Автор: Денис Аветисян
Новое исследование показывает, что высокая точность методов восстановления пропущенных значений не гарантирует адекватную оценку неопределенности результатов.

Систематический анализ различных методов восстановления данных с акцентом на калибровку неопределенности и оценку ошибок.
Несмотря на значительный прогресс в методах восстановления пропущенных данных, оценка надежности получаемых оценок неопределенности часто остается за пределами внимания. В данной работе, ‘Beyond Accuracy: An Empirical Study of Uncertainty Estimation in Imputation’, представлено систематическое эмпирическое исследование, сравнивающее различные методы восстановления пропущенных значений с точки зрения точности и калибровки оценки неопределенности. Полученные результаты показывают, что высокая точность восстановления данных не гарантирует надежную калибровку оценки неопределенности, что подчеркивает важность учета обоих аспектов при очистке данных и построении моделей машинного обучения. Какие конфигурации методов восстановления данных обеспечивают оптимальный баланс между точностью, калибровкой и вычислительной эффективностью?
Неполнота данных: вызовы и пути к достоверности
Неполные данные — повсеместная проблема в реальных наборах данных, представляющая серьезную угрозу для достоверности аналитических выводов и точности создаваемых моделей. Отсутствие информации, даже в относительно небольшом объеме, может приводить к систематическим ошибкам и искажениям, влияющим на интерпретацию результатов и снижающим прогностическую силу моделей. Эта проблема особенно актуальна в областях, где сбор данных сопряжен с трудностями, таких как медицина, социология и экономика, где потеря данных может быть обусловлена множеством факторов — от отказа респондентов до технических сбоев при регистрации информации. В итоге, игнорирование проблемы неполных данных приводит к принятию ошибочных решений и формированию неверных представлений о изучаемых явлениях, подчеркивая важность разработки и применения эффективных методов работы с ними.
Традиционные подходы к обработке пропущенных данных, такие как удаление наблюдений со значениями, которые отсутствуют (listwise deletion), или замена пропущенных значений средним арифметическим, часто приводят к существенным искажениям в анализе. Удаление наблюдений, хотя и простое, может значительно уменьшить размер выборки и, следовательно, снизить статистическую мощность исследования, особенно если пропуски не случайны. В свою очередь, простая подстановка среднего значения игнорирует взаимосвязи между переменными и приводит к занижению дисперсии, искажая оценки стандартных ошибок и вводя смещение в результаты. Это особенно критично при анализе сложных данных, где даже незначительные искажения могут привести к ошибочным выводам и неверным решениям, подчеркивая необходимость применения более сложных и адекватных методов импутации.
Понимание механизмов, лежащих в основе пропусков данных, имеет решающее значение для выбора адекватных стратегий их восполнения. Различают три основных типа пропусков: MCAR (Missing Completely At Random) — когда пропуски происходят совершенно случайно и не связаны с другими переменными; MAR (Missing At Random) — когда пропуски зависят от других наблюдаемых переменных, но не от самой пропущенной; и MNAR (Missing Not At Random) — когда пропуски связаны с самой пропущенной переменной, даже после учета других факторов. Неправильный выбор метода импутации, основанный на неверной оценке типа пропусков, может привести к смещенным результатам и неверным выводам. Например, применение простого среднего для данных с типом MNAR неизбежно внесет значительную погрешность. Таким образом, тщательный анализ причин пропусков является необходимым этапом подготовки данных для обеспечения достоверности и надежности анализа.

Классические методы импутации: фундамент и границы применимости
Метод множественного заполнения пропусков по цепным уравнениям (MICE) представляет собой итеративный процесс, в котором для заполнения каждого пропущенного значения используется регрессионная модель, построенная на основе других доступных переменных. Эффективность MICE напрямую зависит от корректности предположений о механизме возникновения пропусков. В частности, предполагается, что пропуски являются либо Missing At Random (MAR), то есть зависят от наблюдаемых переменных, либо Missing Completely At Random (MCAR). Если данные не соответствуют этим предположениям, например, при Missing Not At Random (MNAR), когда пропуски зависят от самого пропущенного значения, результаты, полученные с помощью MICE, могут быть смещены и неточны. Корректная спецификация регрессионных моделей и проверка предположений о механизме пропусков являются критически важными для обеспечения надежности результатов, полученных с использованием MICE.
