Автор: Денис Аветисян
Новое исследование показывает, что эффективность современных моделей компьютерного зрения напрямую зависит от соответствия задач, на которых они обучались, и тех, которые им предстоит решать.
Ограничения переноса знаний в крупных моделях компьютерного зрения и роль согласованности задач при обучении и адаптации.
Несмотря на значительные вычислительные затраты, производительность моделей компьютерного зрения, обученных на больших объемах данных, зачастую оказывается неравномерной при решении различных задач. В работе ‘Understanding the Transfer Limits of Vision Foundation Models’ исследуются причины этого ограничения, связанные с несоответствием между целями предварительного обучения и требованиями прикладных задач. Показано, что более тесное соответствие между стратегиями предварительного обучения и задачами, для которых модели адаптируются, коррелирует с улучшением производительности и ускорением сходимости, что измеряется, в частности, метрикой максимального среднего расхождения (MMD). Каким образом можно оптимизировать стратегии предварительного обучения, чтобы максимизировать потенциал моделей компьютерного зрения для широкого спектра задач, особенно в специализированных областях, таких как медицинская диагностика?
Понимание сложной картины: необходимость точной оценки простаты
Точная и оперативная оценка изображений простаты, полученных методом магнитно-резонансной томографии (МРТ), имеет решающее значение для раннего выявления рака. Однако, существующие традиционные методы анализа часто сталкиваются с трудностями из-за присущей вариативности данных и их сложности. Различия в протоколах сканирования, индивидуальные особенности пациентов и технические ограничения оборудования приводят к неоднородности изображений, что затрудняет автоматическую обработку и интерпретацию результатов. Это, в свою очередь, может приводить к задержкам в диагностике, увеличению числа ложноположительных или ложноотрицательных результатов, и, как следствие, к снижению эффективности лечения. Поэтому разработка новых, более устойчивых к вариативности и сложных данных методов анализа МРТ простаты является приоритетной задачей современной медицинской визуализации.
