Автор: Денис Аветисян
Исследователи разработали систему, способную значительно ускорить вычисления матричных произведений на графических процессорах, используя возможности машинного обучения.
CUDA-L2, система на основе обучения с подкреплением и больших языковых моделей, превосходит производительность cuBLAS и cuBLASLt в задачах HGEMM.
Несмотря на десятилетия оптимизации, ядра CUDA для умножения матриц остаются областью для дальнейших улучшений производительности. В статье «CUDA-L2: Surpassing cuBLAS Performance for Matrix Multiplication through Reinforcement Learning» представлена система CUDA-L2, использующая большие языковые модели и обучение с подкреплением для автоматической оптимизации ядер вычислений HGEMM. Показано, что CUDA-L2 превосходит современные библиотеки, такие как cuBLAS и cuBLASLt, обеспечивая прирост производительности до 28.7% в серверном режиме. Может ли этот подход LLM-guided RL открыть новые горизонты для автоматической оптимизации критически важных вычислительных ядер и дальнейшего повышения эффективности GPU?
Узкое Место Современного Глубокого Обучения: Оптимизация GEMM
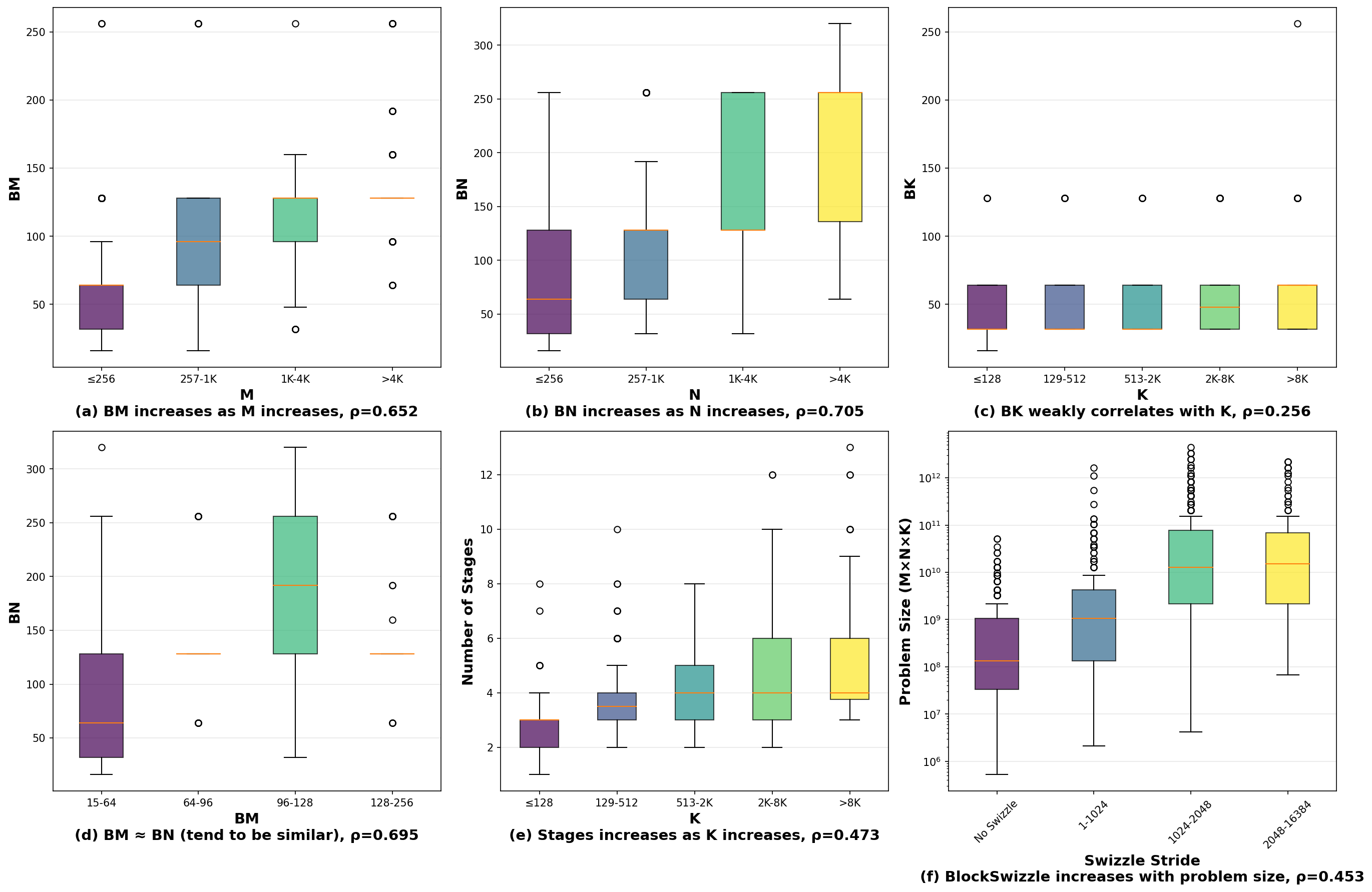
Современные рабочие нагрузки, связанные с глубоким обучением, и особенно те, что лежат в основе крупных языковых моделей, фундаментально ограничены производительностью операции общего матричного умножения (GEMM). По сути, подавляющее большинство вычислительных ресурсов тратится именно на выполнение $GEMM$, поскольку она является ключевым компонентом практически всех слоев нейронных сетей. Увеличение размеров моделей и объемов данных, используемых для обучения, лишь усиливает эту проблему, делая $GEMM$ узким местом, определяющим общую скорость и эффективность процесса. Таким образом, оптимизация $GEMM$ становится критически важной задачей для дальнейшего прогресса в области глубокого обучения и создания более мощных и эффективных моделей.