Метод SoftImpute использует минимизацию ядерной нормы ($||X||_*$) для решения задачи импутации данных, рассматриваемой как задача завершения матрицы. В основе алгоритма лежит предположение о том, что данные имеют низкий ранг, что позволяет эффективно восстанавливать недостающие значения путем поиска матрицы с наименьшей ядерной нормой, наиболее близкой к наблюдаемым данным. Ядерная норма является суммой сингулярных чисел матрицы и выступает в качестве выпуклой релаксации ранга, обеспечивая вычислительную эффективность и гарантируя существование решения. Этот подход особенно эффективен в задачах, где наблюдаемые данные формируют разреженную матрицу, и позволяет получить правдоподобные оценки недостающих значений, минимизируя ошибки реконструкции.
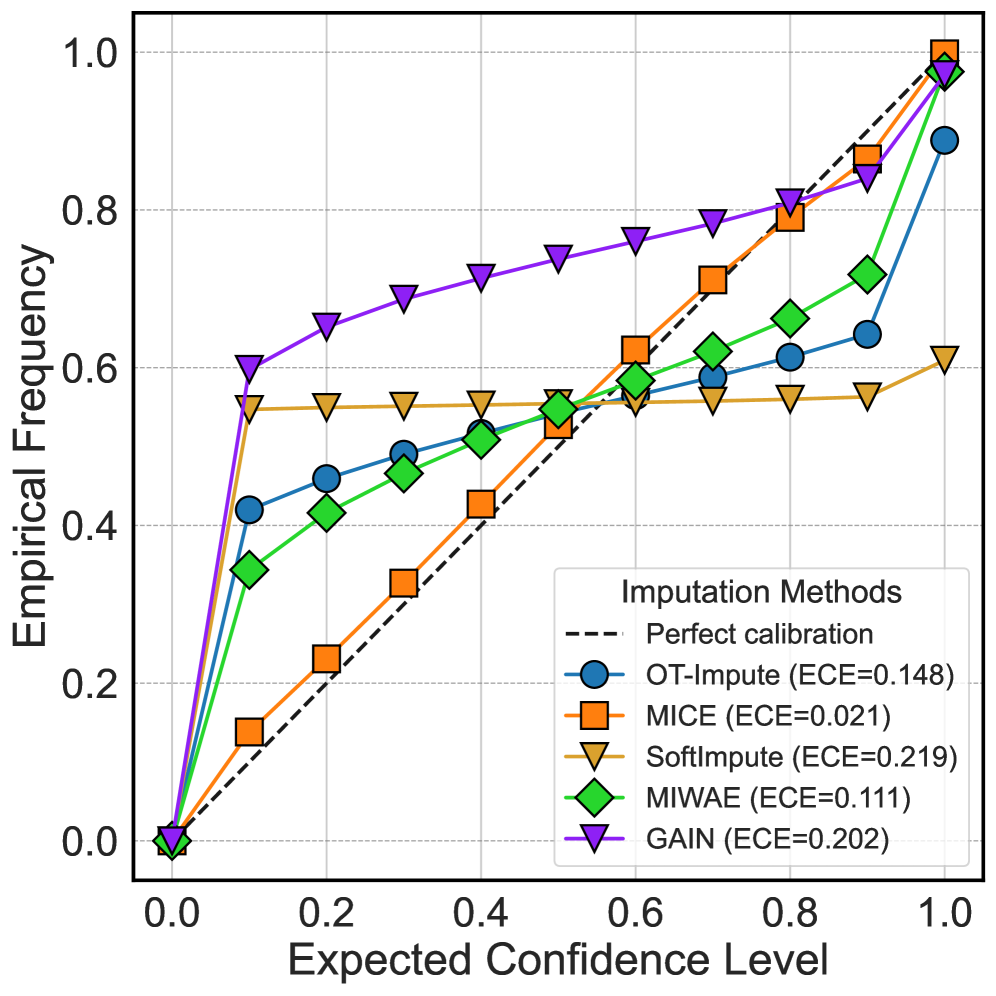
Классические методы импутации, такие как MICE и SoftImpute, демонстрируют эффективность в определенных сценариях, однако их производительность снижается при работе с данными высокой размерности и сложными взаимосвязями между признаками. Это обусловлено тем, что эти методы часто не способны адекватно моделировать сложные зависимости, что приводит к увеличению ошибки калибровки (Expected Calibration Error, ECE). ECE является метрикой, оценивающей расхождение между предсказанной уверенностью модели и фактической точностью, и более высокие значения ECE указывают на неточность оценок вероятностей, что может негативно сказаться на последующем анализе и принятии решений. Современные подходы, использующие, например, нейронные сети или градиентный бустинг, часто позволяют добиться более низкой ECE в подобных случаях, обеспечивая более надежные результаты импутации.
