Автор: Денис Аветисян
Исследователи представили инновационную систему, объединяющую возможности обработки языка и зрения для создания более эффективных и адаптивных роботов-навигаторов.
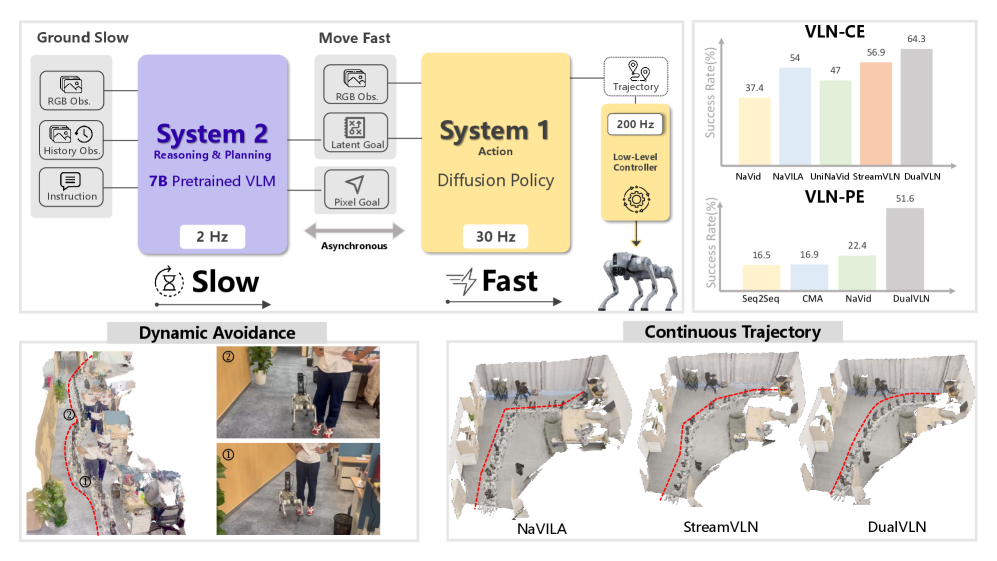
Предложенная модель DualVLN разделяет семантическое планирование и управление движением, используя большие языковые модели и диффузионные модели для обеспечения надежной навигации в реальном и виртуальном пространствах.
Несмотря на успехи современных моделей в области навигации по визуальным и языковым инструкциям, существующие подходы часто страдают от фрагментированности движений и сложностей в реальных динамических условиях. В данной работе, представленной под названием ‘Ground Slow, Move Fast: A Dual-System Foundation Model for Generalizable Vision-and-Language Navigation’, предлагается инновационная архитектура DualVLN, разделяющая семантическое планирование и непосредственное исполнение действий. Ключевая идея заключается в синергии глобального планировщика, основанного на большой языковой модели, и диффузионной политики для точного и оперативного управления в сложных средах. Позволит ли подобный подход создать действительно адаптивные и надежные системы навигации, способные эффективно функционировать в реальном мире?
Разделение и Власть: Зачем Разделять Восприятие и Действие
Традиционные модели навигации, основанные на обработке изображений и языка (VLN), часто сталкиваются с трудностями при решении сложных задач, требующих долгосрочного планирования. Основная проблема заключается в их монолитной архитектуре, где процессы восприятия, рассуждения и управления тесно переплетены. Это приводит к тому, что даже незначительные ошибки на ранних этапах обработки информации могут накапливаться и существенно влиять на конечный результат, особенно при навигации в больших и сложных пространствах. В отличие от более гибких систем, монолитные модели испытывают трудности с адаптацией к новым ситуациям и эффективным восстановлением после ошибок, что ограничивает их применимость в реальных условиях, требующих надежной и автономной навигации.
Для обеспечения надежной и адаптивной навигации, необходимо разделение процессов высокоуровневого планирования и низкоуровневого управления. Исследования показывают, что монолитные архитектуры, объединяющие эти функции, испытывают трудности в сложных сценариях, требующих долгосрочного планирования и принятия решений. Разделение позволяет системе сначала абстрагироваться от деталей окружающей среды и разработать общую стратегию движения, а затем, уже на более позднем этапе, преобразовывать эту стратегию в конкретные действия. Такой подход позволяет системе более эффективно адаптироваться к изменяющимся условиям, избегать препятствий и достигать цели даже в сложных и динамичных окружениях. По сути, разделение функций имитирует когнитивные процессы, где планирование и исполнение действий осуществляются разными модулями, что способствует повышению устойчивости и эффективности навигации.
