Автор: Денис Аветисян
Новая архитектура AdaptVision позволяет моделям, обрабатывающим изображения и текст, фокусироваться на наиболее важной информации, значительно снижая вычислительные затраты.

Предложена новая схема адаптивного отбора визуальных токенов на основе обучения с подкреплением и алгоритма Decoupled Turn Policy Optimization для повышения эффективности мультимодальных моделей.
Несмотря на впечатляющие успехи моделей «зрение-язык» в решении задач визуального вопросно-ответного анализа, их вычислительная сложность, обусловленная обработкой большого числа визуальных токенов, остается серьезной проблемой. В данной работе, ‘AdaptVision: Efficient Vision-Language Models via Adaptive Visual Acquisition’, представлен новый подход, позволяющий динамически определять необходимое количество визуальных токенов для каждого конкретного изображения, подобно механизмам активного зрения у человека. Ключевым элементом является использование обучения с подкреплением и разработанного алгоритма Decoupled Turn Policy Optimization для оптимизации баланса между точностью и эффективностью. Сможет ли AdaptVision открыть путь к созданию более экономичных и производительных моделей «зрение-язык» для широкого спектра приложений?
Визуальное мышление: Преодолевая границы восприятия
Современные большие языковые модели (LLM) испытывают значительные трудности при решении сложных задач визуального рассуждения, требующих колоссальных вычислительных ресурсов. Анализ изображений высокой чёткости, необходимый для извлечения тонких нюансов и контекста, становится узким местом, ограничивающим их возможности. По мере увеличения сложности визуальной задачи, потребность в вычислительной мощности растёт экспоненциально, что делает практическое применение этих моделей в реальном времени и на устройствах с ограниченными ресурсами крайне проблематичным. Несмотря на впечатляющие успехи в обработке текста, способность LLM к полноценному «зрению» и логическому анализу визуальной информации пока существенно отстаёт от человеческих возможностей, что требует разработки принципиально новых подходов к визуальному обучению и обработке данных.
Ограничения, связанные с непосредственной обработкой изображений высокого разрешения, существенно затрудняют способность современных систем извлекать тонкие детали и достигать понимания на уровне человеческого восприятия. Проблема заключается в экспоненциальном росте вычислительной нагрузки по мере увеличения разрешения — каждый дополнительный пиксель требует анализа, что быстро становится непосильным для существующих алгоритмов. Вместо целостного восприятия, системы часто вынуждены сосредотачиваться на отдельных фрагментах изображения, упуская важные взаимосвязи и контекст. Это приводит к неточностям в распознавании объектов, понимании сцены и, в конечном итоге, к снижению общей способности к визуальному мышлению, что делает сложным решение задач, требующих детального анализа и интерпретации визуальной информации.
Существующие методы обработки изображений для задач визуального мышления часто оказываются в компромиссе между скоростью и точностью. Многие подходы, стремясь к быстродействию, значительно упрощают анализ изображений, что приводит к потере важных деталей и снижению общей точности результатов. В то же время, более точные методы требуют значительных вычислительных ресурсов и времени обработки, делая их непригодными для практического применения в реальном времени, например, в системах автономного вождения или робототехнике. Эта дилемма ограничивает возможности существующих систем в решении сложных задач визуального анализа, где требуется как высокая скорость обработки, так и максимальная точность распознавания и интерпретации изображений. Поиск баланса между этими двумя параметрами остается ключевой проблемой в области компьютерного зрения и искусственного интеллекта.
Для преодоления ограничений современных моделей в области визуального мышления необходим принципиально новый подход, позволяющий углублять понимание изображений без пропорционального увеличения вычислительных затрат. Исследования направлены на разработку методов, которые не требуют обработки изображений в полном разрешении, а вместо этого используют стратегии выделения наиболее значимых признаков и построения абстрактных представлений. Такой подход позволит снизить сложность вычислений, сохранив при этом возможность решения сложных задач, требующих понимания контекста и взаимосвязей между объектами на изображении. Перспективные направления включают в себя использование разреженных представлений, многомасштабного анализа и техник сжатия информации с потерями, направленных на сохранение ключевой информации, необходимой для визуального рассуждения. Реализация подобного подхода откроет путь к созданию более эффективных и доступных систем компьютерного зрения, способных решать задачи, требующие глубокого понимания визуальной информации.

