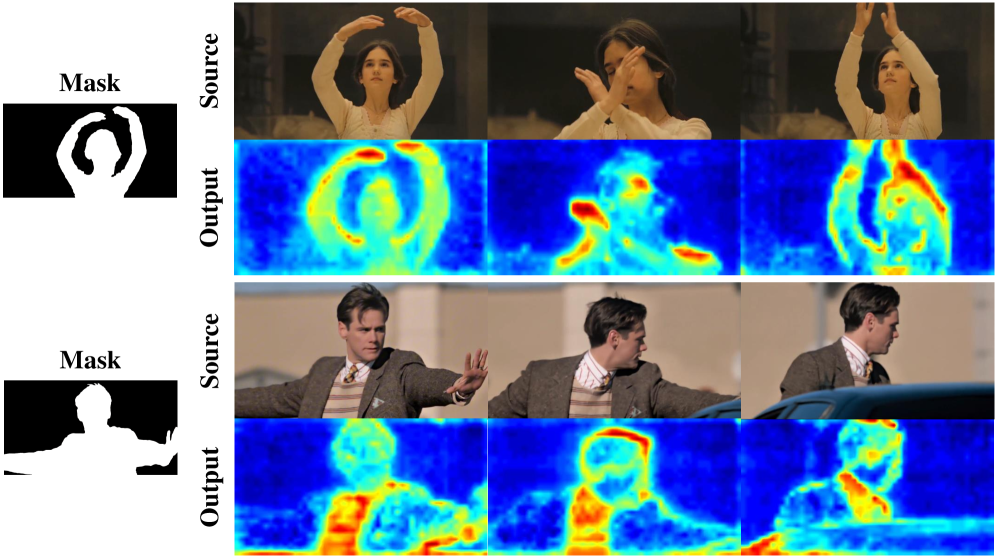
Для дальнейшего улучшения реалистичности лиц в сгенерированных видео, в MoCha реализована дифференцируемая функция вознаграждения (Differentiable Facial Reward Function). Эта функция использует встраивания Arcface Embeddings для обеспечения сохранения идентичности и естественности выражений лиц. Arcface Embeddings позволяют оценивать сходство между сгенерированным лицом и целевым лицом, предоставляя количественный сигнал для оптимизации процесса генерации. Дифференцируемость функции вознаграждения позволяет интегрировать её непосредственно в процесс обучения нейронной сети, что обеспечивает более эффективную оптимизацию и улучшение качества сгенерированных лиц.
В архитектуре MoCha используется Video Variational Encoder (VAE) для эффективной компрессии пространственно-временных латентов видео. VAE позволяет снизить вычислительные затраты за счет уменьшения размерности данных, сохраняя при этом ключевую информацию, необходимую для реконструкции видеопоследовательности. Это достигается путем кодирования видео в латентное пространство с меньшей размерностью и последующей декодировкой для получения сжатого представления, которое требует меньше вычислительных ресурсов для обработки и манипулирования.
Оценка производительности MoCha с использованием VBench показала превосходство над существующими методами в поддержании временной согласованности (Temporal Consistency), достижении высокой достоверности передачи мимики (Facial Expression Fidelity) и сохранении идентичности (Identity Preservation). Превосходство подтверждается более высокими значениями ключевых метрик VBench, таких как SSIM, LPIPS и PSNR, по сравнению с результатами, полученными другими алгоритмами. В частности, MoCha демонстрирует улучшенную способность генерировать последовательные кадры видео, реалистично передавать нюансы выражений лица и точно воспроизводить личность объекта на протяжении всей последовательности.
Расширение Творческих Возможностей: Перспективы Применения
Разработанная система MoCha открывает новые горизонты в области виртуального производства и создания контента благодаря упрощенному рабочему процессу. Ключевым элементом, обеспечивающим эту эффективность, является использование таких технологий, как SAM2, для автоматической генерации оценочных масок. Это позволяет значительно сократить время и ресурсы, необходимые для сложных задач, таких как ротоскопинг и отслеживание движения. Вместо трудоемкой ручной работы, система автоматически выделяет нужные объекты, обеспечивая высокую точность и позволяя создавать реалистичные визуальные эффекты с минимальными усилиями. Такой подход особенно ценен в динамичных проектах, где требуется быстрая адаптация и внесение изменений в режиме реального времени, делая MoCha мощным инструментом для профессионалов и энтузиастов в области видеопроизводства.