Современные методы машинного обучения для импутации: генеративные и состязательные подходы
Вариационные автоэнкодеры (VAE) представляют собой мощный фреймворк для обучения латентным представлениям данных, что позволяет эффективно выполнять импутацию посредством реконструкции. В основе VAE лежит идея кодирования входных данных в вероятностное латентное пространство, описываемое распределением. Затем, декодер реконструирует исходные данные из этого латентного представления. При импутации, VAE обучается на данных с пропущенными значениями, и латентное пространство используется для генерации правдоподобных значений для этих пропусков. Этот процесс позволяет модели учитывать взаимосвязи между признаками и генерировать импутированные значения, которые соответствуют общему распределению данных. Реконструкция данных из латентного пространства минимизирует ошибку между исходными и реконструированными значениями, что приводит к более точной импутации.
Генеративные состязательные сети для заполнения пропусков (GAIN) используют принципы состязательного обучения для генерации реалистичных значений для недостающих данных. В основе метода лежит взаимодействие двух нейронных сетей: генератора и дискриминатора. Генератор создает заполненные данные, стремясь минимизировать расхождения между наблюдаемыми и заполненными значениями, в то время как дискриминатор пытается отличить заполненные данные от реальных. Этот состязательный процесс приводит к тому, что генератор обучается создавать заполнения, которые статистически неотличимы от реальных данных, что повышает точность и правдоподобность импутации. Обучение происходит путем минимизации функции потерь, включающей как потери генератора, так и дискриминатора, обеспечивая баланс между точностью заполнения и реалистичностью сгенерированных данных.
Метод TabCSDI (Tabular Conditional Score-based Diffusion Imputer) использует диффузионную модель для итеративного уточнения значений пропущенных данных. В основе лежит процесс постепенного добавления шума к исходным данным, а затем — обучения модели для обратного процесса — удаления шума и восстановления исходного распределения данных. Особенностью TabCSDI является условное моделирование, которое позволяет учитывать наблюдаемые значения при восстановлении пропущенных. Это достигается путем подачи наблюдаемых данных в модель в качестве условия при генерации заполненных значений, что позволяет более точно воспроизводить сложные зависимости в данных и повышает качество заполнения, особенно в случаях с мультимодальными распределениями и сложными корреляциями между признаками. Итеративный характер процесса позволяет модели постепенно уточнять свои предсказания, приближаясь к наиболее вероятным значениям пропущенных данных.
Несмотря на то, что модель MIWAE (Multiple Imputation with Weighted Autoencoders) обычно демонстрирует наименьшую среднюю абсолютную ошибку ($MAE$) при заполнении пропущенных значений, её калибровка зачастую оставляет желать лучшего. Это подтверждается более высокими значениями ожидаемой калибровки ошибок ($ECE$) по сравнению с методом MICE (Multiple Imputation by Chained Equations). Более высокие значения $ECE$ указывают на то, что предсказанные вероятности MIWAE менее надежны и не соответствуют фактической частоте ошибок, что может быть критично в приложениях, требующих точной оценки неопределенности.