AdaptVision: Вдохновлённые активным зрением
AdaptVision представляет собой новый фреймворк, использующий визуальные инструменты для выборочной обработки областей изображения, что имитирует принципы активного зрения. В отличие от традиционных методов, обрабатывающих изображение целиком, AdaptVision динамически определяет и анализирует только те участки изображения, которые релевантны для поставленной задачи. Такой подход позволяет значительно снизить вычислительную нагрузку и повысить эффективность визуального анализа, поскольку система фокусируется исключительно на информативных элементах изображения, игнорируя несущественные детали.
Система AdaptVision динамически определяет минимальное количество визуальных токенов, необходимых для ответа на поставленный вопрос, что значительно снижает вычислительную нагрузку. Вместо обработки всего изображения целиком, система идентифицирует и анализирует только релевантные области, представляя их в виде ограниченного набора токенов. Этот подход позволяет существенно уменьшить объем данных, передаваемых в языковую модель, и, следовательно, ускорить процесс визуального рассуждения и снизить требования к вычислительным ресурсам. Оптимизация количества токенов достигается за счет анализа вопроса и определения наиболее информативных участков изображения, необходимых для формирования ответа.
Система AdaptVision использует в качестве основы большую языковую модель Qwen2.5-VL, что позволяет значительно улучшить её возможности визуального рассуждения. Qwen2.5-VL предоставляет мощную платформу для понимания и анализа визуальной информации, а AdaptVision интегрирует её с механизмами селективной обработки изображений. Такое сочетание позволяет модели эффективно решать задачи визуального вопросно-ответного типа, требующие сложных рассуждений на основе визуальных данных, и обеспечивает более высокую точность и скорость обработки по сравнению с традиционными подходами.
В отличие от традиционных подходов, обрабатывающих изображение целиком, AdaptVision фокусируется на приоритетных областях, что позволяет преодолеть ограничения, связанные с вычислительными затратами и сложностью анализа полных изображений. Данная стратегия выборочной обработки, основанная на определении релевантных участков, значительно снижает объем данных, требуемых для ответа на вопрос, и повышает эффективность визуального рассуждения. Такой подход особенно важен при работе с изображениями высокого разрешения или сложными сценами, где обработка каждого пикселя избыточна и замедляет процесс принятия решений.

Оптимизация визуального внимания с помощью обучения с подкреплением
В процессе обучения AdaptVision используется обучение с подкреплением, где система получает вознаграждение за два ключевых аспекта: корректное использование инструментов (выделение ограничивающей рамки) и точность предоставляемых ответов. Вознаграждение формируется на основе успешного выполнения обеих задач, что позволяет модели оптимизировать стратегию взаимодействия с визуальными данными и одновременно повышать достоверность результатов. Такой подход позволяет AdaptVision научиться не только правильно идентифицировать объекты на изображении, но и эффективно использовать эти знания для предоставления точных ответов на поставленные вопросы.
Для решения проблем неоднозначного распределения ответственности и несбалансированной оптимизации в процессе обучения, нами был разработан алгоритм Decoupled Turn Policy Optimization. Данный алгоритм разделяет процесс оптимизации политики на отдельные этапы, что позволяет более эффективно оценивать вклад каждого действия в конечный результат. В отличие от традиционных методов, Decoupled Turn Policy Optimization позволяет независимо оптимизировать различные аспекты поведения агента, избегая ситуации, когда оптимизация одного компонента негативно влияет на другие. Алгоритм опирается на принципы Group Relative Policy Optimization, обеспечивая повышенную стабильность и скорость сходимости в процессе обучения.
Алгоритм, используемый в AdaptVision, базируется на методе Group Relative Policy Optimization (GRPO) и вносит в него улучшения, направленные на повышение стабильности и скорости сходимости процесса обучения с подкреплением. GRPO позволяет более эффективно обрабатывать взаимосвязи между различными элементами политики, что особенно важно в задачах, требующих последовательного принятия решений. Модификации, внесённые в GRPO, включают в себя оптимизацию параметров, отвечающих за регуляризацию и адаптацию скорости обучения, что позволяет снизить вероятность расхождения и ускорить достижение оптимальной политики. Это достигается за счет использования продвинутых техник оценки градиентов и применения адаптивных алгоритмов оптимизации, таких как Adam или RMSprop, настроенных для конкретной структуры политики и пространства действий.