Разработанная система демонстрирует высокую эффективность, позволяя осуществлять замену персонажей и динамическую корректировку сцен в режиме реального времени. Благодаря оптимизированным алгоритмам и способности сохранять детализацию изображения, платформа позволяет пользователям мгновенно изменять внешний вид действующих лиц или вносить изменения в окружающую обстановку без значительных задержек или потери качества. Это открывает новые возможности для интерактивного повествования, персонализированного контента и оперативной адаптации видеоматериалов к изменяющимся требованиям, значительно упрощая и ускоряя процесс видеопроизводства.
Система MoCha открывает новые возможности для создания высококачественного видеоконтента, устраняя необходимость в сложном и дорогостоящем процессе риггинга и захвата движения. Традиционно, создание реалистичной анимации требовало специализированных навыков и дорогостоящего оборудования, ограничивая доступ к этой технологии для многих творцов. MoCha, благодаря своей упрощенной методологии, позволяет создавать убедительные видеоролики, используя лишь базовые инструменты и минимальные ресурсы. Это значительно расширяет круг потенциальных создателей контента, позволяя художникам, дизайнерам и даже обычным пользователям воплощать свои идеи в жизнь без значительных финансовых или технических барьеров. Таким образом, MoCha способствует демократизации процесса создания видео, делая его более доступным и инклюзивным для широкой аудитории.
Принципы, лежащие в основе MoCha, обладают значительным потенциалом для расширения возможностей видеомонтажа за пределы текущих ограничений. Исследователи полагают, что упрощенный подход к управлению и редактированию видео, основанный на генеративных моделях и автоматическом создании масок, может быть применен к широкому спектру задач, включая автоматическое редактирование, стилизацию видео и даже создание нового контента на основе существующих материалов. Это открывает перспективы для разработки более интуитивных и универсальных инструментов, которые позволят пользователям с любым уровнем подготовки легко создавать высококачественный видеоконтент, значительно упрощая процесс пост-продакшена и расширяя творческие возможности.
Исследование представляет MoCha — систему, демонстрирующую элегантность подхода к замене персонажей в видео без использования сложных структурных ориентиров. Данная работа акцентирует внимание на применении диффузионных моделей и обучения в контексте, что позволяет достичь впечатляющих результатов, опираясь лишь на маску одного кадра. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект — это не магия, а математика». Именно математическая точность и продуманность алгоритмов, реализованных в MoCha, позволяют добиться убедительной замены персонажей, подтверждая, что красота алгоритма не зависит от языка реализации, а определяется лишь его непротиворечивостью и эффективностью.
Куда Далее?
Представленная работа, хотя и демонстрирует элегантность отказа от явных структурных ограничений в задаче замены персонажей в видео, оставляет нерешенными вопросы, требующие математической строгости. Возможность обучения модели исключительно на основе единичной маски, безусловно, примечательна, но не отменяет необходимости доказательства устойчивости к шуму и вариациям в данных. Утверждения о «в контекстном обучении» требуют более формального определения, не сводящегося к эмпирическому наблюдению.
В дальнейшем, пристального внимания заслуживает формализация понятия «правдоподобия» в пространстве видео, генерируемых диффузионными моделями. Успех не должен измеряться лишь визуальной привлекательностью, но и соответствием фундаментальным принципам физики света и движения. Использование методов, выходящих за рамки простой оценки IoU, представляется критически важным.
Следующим шагом видится разработка алгоритмов, способных не только заменять персонажей, но и доказуемо сохранять семантическую целостность видеоряда. Иными словами, генерируемое видео должно быть не просто реалистичным, но и логичным, не вызывающим когнитивного диссонанса. В противном случае, все усилия по созданию «реалистичных» видео сводятся к созданию иллюзии, а не решению научной задачи.
Оригинал статьи: https://arxiv.org/pdf/2601.08587.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-14 19:32