Отсутствие надежных и обобщающих моделей представляет собой серьезную проблему в анализе простаты по данным МРТ. Существующие алгоритмы часто демонстрируют непостоянство результатов при работе с различными группами пациентов, что связано с индивидуальными особенностями анатомии и физиологии, а также с различиями в протоколах сканирования, применяемых в разных медицинских учреждениях. Это приводит к снижению точности диагностики и может потребовать дополнительных исследований для подтверждения или опровержения результатов, увеличивая нагрузку на медицинский персонал и задерживая начало необходимого лечения. Разработка моделей, способных адаптироваться к этим вариациям и обеспечивать стабильно высокие показатели точности независимо от характеристик пациента или используемого оборудования, является ключевой задачей для улучшения ранней диагностики рака предстательной железы.
Два подхода к построению представлений: ProFound и ProViCNet
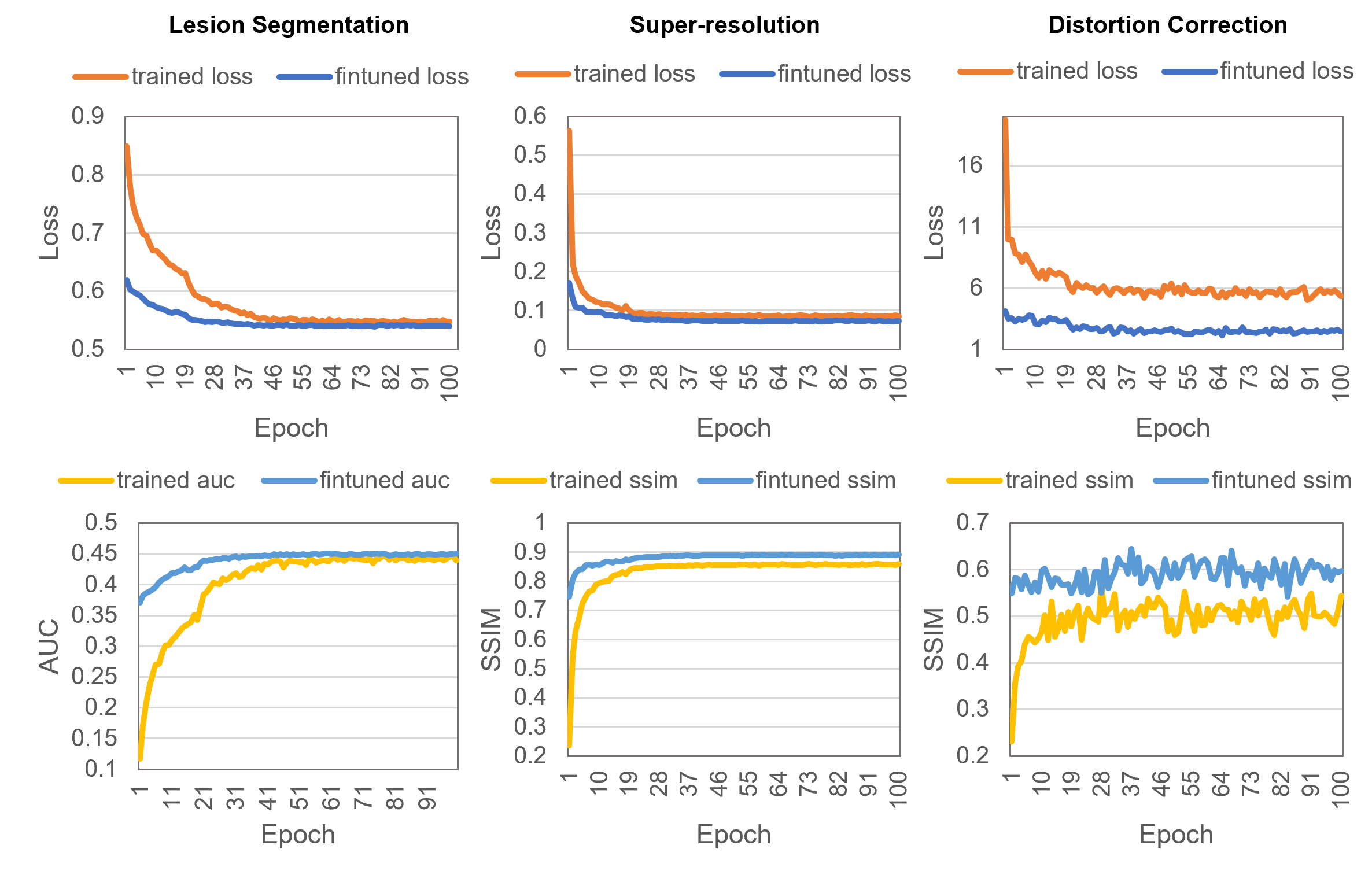
ProFound использует метод маскированной автокодировки (Masked Autoencoding) для обучения надежным векторным представлениям (embeddings) данных МРТ предстательной железы. В процессе обучения, часть входного изображения МРТ намеренно скрывается (маскируется), а модель обучается восстанавливать недостающие фрагменты на основе оставшейся информации. Этот подход вынуждает модель изучать значимые признаки и взаимосвязи в данных, что способствует формированию устойчивых векторных представлений, способных эффективно описывать анатомические и патологические особенности предстательной железы. Эффективность восстановления замаскированных областей служит индикатором качества полученных представлений.
В отличие от ProFound, ProViCNet использует DINOv2, метод, основанный на контрастном обучении, для извлечения дискриминативных признаков из изображений простаты. Контрастное обучение предполагает обучение модели различать похожие и непохожие изображения, что позволяет ей выделять наиболее информативные характеристики. В процессе обучения DINOv2 создает представления изображений, оптимизированные для выявления различий, что способствует более точному анализу и классификации патологий, обнаруживаемых на изображениях простаты.
Оба подхода, ProFound и ProViCNet, используют предварительное обучение на обширных наборах данных изображений простаты, полученных с помощью МРТ. Целью предварительного обучения является выявление и кодирование как анатомических особенностей строения предстательной железы, так и патологических изменений, таких как опухоли или воспаления. Использование больших объемов данных позволяет моделям усвоить разнообразные представления нормальной и патологической ткани, что способствует повышению точности и надежности последующего анализа и диагностики.
