Автор: Денис Аветисян
Исследователи предлагают инновационную архитектуру, позволяющую моделям понимать контекст и решать задачи, даже когда обучающих данных недостаточно.
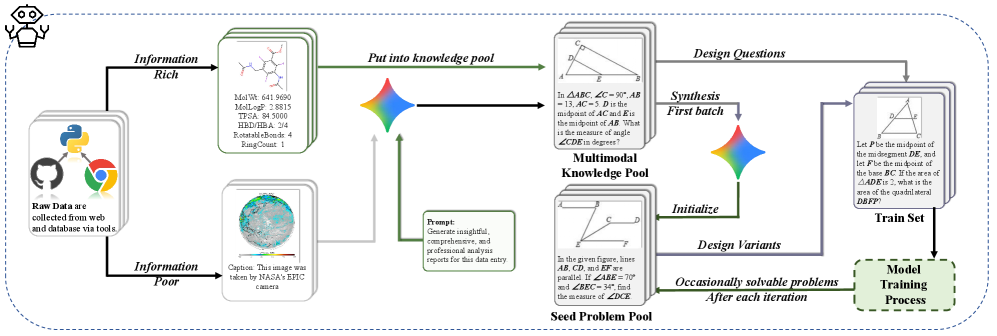
Предлагаемый фреймворк DoGe разделяет процесс обучения моделей «зрение-язык» на этапы понимания контекста и решения проблем, используя двухэтапное обучение с подкреплением для повышения эффективности и предотвращения манипуляций с системой вознаграждений.
Несмотря на значительные успехи современных мультимодальных моделей, обучение с подкреплением в условиях ограниченности данных остается сложной задачей. В работе, озаглавленной ‘Decouple to Generalize: Context-First Self-Evolving Learning for Data-Scarce Vision-Language Reasoning’, предложен фреймворк DoGe, разделяющий процесс обучения на этапы понимания контекста и решения задач, что позволяет избежать эксплуатации системы вознаграждений и повысить обобщающую способность. Ключевой особенностью подхода является двухэтапное обучение с подкреплением и расширенная база знаний, формирующая эволюционирующую учебную программу. Сможет ли данная стратегия обеспечить масштабируемый путь к созданию самообучающихся мультимодальных моделей нового поколения?
Преодолевая Ограничения: Необходимость Нового Подхода к Рассуждениям
Несмотря на впечатляющие возможности современных мультимодальных моделей, объединяющих зрение и язык, они часто сталкиваются с трудностями при решении задач, требующих последовательного и многоступенчатого рассуждения. Например, модели могут успешно идентифицировать объекты на изображении и даже описывать их, однако при необходимости выполнить сложный вывод, основанный на взаимосвязях между объектами и контекстом, их производительность существенно снижается. Это проявляется в неспособности правильно отвечать на вопросы, требующие логического анализа, планирования или понимания причинно-следственных связей, даже если визуальная информация и лингвистический запрос кажутся простыми. В результате, для достижения подлинно интеллектуальных систем, способных к адаптивному и надежному решению сложных проблем, необходимо преодолеть эти ограничения в архитектуре и принципах работы существующих моделей.
Несмотря на впечатляющий прогресс в области языковых и зрительно-языковых моделей, простое увеличение их размера перестает приносить соразмерные результаты. Исследования показывают, что дальнейшее масштабирование сталкивается с законом убывающей доходности, что указывает на фундаментальное ограничение в самой архитектуре этих систем. Проблема заключается не в нехватке данных или вычислительных ресурсов, а в том, как модели организуют и обрабатывают информацию. Они, по сути, “запоминают” паттерны, а не учатся рассуждать, что делает их уязвимыми перед задачами, требующими логического вывода и адаптации к новым ситуациям. Этот архитектурный барьер препятствует развитию действительно интеллектуальных систем, способных к гибкому и надежному мышлению.
Для создания действительно надежных и адаптивных систем искусственного интеллекта необходимо разделение процессов восприятия и рассуждения. Современные модели, объединяющие зрение и язык, часто демонстрируют ограниченные возможности при решении сложных задач, требующих последовательного анализа и логических выводов. Разделение этих функций позволит создать более гибкую архитектуру, где модуль восприятия отвечает за извлечение информации из данных, а модуль рассуждения — за ее обработку и принятие решений. Такой подход, подобно тому, как функционирует человеческий мозг, потенциально позволит преодолеть текущие ограничения и добиться значительного прогресса в области искусственного интеллекта, обеспечивая способность к обобщению знаний и адаптации к новым ситуациям без необходимости постоянного увеличения масштаба модели. Это разделение — не просто техническая оптимизация, а принципиально новый взгляд на построение интеллектуальных систем.