Традиционные методы оптимизации, такие как ручная настройка и использование библиотек вроде cuBLAS, постепенно исчерпывают свой потенциал в повышении производительности. Исторически, значительные улучшения достигались за счет кропотливой оптимизации кода ядра для конкретного оборудования и за счет использования высокооптимизированных библиотек, содержащих реализации $GEMM$ (General Matrix Multiplication). Однако, с ростом сложности моделей глубокого обучения и увеличением размеров матриц, дальнейшее повышение эффективности становится все более затруднительным. Увеличение тактовой частоты процессоров и снижение задержек памяти дают все меньше выигрыша, а дальнейшая ручная оптимизация требует огромных временных затрат и не гарантирует существенных улучшений. Возникает необходимость в автоматизированных подходах и новых алгоритмах, способных адаптироваться к различным аппаратным платформам и архитектурам моделей, чтобы преодолеть существующие ограничения и обеспечить дальнейший прогресс в области глубокого обучения.
Современные нейронные сети, особенно крупные языковые модели, демонстрируют экспоненциальный рост сложности. Это предъявляет всё более высокие требования к эффективности вычислений, в частности, к оптимизации ядра General Matrix Multiplication (GEMM). Традиционные методы, основанные на ручной настройке и использовании статических библиотек вроде cuBLAS, приближаются к пределу своей эффективности. В связи с этим, возникает необходимость в принципиально новом подходе к оптимизации ядра, который бы автоматизировал процесс, адаптировался к меняющимся архитектурам моделей и превосходил ограничения, накладываемые статическими библиотеками. Данный подход предполагает использование методов машинного обучения и автоматического поиска оптимальных конфигураций ядра, позволяя динамически адаптировать вычисления к специфическим потребностям каждой модели и каждого аппаратного обеспечения, что открывает путь к значительному увеличению производительности и снижению энергопотребления.
CUDA-L2: Интеллектуальная Оптимизация Ядер для Глубокого Обучения
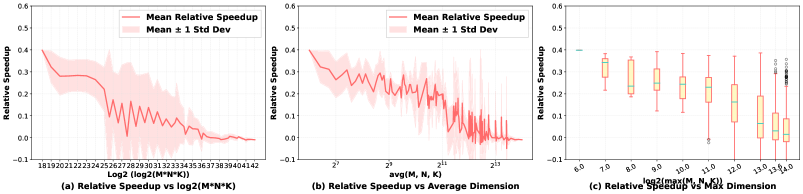
CUDA-L2 представляет собой новую систему автоматической оптимизации CUDA-ядер, предназначенных для операций GEMM (General Matrix Multiplication). В основе системы лежит комбинация больших языковых моделей (LLM) и обучения с подкреплением (RL). LLM используется для понимания и генерации оптимизированного кода ядра, а RL-агент, ориентируясь на метрики профилирования NCU, осуществляет поиск оптимальных параметров ядра в широком пространстве возможных конфигураций. Данный подход позволяет автоматически повысить производительность вычислений GEMM без ручной настройки параметров ядра.
Система CUDA-L2 использует подход предварительного обучения большой языковой модели (LLM) на обширном наборе CUDA-кода. Этот процесс позволяет LLM усваивать синтаксис, семантику и паттерны оптимизации, характерные для CUDA-программ. В результате, модель приобретает способность понимать существующие реализации ядер и генерировать оптимизированные варианты, адаптированные к конкретным задачам GEMM. Такое предварительное обучение значительно повышает эффективность последующего обучения с подкреплением, поскольку LLM уже обладает базовыми знаниями о структуре и оптимизации CUDA-кода, что ускоряет процесс поиска оптимальных параметров и улучшает общую производительность.