Количественная оценка качества представлений: измерение согласованности моделей
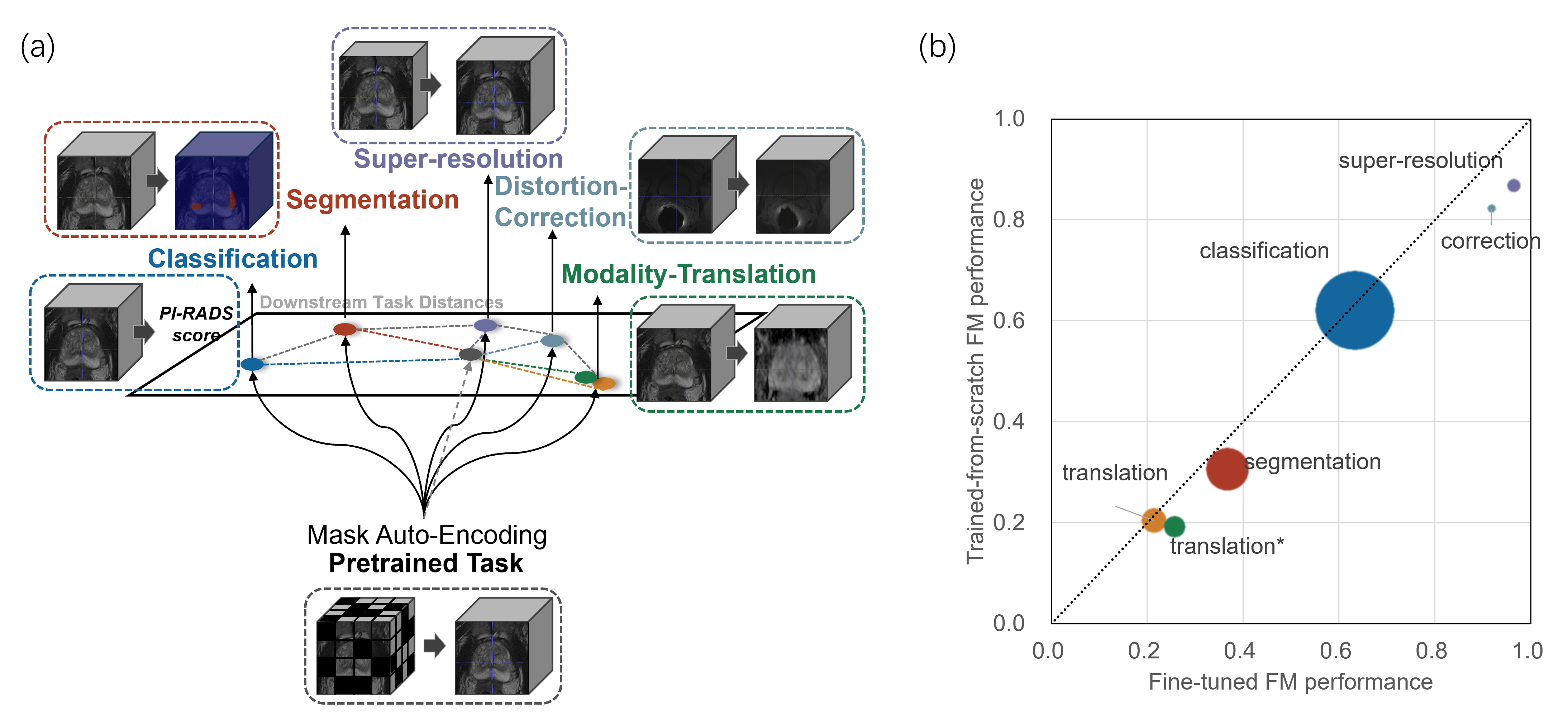
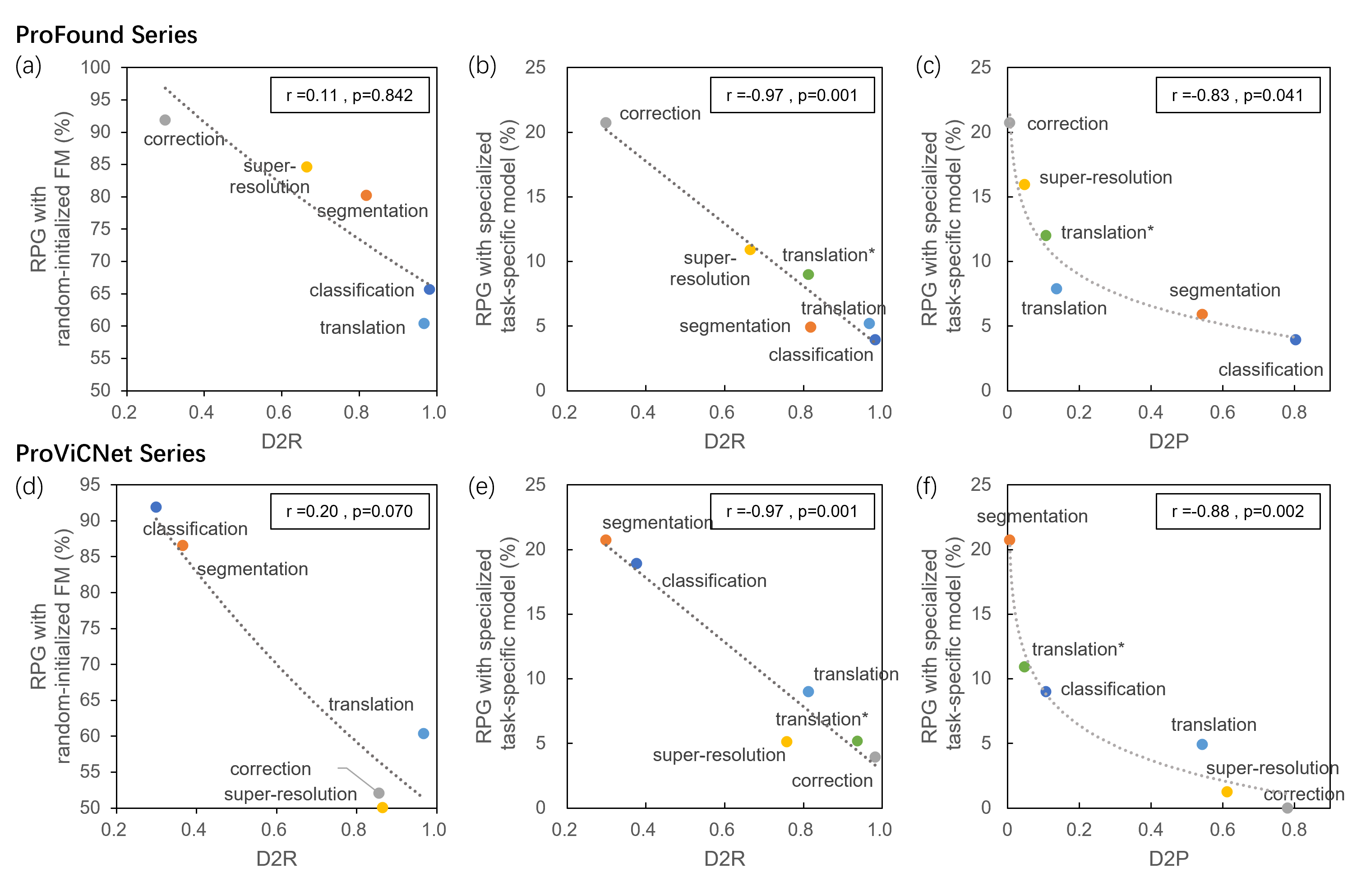
Метрики D2R (Distance to Random), D2P (Distance to Pretrained) и D2S (Distance to Same) используются для количественной оценки расстояния между векторными представлениями (embeddings) различных моделей. D2R измеряет расстояние между представлениями, полученными от тонко настроенной модели и случайным образом инициализированной модели, что позволяет оценить, насколько сильно тонкая настройка изменила исходные представления. D2P определяет расстояние между представлениями тонко настроенной модели и ее предобученной версии, указывая на степень выравнивания между этими двумя состояниями модели. D2S, в свою очередь, измеряет расстояние между представлениями двух одинаково тонко настроенных моделей, что может быть полезно для оценки стабильности и воспроизводимости процесса обучения. Все эти метрики рассчитываются на основе различных статистических мер, таких как L_2 норма или Maximum Mean Discrepancy (MMD), и служат для оценки степени согласованности и переноса знаний между моделями.