DoGe: Двухэтапный Цикл Обучения для Усиления Рассуждений
DoGe использует двухэтапную структуру обучения, разделяя процесс на этапы «Обучение на основе контекста» и «Обучение на основе применения». Данный подход позволяет отделить понимание информации от ее практического использования. На первом этапе модель обучается глубокому анализу контекста, а на втором — применяет полученные навыки для решения новых задач. Разделение этапов позволяет более эффективно обучать модель рассуждениям, поскольку позволяет оптимизировать каждый этап обучения отдельно, фокусируясь на понимании контекста или на применении знаний.
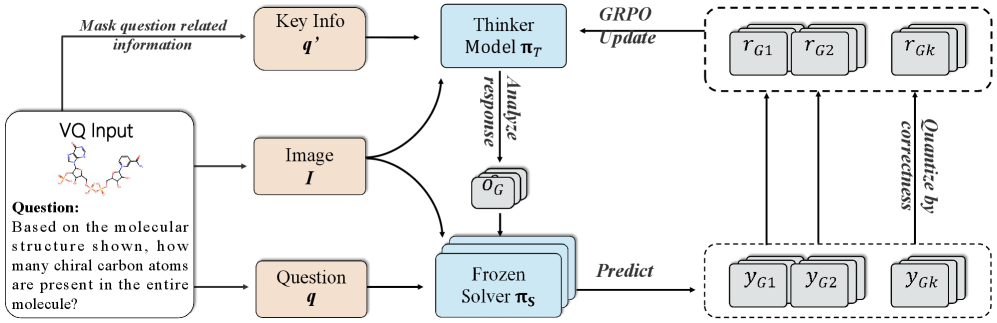
На первом этапе обучения, этапе “Обучение на контексте”, компонент “Мыслитель” (Thinker) тренируется для глубокого понимания информации. Для этого используется методика “Маскирование вопросов” (Question Masking), заключающаяся в намеренном скрытии части вопроса, что вынуждает модель анализировать полный контекст и взаимосвязи между элементами информации для восстановления недостающих данных и формирования более полного представления о проблеме. Это способствует развитию способности к глубокому контекстному анализу и улучшает качество извлечения знаний из предоставленных данных.
Второй этап, “Обучение через Применение”, использует компонент “Решатель” (Solver) для практического использования приобретенных навыков рассуждения на новых, ранее не встречавшихся задачах. Этот этап позволяет оценить эффективность обучения, проведенного на предыдущем этапе “Обучение из Контекста”, и продемонстрировать способность модели к обобщению знаний. “Решатель” получает задачи и генерирует решения, которые могут быть оценены с использованием стандартных метрик для определения точности и эффективности применения логических выводов, полученных в процессе обучения.
Оптимизация Механизма Рассуждений: Методы и Валидация
В DoGe для тонкой настройки политик рассуждений на обоих этапах обучающего цикла используется алгоритм обучения с подкреплением ‘Group Relative Policy Optimization’. Данный алгоритм обеспечивает устойчивость обучения за счет учета относительных изменений в группах параметров политики, что позволяет эффективно оптимизировать процесс рассуждений. В отличие от традиционных методов RL, ‘Group Relative Policy Optimization’ минимизирует влияние отдельных изменений параметров, обеспечивая более стабильное и предсказуемое поведение модели в процессе обучения и повышая общую производительность системы.
Эффективность разработанной системы была подтверждена посредством валидации в различных мультимодальных областях, включая решение задач по математике, химии и наукам о Земле. Проведенные тесты на семи стандартных бенчмарках продемонстрировали улучшение показателей в каждой из этих дисциплин, что подтверждает способность системы к обобщению и адаптации к разнообразным типам мультимодальных данных и задач. Конкретные бенчмарки и достигнутые улучшения детально описаны в разделе «Результаты экспериментов».
Для расширения обучающей выборки и повышения обобщающей способности, DoGe использует генерацию синтетических данных с помощью больших языковых моделей. Этот подход позволяет создавать разнообразные примеры, дополняющие реальные данные, что особенно полезно в задачах, где сбор достаточного объема размеченных данных затруднен или невозможен. Сгенерированные данные включают в себя как входные данные (например, изображения и текст), так и соответствующие ответы, что позволяет модели обучаться на более широком спектре сценариев и повышать свою устойчивость к новым, ранее не встречавшимся ситуациям. Использование больших языковых моделей для генерации синтетических данных позволяет автоматически создавать разнообразные и реалистичные примеры, что снижает потребность в ручной разметке и повышает эффективность обучения.