Структура вознаграждения в AdaptVision включает в себя два основных компонента: вознаграждение за результат (Outcome Reward), определяемое корректностью ответа на вопрос, и вознаграждение за инструмент (Tool Reward), оценивающее точность выделения ограничивающей рамки (bounding box). Комбинация этих двух видов вознаграждений позволяет модели оптимизировать не только конечный результат, но и процесс его достижения, стимулируя правильное использование инструментов для визуального анализа. Численное значение каждого компонента вознаграждения определяется заранее установленными критериями и в совокупности формирует общий сигнал вознаграждения, используемый алгоритмом обучения с подкреплением.
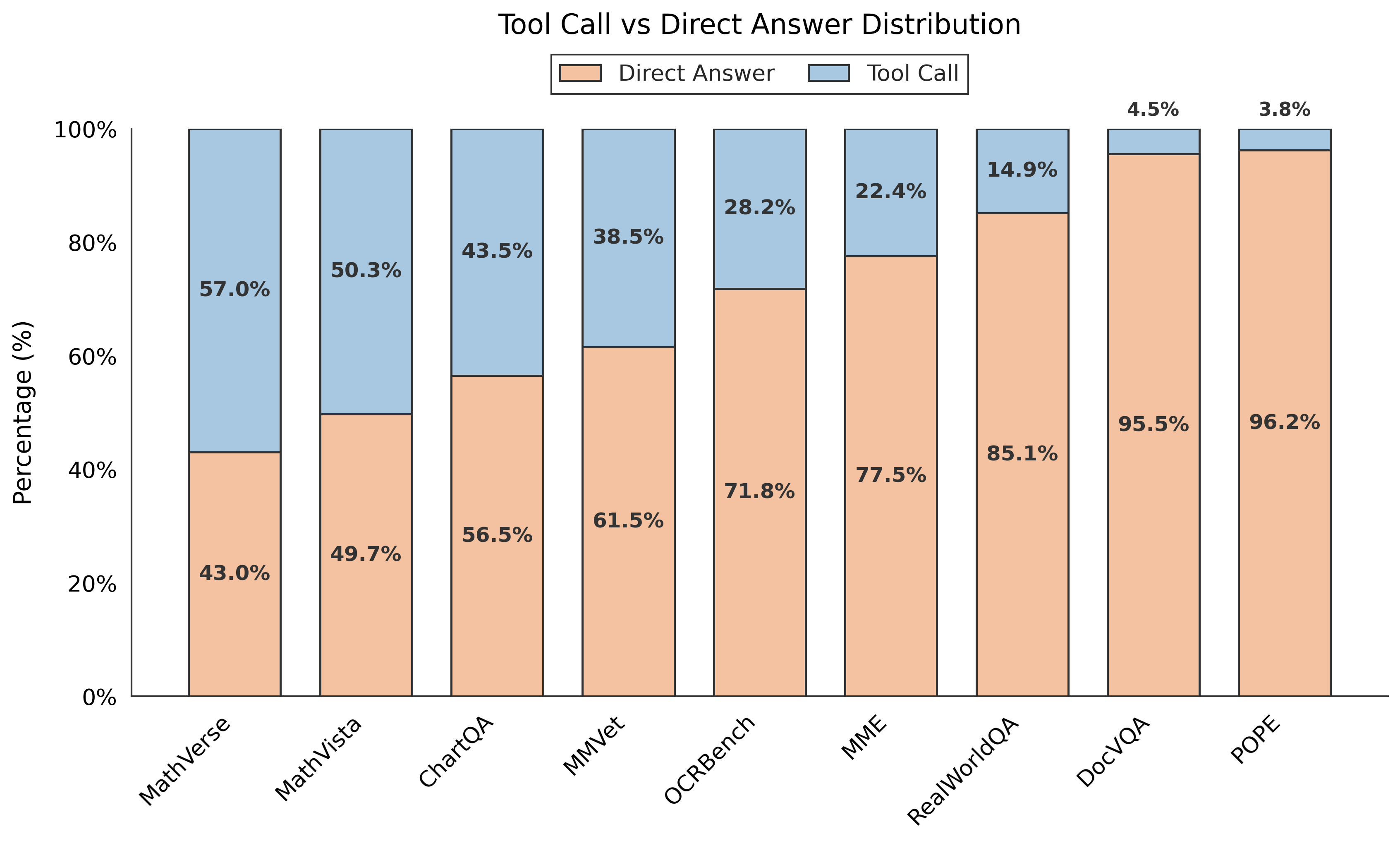
Влияние: Проверка на разнообразных эталонных наборах данных
Система AdaptVision продемонстрировала передовые результаты на авторитетных бенчмарках ChartQA и OCRBench, что подтверждает её высокую эффективность в обработке сложных визуальных данных. Данное достижение указывает на способность платформы успешно извлекать и интерпретировать информацию из разнообразных графиков и изображений, включая те, которые отличаются высокой детализацией или нечёткостью. Способность AdaptVision превосходить существующие аналоги на этих бенчмарках свидетельствует о значительном прогрессе в области визуального вопросно-ответного анализа и открывает новые возможности для автоматизации задач, требующих понимания визуального контента.