Калибровка неопределенности: оценка надежности импутированных данных
Для оценки неопределенности, связанной с заполненными (imputed) значениями, применяются методы, основанные на построении прямой предсказывающей функции распределения. Вместо получения единственного заполненного значения, алгоритмы, такие как множественные прогоны (Multiple Runs) или выборка из обученной модели, позволяют получить распределение вероятностей для каждого заполненного значения. Это дает возможность оценить не только наиболее вероятное значение, но и диапазон возможных значений с соответствующими вероятностями. Такой подход существенно расширяет возможности анализа данных, позволяя учитывать неопределенность, возникающую в процессе заполнения пропусков, и избегать переоценки точности полученных результатов. По сути, вместо простой замены пропущенных данных на единственное значение, предлагается целое распределение, отражающее степень уверенности в заполнении.
Кривые калибровки представляют собой визуальный инструмент для оценки соответствия между прогнозируемыми вероятностями и фактической частотой наступления событий. По сути, они позволяют проверить, насколько хорошо модель оценивает свою собственную уверенность в предсказаниях. Если кривая калибровки отклоняется от диагонали, это указывает на систематическую ошибку в оценке неопределенности. Например, если модель часто предсказывает события с вероятностью 90%, но в реальности они происходят лишь в 70% случаев, кривая будет находиться ниже диагонали, указывая на завышенную уверенность. Анализ кривых калибровки позволяет выявить смещения в оценках неопределенности и, следовательно, повысить надежность и интерпретируемость моделей, особенно в критически важных приложениях, где точная оценка вероятностей имеет первостепенное значение.
Ошибка ожидаемой калибровки ($ECE$) представляет собой количественную меру расхождения между прогнозируемыми вероятностями и фактически наблюдаемыми частотами. По сути, она измеряет, насколько хорошо предсказанные вероятности отражают реальную достоверность импутированных значений. Низкое значение $ECE$ указывает на то, что модель хорошо откалибрована — то есть, если модель предсказывает вероятность 0.8 для определенного значения, это значение действительно наблюдается примерно в 80% случаев. В противоположность этому, высокое значение $ECE$ свидетельствует о систематической переоценке или недооценке вероятностей, что указывает на смещение в оценке неопределенности импутированных данных. Таким образом, $ECE$ служит ценным инструментом для оценки надежности и достоверности методов импутации, позволяя выявить и скорректировать потенциальные погрешности в оценке неопределенности.
Исследование выявило устойчивый компромисс между точностью восстановления пропущенных данных и калибровкой неопределенности. В частности, метод MICE (Multiple Imputation by Chained Equations) демонстрирует стабильно более низкие значения Expected Calibration Error ($ECE$), что указывает на более надежную оценку неопределенности в импутированных значениях. В то же время, метод MIWAE (Missing Imputation with Variational Autoencoders) обычно превосходит MICE по метрике Mean Absolute Error ($MAE$), свидетельствуя о более высокой общей точности восстановления данных. Таким образом, выбор оптимального метода зависит от приоритетов: если важна надежная оценка неопределенности, предпочтение следует отдать MICE, а если ключевым является достижение максимальной точности восстановления, MIWAE представляется более эффективным решением.
Продвинутые методы: согласование распределений с помощью оптимального транспорта
Метод OT-Impute использует принципы оптимального транспорта для выравнивания распределений признаков в данных, содержащих пропуски. В основе подхода лежит идея минимизации “стоимости” перемещения вероятностной массы между распределениями наблюдаемых и пропущенных данных. Такой способ позволяет сгладить различия, возникающие из-за неполноты информации, и создать более когерентный и реалистичный набор данных после импутации. Вместо простого заполнения пропусков средними значениями или случайными числами, OT-Impute стремится сохранить структурные особенности данных, что особенно важно при анализе сложных взаимосвязей между признаками. Благодаря этому, импутированные данные более точно отражают истинное распределение, повышая надежность и качество последующего анализа.
Метод OT-Impute формирует более согласованные и реалистичные наборы данных, заполняя пропущенные значения посредством минимизации “стоимости транспортировки массы” между распределениями признаков. В основе подхода лежит концепция оптимального транспорта — математического инструмента, позволяющего определить наиболее эффективный способ перемещения вероятностной массы из одного распределения в другое. Благодаря этому, заполненные значения не просто статистически соответствуют исходным данным, но и учитывают их структуру и взаимосвязи, что особенно важно для сложных и многомерных данных. Фактически, метод стремится к созданию заполненного набора данных, который максимально близок к исходному с точки зрения распределения вероятностей, обеспечивая тем самым более надежные результаты анализа и моделирования.