Развитие Навыков Рассуждений: Итеративное Обучение и Награда
В основе DoGe лежит концепция итеративного обучения с использованием “бассейна исходных задач”. Этот подход предполагает непрерывное обновление обучающих данных на протяжении всего процесса обучения. Система начинает с решения относительно простых задач из этого “бассейна”, а затем, по мере улучшения навыков решения, автоматически генерирует и добавляет более сложные примеры. Такая динамическая адаптация учебной программы позволяет модели постепенно совершенствовать свои способности к рассуждению, избегая застревания на задачах, которые оказываются слишком сложными на начальных этапах. Постоянно обновляемый набор задач стимулирует развитие более общих и гибких навыков решения, что, в свою очередь, приводит к повышению эффективности и адаптивности модели к новым, ранее не встречавшимся проблемам.
В рамках системы DoGe реализован механизм “Награды за формат”, который интегрирован в функцию вознаграждения и направляет “Решателя” на выдачу ответов в чётко определённой, интерпретируемой форме. Этот подход позволяет не только повысить удобство использования системы, но и облегчает автоматическую обработку и анализ результатов. Вместо простого определения правильности ответа, система оценивает и вознаграждает соответствие ответа заданному формату, например, структурированный список, логическое выражение или конкретный тип данных. Это существенно улучшает возможность интеграции системы в более сложные рабочие процессы и позволяет использовать ее результаты для дальнейших вычислений или анализа без необходимости дополнительной обработки или ручной корректировки.
Ключевым аспектом разработанной структуры является разделение процессов понимания контекста и применения полученных знаний, что обеспечивает эффективную передачу опыта и адаптацию к новым задачам. В отличие от традиционных подходов, где эти процессы тесно связаны, данная архитектура позволяет модели независимо совершенствовать способность к интерпретации информации и навык решения задач. Это разделение находит отражение в повышенной энтропии политики — показателе разнообразия принимаемых решений — и предотвращает «коллапс энтропии», когда модель ограничивается узким спектром действий. Благодаря этому, система демонстрирует повышенную гибкость и способность к обобщению, что подтверждается успешной адаптацией к разнообразным задачам и эффективным использованием накопленных знаний в новых условиях. Подобный подход позволяет модели не просто заучивать решения, а формировать глубокое понимание принципов, лежащих в основе решаемых задач.
Представленная работа демонстрирует стремление к созданию систем, способных к надёжному и воспроизводимому рассуждению. Разделение процесса обучения на этапы контекстного понимания и решения задач, как реализовано в DoGe, позволяет избежать феномена «взлома» системы вознаграждений, что особенно важно при ограниченном объёме данных. Этот подход согласуется с убеждением, высказанным Дональдом Кнутом: «Прежде чем оптимизировать код, убедитесь, что он работает правильно». Ведь прежде чем стремиться к эффективности, необходимо гарантировать детерминированность и корректность алгоритма, особенно в сложных системах, где неопределенность может привести к непредсказуемым последствиям. Подобный акцент на точности и воспроизводимости — залог надёжности и стабильности любой вычислительной системы.
Куда двигаться дальше?
Представленная работа, безусловно, демонстрирует элегантность разделения процесса обучения моделей «зрение-язык» на этапы контекстуального понимания и решения задач. Однако, красота этой архитектуры не должна заслонять фундаментальный вопрос: достаточно ли разделения, чтобы гарантировать истинную обобщающую способность? Неизбежно возникает вопрос о границах применимости данного подхода к более сложным, неструктурированным задачам, где контекст не всегда может быть четко выделен и формализован. Истинная проверка — это столкновение с данными, которые принципиально отличаются от тех, на которых модель обучалась, и выявление скрытых предположений, лежащих в основе ее «рассуждений».
Очевидным направлением дальнейших исследований является исследование возможностей адаптации предложенного подхода к сценариям с ограниченными вычислительными ресурсами. Эффективность обучения, безусловно, важна, но ее следует оценивать не только в терминах скорости сходимости, но и в терминах устойчивости к переобучению и способности к переносу знаний. Иначе, мы рискуем создать модель, прекрасно работающую в лабораторных условиях, но бесполезную в реальном мире.
В конечном счете, успех данного направления исследований будет зависеть от способности выйти за рамки простого улучшения метрик и начать задавать более глубокие вопросы о природе интеллекта и способности машин к истинному пониманию. Просто «работать на тестах» недостаточно; необходимо доказать корректность и предсказуемость алгоритма в самых разнообразных условиях.
Оригинал статьи: https://arxiv.org/pdf/2512.06835.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-10 02:36