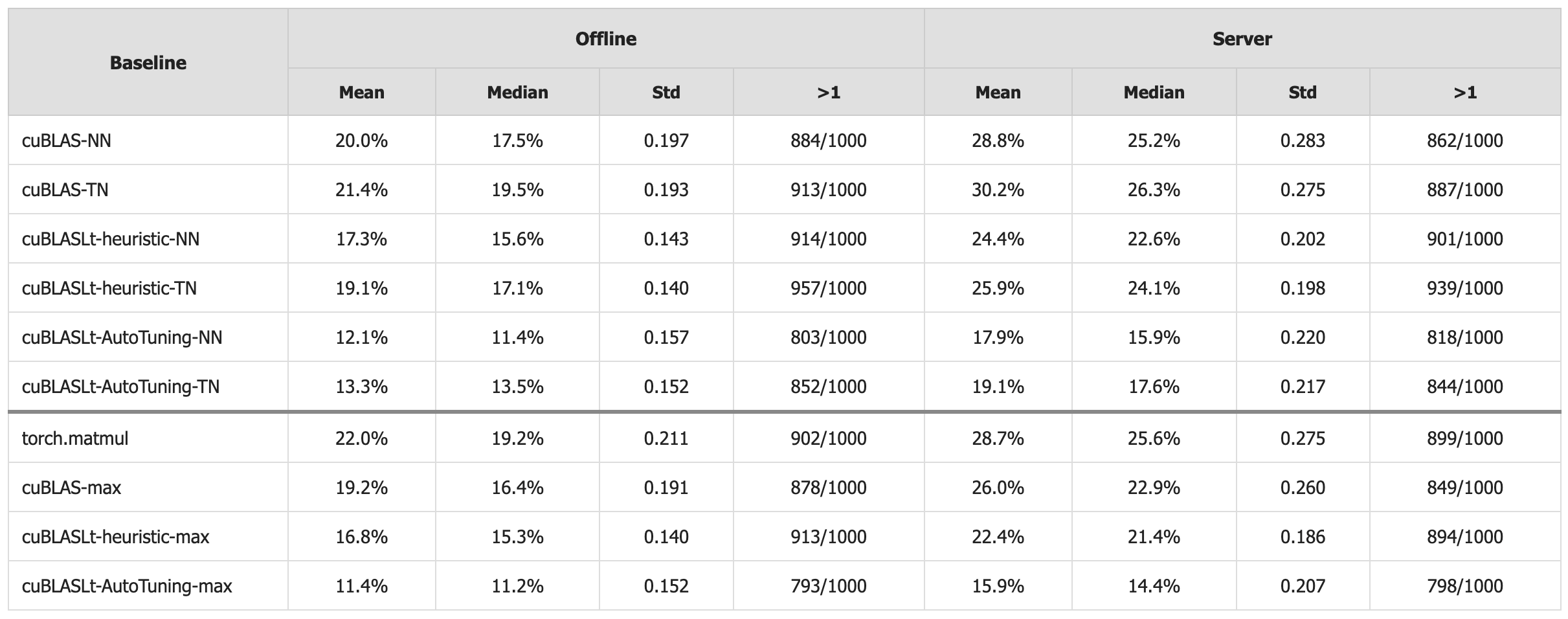
В системе CUDA-L2 агент обучения с подкреплением (RL) использует метрики профилирования NCU для автоматической настройки параметров ядра и исследования пространства оптимизации. В ходе тестирования, проведенного на 1000 различных конфигурациях, CUDA-L2 показал среднее ускорение в 11.4% по сравнению с библиотекой автоматической настройки NVIDIA cuBLASLt в автономном режиме (offline mode) и 15.9% в серверном режиме (server mode). Метрики NCU обеспечивают обратную связь, необходимую для обучения RL-агента и эффективного поиска оптимальных параметров ядра для GEMM.
Улучшение Оптимизации с Помощью Контекста и Продвинутых Методов
CUDA-L2 использует механизм Retrieval-Augmented Context, позволяющий ему обращаться к информации об архитектуре целевого оборудования и применять проверенные практики оптимизации во время процесса. Этот подход предполагает, что система извлекает релевантные данные о характеристиках GPU, таких как количество ядер, размер кэша и пропускная способность памяти, а также использует накопленный опыт оптимизации различных типов ядер. Полученная информация используется для принятия обоснованных решений в процессе оптимизации, что позволяет CUDA-L2 адаптироваться к конкретным аппаратным условиям и достигать более высокой производительности по сравнению со стандартными методами оптимизации.