Квадрат отклонения максимальной средней разницы (MMD^2) предоставляет статистический подход к количественной оценке различий между распределениями вероятностей векторных представлений (эмбеддингов). В основе метода лежит вычисление расстояния между средними значениями эмбеддингов в пространстве признаков, взвешенных на основе ядерной функции. Использование MMD^2 позволяет оценить, насколько сильно различаются распределения признаков, полученные разными моделями или разными слоями одной и той же модели. Чем выше значение MMD^2, тем больше расхождение между распределениями, что указывает на меньшую степень сходства в представленных признаках. Данный метод особенно полезен для сравнения сложных распределений, где прямые метрики расстояния могут быть неэффективны.
Исследование продемонстрировало значимую корреляцию между выравниванием модели по задаче, измеряемым с помощью метрики D2P (расстояние между представлениями, полученными на целевой задаче и после предварительного обучения), и относительным приростом производительности (RPG). Коэффициент корреляции Пирсона составил -0.8 (p-value < 0.05), что указывает на сильную отрицательную связь: чем больше расстояние между представлениями (более низкое значение D2P, то есть лучшее выравнивание), тем выше относительный прирост производительности. Это свидетельствует о том, что D2P может служить надежным показателем эффективности переноса знаний от предварительно обученной модели к конкретной задаче.