Подход, основанный на оптимальном транспорте для заполнения пропущенных данных, открывает перспективные возможности для повышения устойчивости и надежности методов импутации в сложных аналитических сценариях. В ситуациях, когда данные характеризуются высокой размерностью, сложными взаимосвязями и значительным количеством пропусков, традиционные методы часто демонстрируют снижение эффективности и могут приводить к искажению результатов. Использование принципов оптимального транспорта позволяет не просто заменить пропущенные значения, но и сохранить структуру и взаимосвязи в данных, минимизируя «стоимость» переноса вероятностной массы между распределениями признаков. Это, в свою очередь, способствует созданию более когерентных и реалистичных наборов данных, что особенно важно для повышения точности моделей машинного обучения и обеспечения воспроизводимости научных исследований в областях, где обработка неполных данных является нормой.
Исследования показали, что методы восстановления пропущенных данных различаются по вычислительной сложности. В частности, алгоритм TabCSDI требует наибольших ресурсов, что делает его применение затруднительным при работе с очень большими наборами данных. В то же время, метод MICE (Multiple Imputation by Chained Equations) демонстрирует существенно более высокую скорость работы, становясь предпочтительным вариантом для задач, где критична производительность и требуется быстрое получение результатов. Разница в скорости обусловлена принципиально разными подходами: TabCSDI использует сложные вычисления для сопоставления распределений данных, в то время как MICE применяет итеративные регрессии для заполнения пропусков, что требует меньше вычислительных затрат.
Исследование показывает, что высокая точность восстановления данных при заполнении пропусков не всегда гарантирует адекватную оценку неопределенности. Это особенно заметно при использовании генеративных моделей, где кажущаяся правдоподобность результата может скрывать существенные погрешности. В этой связи, замечание Джона фон Неймана: «В науке не бывает абсолютной точности, лишь степени неопределенности». Игнорирование оценки неопределенности подобно строительству системы на шатком фундаменте — кажущаяся стабильность обманчива. Как подчеркивает исследование, модульность методов заполнения пропусков без учета общей картины данных не дает реального контроля над качеством результата, а лишь создает иллюзию понимания.
Куда двигаться дальше?
Наблюдаемая диссонанция между точностью и калибровкой неопределенности в методах импутации данных намекает на фундаментальную проблему. Подобно тому, как сложно создать идеально сбалансированный организм, где каждая часть функционирует в гармонии с целым, стремление к высокой точности без учета надежности оценки неопределенности представляется неполным решением. Простое исправление одной части системы (повышение точности) может привести к непредсказуемым последствиям в других областях (плохая калибровка).
Дальнейшие исследования должны сосредоточиться не только на разработке новых алгоритмов импутации, но и на более глубоком понимании механизмов, лежащих в основе плохо откалиброванной неопределенности. Важно изучить, как различные механизмы пропусков данных влияют на надежность оценок, и разработать методы, способные адаптироваться к этим особенностям. Попытки создать универсальные решения, игнорирующие сложность лежащих в основе процессов, представляются наивными.
В конечном итоге, истинный прогресс требует смещения фокуса с простого повышения точности на создание систем, способных не только заполнять пропуски, но и достоверно оценивать степень своей уверенности в этих заполнениях. Иначе говоря, необходимо стремиться к созданию не просто точных, но и честных моделей, признающих границы своей компетенции. Иначе, мы рискуем построить сложные системы, основанные на иллюзии знания.
Оригинал статьи: https://arxiv.org/pdf/2511.21607.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Джозефсоновские переходы на квантовых материалах: новые горизонты сверхпроводимости
- Искусственный интеллект проектирует белки: новый горизонт биоинженерии
- Квантовый скачок в многомасштабном моделировании
- Батарея под контролем: Искусственный интеллект на страже долговечности
- Искусственный интеллект и кодер: меняется ли подход к разработке?
2025-11-30 22:15