Современные модели навигации, основанные на обработке визуальной информации и языка, зачастую демонстрируют ограниченные возможности в динамичных и визуально сложных средах. Исследования показывают, что существующие подходы испытывают трудности с эффективным планированием последовательности действий и их точным выполнением, особенно когда окружение меняется или содержит большое количество отвлекающих факторов. Это связано с тем, что большинство систем обрабатывают визуальную информацию и инструкции одновременно, не выделяя отдельные этапы для анализа ситуации, построения плана и реализации этого плана. В результате, даже небольшие изменения в окружающей среде могут привести к ошибкам навигации и снижению общей эффективности системы. Для преодоления этих ограничений необходима разработка новых архитектур, способных к более гибкому и адаптивному планированию действий в реальном времени.
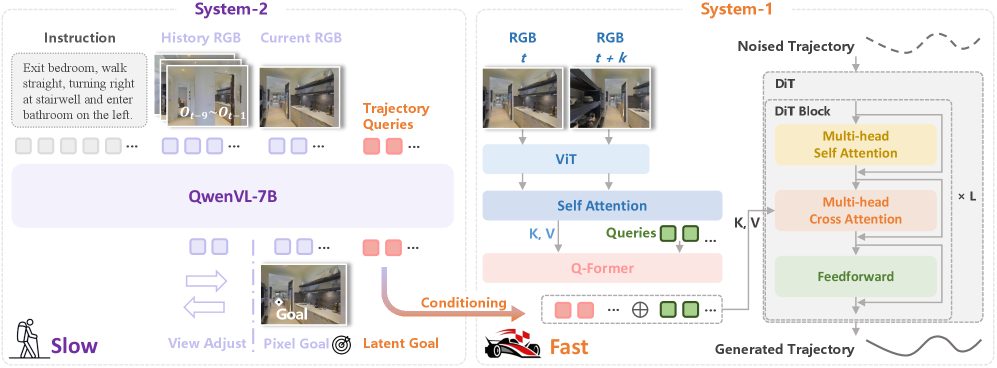
DualVLN: Архитектура Разделения для Интеллектуальной Навигации
Архитектура DualVLN представляет собой новый подход к навигации, основанный на разделении процесса на две отдельные системы: Система 1 и Система 2. Такое разделение позволяет более эффективно решать сложные задачи навигации. Система 1 отвечает за генерацию плавных и реализуемых траекторий движения, в то время как Система 2 занимается высокоуровневым планированием и определением целей. Данный подход позволяет отделить логику планирования от непосредственного управления движением, что повышает гибкость и масштабируемость системы в различных условиях и сценариях навигации.
Система 2 в DualVLN использует модель QwenVL2.5 с открытым исходным кодом для выполнения высокоуровневых рассуждений и генерации целей навигации. QwenVL2.5 является мощной моделью «зрение-язык», способной понимать визуальные данные и текстовые инструкции, что позволяет ей эффективно интерпретировать сложные навигационные задачи. В рамках DualVLN, система 2 отвечает за анализ входящих инструкций, определение конечной цели и генерацию последовательности промежуточных целей, необходимых для достижения этой цели. Эта архитектура позволяет отделить процесс планирования от процесса исполнения траектории, что повышает общую эффективность и надежность навигационной системы.
Система 1, использующая архитектуру Diffusion Transformer (DiT), преобразует высокоуровневые цели, полученные от Системы 2, в плавные и выполнимые траектории движения. DiT, как архитектура, основанная на механизмах диффузии, генерирует траектории путем последовательного уточнения случайного шума, направляемого целевым состоянием. Этот процесс позволяет системе создавать реалистичные и кинематически корректные пути, учитывающие ограничения робота и динамику окружающей среды. Использование DiT обеспечивает способность системы генерировать траектории, которые не только достигают заданной цели, но и характеризуются плавностью и естественностью движения.