Метрики расстояния между представлениями, такие как D2R, D2P и D2S, позволяют оценить эффективность переноса знаний из предобученных моделей в целевые задачи. Высокие значения этих метрик указывают на значительное расхождение между представлениями, что может свидетельствовать о низкой обобщающей способности признаков и, как следствие, о снижении производительности в новых задачах. Использование этих метрик позволяет количественно оценить, насколько хорошо признаки, полученные в процессе предобучения, применимы к новым данным и задачам, предоставляя информацию о потенциале обобщения модели и необходимости дальнейшей адаптации или обучения.
Влияние фундаментальных моделей: от сегментации до трансляции модальностей
Модели ProFound и ProViCNet продемонстрировали выдающиеся результаты в решении широкого спектра задач медицинской визуализации. Исследования показали, что они эффективно справляются с классификацией по шкале PI-RADS, сегментацией поражений, повышением разрешения изображений, коррекцией искажений и даже преобразованием между различными модальностями визуализации, такими как МРТ и КТ. Способность успешно адаптироваться к столь разнообразным задачам подчеркивает потенциал предварительно обученных представлений в захвате ключевых характеристик медицинских изображений и позволяет создавать универсальные модели, применимые в различных клинических сценариях. Это открывает возможности для снижения потребности в больших объемах размеченных данных для каждой конкретной задачи и упрощает разработку специализированных моделей.
Исследования показали, что модель ProFound демонстрирует наилучшее соответствие при коррекции искажений изображений, с показателем Representational Distance (D2P) всего 0.0057. Аналогично, ProViCNet достигла минимального D2P (0.0049) в задачах сегментации, что указывает на превосходную способность этих моделей к адаптации и точному воспроизведению характеристик изображений в соответствующих областях. Низкие значения D2P свидетельствуют о том, что внутренние представления, полученные моделями, тесно согласуются с ожидаемыми характеристиками идеальных изображений для коррекции искажений и точного выделения объектов на изображениях, что подтверждает эффективность предварительного обучения и возможности обобщения моделей.
Исследования показали, что способность моделей ProFound и ProViCNet успешно справляться с разнообразными задачами — от классификации по шкале PI-RADS до сегментации, повышения разрешения, коррекции искажений и трансляции модальностей — обусловлена силой предварительно обученных представлений. Эти представления позволяют моделям улавливать фундаментальные характеристики медицинских изображений, что существенно повышает их обобщающую способность. Вместо того, чтобы обучаться с нуля для каждой конкретной задачи, модели используют уже накопленные знания о визуальных особенностях, что приводит к более эффективному и точному выполнению различных операций обработки изображений. Этот подход демонстрирует, что предварительное обучение позволяет моделям выделять ключевые, общие черты изображений, независимо от конкретной задачи или модальности, обеспечивая тем самым высокую производительность и адаптивность.
Исследования показали, что модели ProFound и ProViCNet демонстрируют выдающиеся результаты в коррекции искажений и сегментации изображений, обеспечивая наибольший прирост относительной производительности — 20.72% для ProFound в задаче коррекции искажений и 21.23% для ProViCNet в сегментации. Эти показатели свидетельствуют о значительном улучшении точности и эффективности по сравнению с существующими методами, что подчеркивает способность предварительно обученных моделей эффективно адаптироваться к различным задачам обработки медицинских изображений и потенциально снижать потребность в больших объемах специализированных данных для обучения.
Исследования показали, что возможность эффективной адаптации фундаментальных моделей к различным задачам открывает перспективы для существенного сокращения объема необходимых для обучения данных и упрощения процесса разработки специализированных моделей. Вместо трудоемкого сбора и разметки больших объемов данных для каждой конкретной задачи, предлагаемый подход позволяет использовать уже предобученные представления, что значительно экономит ресурсы и время. Данная стратегия особенно актуальна в медицинской визуализации, где получение размеченных данных является сложной и дорогостоящей задачей. Успешная адаптация моделей, таких как ProFound и ProViCNet, к задачам классификации, сегментации, суперразрешения и коррекции искажений демонстрирует универсальность полученных представлений и указывает на потенциал для создания более эффективных и доступных инструментов для анализа медицинских изображений.