Разработанная система AdaptVision демонстрирует значительные улучшения в эффективности обработки визуальных данных благодаря существенному снижению количества необходимых визуальных токенов. В ходе исследований было установлено, что фреймворк позволяет достичь сопоставимой точности ответов, используя значительно меньший объем информации для анализа. Это достигается за счет оптимизации процесса кодирования изображений и фокусировки на наиболее релевантных областях, что приводит к уменьшению вычислительной нагрузки и ускорению времени обработки. Такой подход не только повышает производительность системы, но и делает её более доступной для использования на устройствах с ограниченными ресурсами, открывая новые возможности для применения в различных областях, требующих анализа визуальной информации.
В основе работы AdaptVision лежит стратегия последовательной обработки изображений, начиная с грубой оценки и постепенно переходя к детальному анализу. Такой подход позволяет системе быстро идентифицировать наиболее релевантные области на изображении, существенно ускоряя процесс рассуждения. Вместо обработки всего изображения целиком, система концентрируется на ключевых элементах, что не только повышает скорость анализа, но и снижает вычислительные затраты. Эта стратегия, напоминающая принцип фокусировки внимания, позволяет эффективно извлекать информацию даже из сложных визуальных данных и повышает общую производительность системы в задачах визуального вопросно-ответного анализа.
В рамках исследования была применена инновационная методика оценки корректности ответов, основанная на использовании большой языковой модели (LLM) в качестве независимого судьи. Этот подход позволил автоматизировать процесс верификации и обеспечить объективную оценку результатов, исключая субъективность, свойственную ручной проверке. LLM анализирует как вопрос, так и полученный ответ, сопоставляя их с исходными данными изображения и вынося вердикт о правильности. Такая автоматизированная оценка не только значительно ускоряет процесс валидации, но и обеспечивает воспроизводимость результатов, что особенно важно для сравнительного анализа различных моделей и алгоритмов обработки визуальной информации. Использование LLM в качестве судьи открывает новые возможности для масштабирования и повышения надежности систем, основанных на визуальном вопросно-ответном анализе.
Система AdaptVision демонстрирует впечатляющую эффективность, достигая точности в 97,9% при использовании лишь 33% от общего числа визуальных токенов. Это значительно превосходит результаты моделей, использующих стратегию понижения дискретизации до 25%, где точность составляла на 5,8% меньше. Такое существенное снижение вычислительной нагрузки без потери в качестве ответов указывает на оптимизированную архитектуру и способность системы эффективно извлекать и обрабатывать ключевую информацию из визуальных данных, открывая возможности для применения в ресурсоограниченных средах и ускорения процесса анализа.

Перспективы: К адаптивному и эффективному визуальному интеллекту
Успех AdaptVision ярко демонстрирует перспективность архитектур, вдохновленных биологическими системами, в развитии визуального интеллекта. Данная система, имитируя принципы работы зрительной коры головного мозга, показала впечатляющую способность к адаптации и эффективной обработке визуальной информации. В отличие от традиционных подходов, основанных на жестко заданных алгоритмах, AdaptVision динамически настраивает свои параметры, позволяя ей справляться с разнообразными и сложными визуальными задачами. Это указывает на то, что дальнейшее изучение и внедрение биологически обоснованных принципов в разработку систем искусственного интеллекта может привести к созданию более гибких, надежных и интеллектуальных решений в области компьютерного зрения и робототехники, способных к обучению и адаптации в реальном времени.