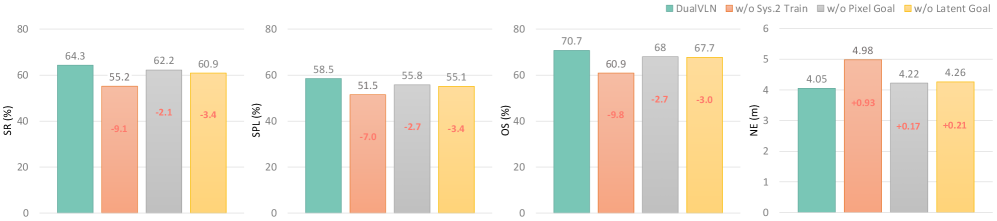
Взаимодействие Систем: Латентные Цели и Привязка к Пикселям
Эффективное взаимодействие между системами System 1 и System 2 критически зависит от скорости и точности передачи релевантной информации, необходимой для выполнения задачи. Задержки или неточности в передаче данных приводят к снижению производительности и увеличению вычислительных затрат. Оптимизация этого процесса включает в себя минимизацию объема передаваемой информации при сохранении ее информативности, а также использование эффективных протоколов и форматов данных для снижения времени передачи и обработки. Это особенно важно в системах, где требуется взаимодействие в реальном времени, например, в робототехнике или при обработке визуальной информации.
Представление латентных целей (Latent Goal Representation) обеспечивает компактный и информативный сигнал от Системы 2 к Системе 1, кодируя неявные цели. В отличие от явных команд, латентное представление передает высокоуровневые намерения в сжатом виде, что позволяет Системе 1 эффективно планировать траекторию без перегрузки детальной информацией. Этот подход использует векторное представление, отражающее желаемое состояние или результат, которое Система 1 может интерпретировать для достижения поставленной задачи. Компактность сигнала критична для снижения вычислительных затрат и повышения скорости реагирования системы, особенно в задачах, требующих принятия решений в реальном времени.
Явное задание целевых точек в пикселях, известное как Pixel Goal Grounding, предоставляет системе 1 конкретные ориентиры для навигации и планирования траектории. Методы, такие как Farthest Pixel Goal Grounding, определяют наиболее удалённую от текущей позиции точку в изображении как цель, обеспечивая более широкое исследование окружения. Self-Directed View Adjustment, в свою очередь, позволяет системе 1 самостоятельно корректировать угол обзора для улучшения видимости и точного определения целевых пикселей, что повышает эффективность планирования движения и достижение поставленных задач.
Система 1 использует латентные запросы (Latent Queries) для извлечения релевантной информации из латентных целей, предоставляемых Системой 2. Этот процесс позволяет уточнять планирование траектории, поскольку запросы выступают в качестве интерфейса для получения конкретных инструкций из сжатого представления целей. Фактически, Система 1 формирует запросы, чтобы детализировать абстрактные цели Системы 2, преобразуя их в практические параметры для навигации и выполнения задач. Эффективность этого механизма напрямую влияет на точность и скорость достижения конечной цели, обеспечивая согласованность действий обеих систем.

InternVLA-N1: Проверка в Реальных Условиях
Модель InternVLA-N1, разработанная на основе архитектуры DualVLN и интегрирующая в себя систему InternNav, демонстрирует передовые результаты в сложных эталонных задачах визуальной навигации (VLN). Благодаря сочетанию этих технологий, InternVLA-N1 превосходит существующие решения в задачах, требующих понимания визуальной информации и планирования маршрута в неизвестных средах. Эта модель не только успешно ориентируется в виртуальных пространствах, но и показывает способность к адаптации и обобщению, что подтверждается её высокими показателями в различных тестовых сценариях и делает её значительным шагом вперёд в области искусственного интеллекта и робототехники.