Вычислительные затраты и направления дальнейших исследований
Обучение и донастройка этих фундаментальных моделей требуют значительных вычислительных ресурсов, измеряемых в часах работы графических процессоров (GPU). Это создает существенный барьер для исследователей и клиницистов, не имеющих доступа к соответствующей инфраструктуре. Высокая стоимость вычислительных ресурсов ограничивает возможность проведения экспериментов, разработки новых подходов и адаптации моделей к специфическим задачам. В результате, прогресс в области применения этих технологий в клинической практике может замедлиться, а потенциальные преимущества останутся недоступными для широкого круга специалистов и пациентов. Необходимость в оптимизации процессов обучения и снижении вычислительной нагрузки становится критически важной для демократизации доступа к передовым достижениям в области искусственного интеллекта в медицине.
Перспективные исследования направлены на создание более экономичных стратегий обучения и архитектур моделей, что позволит существенно снизить вычислительные затраты. Разработка алгоритмов, требующих меньшего количества графических процессоров и времени для достижения сопоставимой точности, является ключевой задачей. Особое внимание уделяется оптимизации существующих моделей путем квантования, прунинга и дистилляции знаний, что позволит уменьшить их размер и сложность без значительной потери производительности. Кроме того, исследуются новые архитектуры, такие как трансформеры с разреженным вниманием и сверточные нейронные сети с более эффективными операциями, которые потенциально могут обеспечить сопоставимые результаты при значительно меньших вычислительных ресурсах. Успешная реализация этих подходов откроет возможности для более широкого использования мощных моделей в клинической практике и научных исследованиях, преодолевая текущие ограничения, связанные с дороговизной и доступностью вычислительных ресурсов.
Исследования в области адаптации к различным областям и обучения с небольшим количеством примеров представляются ключевыми для расширения применимости этих моделей в клинической практике. Существующие модели, обученные на ограниченном наборе данных или специфических протоколах визуализации, часто демонстрируют снижение производительности при работе с новыми популяциями пациентов или при изменении условий получения изображений. Разработка методов, позволяющих эффективно переносить знания, полученные на одном наборе данных, на другие, а также обучаться на небольшом количестве новых примеров, позволит значительно снизить потребность в больших, размеченных датасетах и адаптировать модели к широкому спектру клинических сценариев и протоколов визуализации, что, в свою очередь, повысит их практическую ценность и доступность для более широкого круга исследователей и врачей.
Исследование демонстрирует, что эффективность моделей компьютерного зрения напрямую зависит от соответствия задач предварительного обучения и последующей тонкой настройки. Это подчеркивает важность выявления структурных зависимостей в данных, поскольку модели, обученные на задачах, близких к целевым, демонстрируют лучшую обобщающую способность. Как однажды заметил Ян ЛеКун: «Машинное обучение — это не только алгоритмы, но и искусство представления данных». В контексте данной работы, соответствие задач предварительного обучения и тонкой настройки — это и есть искусство представления данных, позволяющее извлечь максимальную пользу из возможностей моделей компьютерного зрения и повысить эффективность переноса обучения, особенно в специализированных областях, таких как анализ изображений предстательной железы.
Что дальше?
Исследование закономерностей переноса знаний в фундаментальных моделях компьютерного зрения, представленное в данной работе, неизбежно наводит на размышления о границах этой самой «фундаментальности». Очевидно, что соответствие между задачами предварительного обучения и конечным применением — не просто техническая деталь, а ключевой фактор, определяющий эффективность передачи знаний. Однако, вопрос о том, как измерить это соответствие, остаётся открытым. Простое сравнение наборов данных, вероятно, недостаточно, поскольку скрытые закономерности в данных могут быть гораздо сложнее, чем кажется.
Попытки создания универсальных моделей, игнорирующих специфику предметной области, могут оказаться тупиковыми. Более перспективным представляется путь создания моделей, адаптируемых к конкретным задачам, возможно, с использованием мета-обучения или других методов, позволяющих быстро «настраиваться» на новые данные. При этом, необходимо учитывать, что «настройка» может приводить к потере обобщающей способности, что требует тщательного баланса между специализацией и универсальностью.
В конечном итоге, понимание границ переноса знаний требует не только технических усовершенствований, но и философского переосмысления самой концепции «интеллекта». Ведь, если модель способна эффективно решать только те задачи, для которых она была обучена, можно ли говорить о настоящем интеллекте, или это лишь сложный алгоритм, имитирующий разум?
Оригинал статьи: https://arxiv.org/pdf/2601.15888.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-26 04:08