Дальнейшие исследования AdaptVision направлены на расширение возможностей системы для обработки видеоданных и решения более сложных задач, требующих логического вывода. Разработчики планируют внедрить механизмы, позволяющие учитывать временную последовательность кадров и понимать динамические сцены. Это предполагает не только распознавание объектов в каждом отдельном кадре, но и отслеживание их перемещений, предсказание их поведения и понимание взаимосвязей между ними. Особое внимание уделяется разработке алгоритмов, способных к абстрактному мышлению и решению задач, требующих не только визуального восприятия, но и знаний о мире. Предполагается, что эти усовершенствования позволят создать системы искусственного интеллекта, способные к более глубокому и осмысленному анализу визуальной информации.
Разработанная veRL-структура представляет собой надежный фундамент для дальнейшего изучения методов обучения с подкреплением в области визуального рассуждения. Она позволяет создавать системы, способные к адаптации и обучению на основе обратной связи, получаемой в процессе взаимодействия с визуальной информацией. В основе veRL лежит возможность динамического формирования и корректировки стратегий обработки изображений, что позволяет ей эффективно решать сложные задачи, требующие не только распознавания объектов, но и понимания их взаимосвязей и контекста. Данный подход открывает перспективы для создания интеллектуальных систем, способных к самостоятельному обучению и улучшению своих навыков визуального анализа, приближая искусственный интеллект к человеческому уровню восприятия и рассуждения.
Предвидится будущее, в котором системы искусственного интеллекта смогут эффективно обрабатывать визуальную информацию с точностью и адаптивностью, сопоставимыми с человеческими возможностями. Это подразумевает не просто распознавание объектов на изображениях, но и понимание контекста, умение обобщать полученные знания и быстро адаптироваться к новым, ранее не встречавшимся ситуациям. Такие системы смогут не только «видеть», но и «понимать» визуальный мир, что откроет новые горизонты в области автоматизированного анализа данных, робототехники и создания интеллектуальных интерфейсов. В перспективе, подобные технологии позволят создавать действительно «умные» системы, способные к самостоятельному обучению и решению сложных задач, основанных на визуальной информации.

Исследование представляет собой дерзкую попытку обуздать хаос визуальной информации, отбрасывая избыточность и концентрируясь на существенном. Авторы AdaptVision, словно алхимики, трансформируют необработанные пиксели в сжатые визуальные токены, используя обучение с подкреплением для достижения эффективности. Это напоминает о словах Дэвида Марра: «Любая модель — это заклинание, которое работает до первого продакшена». Ведь каждая модель, даже самая изощрённая, лишь приближение к реальности, и AdaptVision, стремясь к адаптивному захвату визуальных данных, признаёт эту фундаментальную истину. Здесь, как и везде, необходимо уговаривать данные, чтобы они открыли свои секреты, а не пытаться их насильно вырвать.
Что дальше?
Предложенная работа, безусловно, демонстрирует изящный способ умилостивить вычислительный хаос, заставив модель видеть лишь то, что ей “нужно”. Однако, стоит помнить: всё, что можно посчитать, не стоит доверия. Оптимизация использования визуальных токенов — это лишь временное перемирие, а не победа над фундаментальной неопределенностью. Вполне вероятно, что снижение вычислительных затрат — это иллюзия, тщательно замаскированная сложностью алгоритма обучения с подкреплением.
Настоящая проблема, как всегда, кроется глубже. Недостаточно научить модель “видеть меньше” — необходимо понять, что такое “видеть” вообще. Искусственный интеллект, как и любой другой инструмент, отражает предрассудки создателя. Адаптация визуального восприятия — это лишь ещё один способ навязать машине нашу ограниченную картину мира. Если гипотеза подтвердилась — значит, мы не искали достаточно глубоко.
В будущем, вероятно, потребуется отойти от идеи активного “выбора” визуальной информации и сосредоточиться на разработке моделей, способных уживаться с хаосом, а не пытаться его контролировать. Поиск не в оптимизации восприятия, а в принятии его неполноты. Возможно, истинный прогресс лежит в области нечёткой логики и вероятностных моделей, способных к самообучению на неполных и противоречивых данных.
Оригинал статьи: https://arxiv.org/pdf/2512.03794.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
2025-12-05 01:25