Модель InternVLA-N1 демонстрирует выдающиеся результаты в условиях динамичного окружения, что было подтверждено при оценке на бенчмарке Social-VLN. Исследование показало, что данный подход превосходит StreamVLN примерно на 27% по показателю успешности выполнения задач. Это значительное улучшение свидетельствует о способности системы эффективно ориентироваться и принимать решения в сложных, постоянно меняющихся условиях, где присутствуют другие агенты и препятствия. Высокая производительность в динамических сценариях открывает перспективы для применения данной технологии в широком спектре реальных задач, требующих автономной навигации и взаимодействия с окружающей средой.
В основе плавной и естественной навигации InternVLA-N1 лежит кодирование траектории в рамках System 1. Данный подход позволяет модели прогнозировать и учитывать будущие движения, избегая резких смен направления, характерных для многих других систем. Вместо того чтобы просто реагировать на текущее окружение, InternVLA-N1 формирует представление о вероятной траектории, что обеспечивает более уверенное и реалистичное перемещение в пространстве. Это достигается за счет анализа последовательности визуальных данных и сопоставления их с ожидаемым маршрутом, что позволяет системе заранее корректировать курс и избегать столкновений или ненужных маневров. По сути, кодирование траектории позволяет модели «предвидеть» оптимальный путь и следовать ему с большей точностью и плавностью.
Архитектура InternVLA-N1 отличается высокой модульностью, что существенно упрощает её адаптацию к различным средам и задачам. Такая конструкция позволяет исследователям и разработчикам легко интегрировать новые сенсоры, алгоритмы планирования траектории или даже модифицировать базовые компоненты системы без необходимости полной переработки. Модульность обеспечивает гибкость, позволяя быстро переносить знания, полученные в одной среде, в другую, и применять систему для решения разнообразных задач, от навигации в виртуальных пространствах до управления роботами в реальном мире. Это открывает перспективы для широкого спектра применений, включая создание интеллектуальных помощников, разработку систем автономной доставки и улучшение взаимодействия человека с окружающей средой.

Исследование демонстрирует, что разделение семантического планирования и непосредственного исполнения действий — подход, который, несмотря на свою кажущуюся элегантность, неизбежно столкнется с проблемами масштабирования и отладки в реальных условиях. Разделение на LLM для планирования и диффузионную модель для управления — лишь ещё один способ усложнить систему, добавляя абстракции, которые рано или поздно потребуют поддержки. Как отмечал Роберт Тарьян: «Хороший алгоритм — это не тот, который работает, а тот, который можно отладить». В данном случае, сложность отладки системы, состоящей из двух взаимосвязанных, но разных моделей, представляется весьма высокой. Практика показывает, что за красивой архитектурой неизбежно скрывается технический долг, который рано или поздно придётся выплачивать.
Куда это всё ведёт?
Представленная работа, безусловно, демонстрирует элегантность разделения семантического планирования и непосредственного исполнения действий. Однако, не стоит забывать, что любая архитектура, даже самая продуманная, неизбежно столкнётся с проблемами масштабируемости реального мира. «Социальная навигация» звучит красиво в симуляции, но стоит роботу столкнуться с хаотичным поведением людей, как все тщательно выверенные стратегии, вероятно, потребуют пересмотра. И, конечно, возникает вопрос: насколько хорошо «отделение» планирования и исполнения решит проблему обобщения? Ведь рано или поздно возникнет сценарий, в котором даже незначительное расхождение между планом и реальностью приведёт к катастрофическим последствиям.
Особенно интересно наблюдать за развитием «pixel goal grounding». Превращение визуальной информации в понятные инструкции — задача сложная, и текущие решения, скорее всего, являются лишь временными мерами. Более того, увлечение диффузионными моделями, несомненно, имеет право на существование, но необходимо помнить, что любое вероятностное решение несёт в себе риск непредсказуемого поведения. И если тесты проходят успешно, это не гарантия надежности, а лишь признак того, что тестовые сценарии были недостаточно разнообразными.
В конечном итоге, всё это — очередной шаг на пути к созданию автономных агентов. И, как показывает история, каждый «революционный» шаг неизбежно порождает новый уровень технического долга. Рано или поздно потребуется рефакторинг, оптимизация и, возможно, полное переосмысление текущих подходов. И, вероятно, через десять лет всё это будет называться иначе.
Оригинал статьи: https://arxiv.org/pdf/2512.08186.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-10 14:40