Обучение с подкреплением (RL) в CUDA-L2 реализовано в многоэтапном режиме для последовательного повышения сложности оптимизации. Первоначально, RL-агент тренируется на оптимизации общих типов ядер, что позволяет ему освоить базовые принципы и стратегии. После достижения стабильных результатов на общих ядрах, процесс обучения переходит к более специализированным ядрам, предназначенным для матричного умножения (matmul). Такой подход позволяет агенту эффективно использовать накопленный опыт и адаптировать его к специфическим требованиям matmul-операций, обеспечивая более высокую производительность и стабильность оптимизации.
Для повышения локальности памяти и пропускной способности данных в оптимизированных ядрах CUDA-L2 используются такие передовые методы, как Block Swizzling и Multi-Stage Pipelining. В ходе оффлайн-тестирования, CUDA-L2 демонстрирует прирост производительности в 22.0% по сравнению с torch.matmul, 19.2% по сравнению с cuBLAS и 16.8% по сравнению с cuBLASLt-heuristic. Данные результаты подтверждают эффективность применяемых техник в оптимизации матричных умножений и повышении общей производительности вычислений.
Подтверждение Производительности и Влияние на Практику
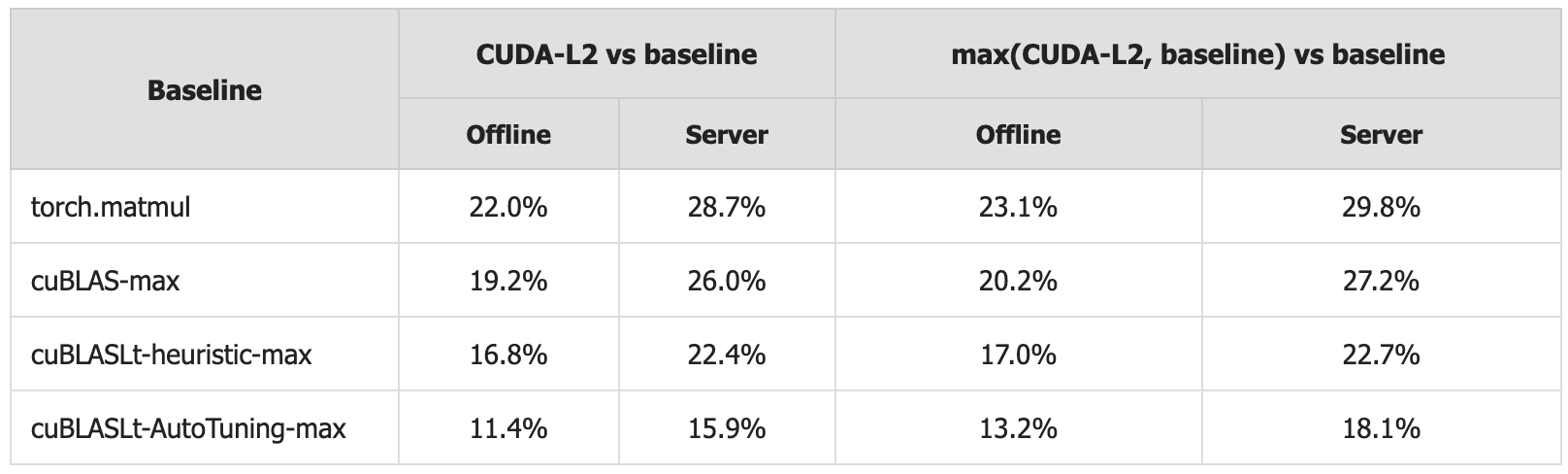
Всестороннее тестирование, проведенное в режимах Offline и Server, однозначно демонстрирует превосходство CUDA-L2 над библиотеками cuBLAS и cuBLASLt по ключевым показателям производительности. В ходе экспериментов, CUDA-L2 последовательно демонстрировала более высокие значения пропускной способности и меньшую задержку при выполнении операций линейной алгебры, являющихся основой для многих алгоритмов машинного обучения. Данные результаты подтверждают, что CUDA-L2 способна обеспечить значительный прирост эффективности в задачах, связанных с глубоким обучением, особенно в сценариях, требующих высокой скорости обработки данных и минимального потребления энергии. Это превосходство делает CUDA-L2 перспективным инструментом для разработки более быстрых, эффективных и устойчивых систем искусственного интеллекта.
Разработка CUDA-L2 открывает значительные возможности для повышения производительности задач глубокого обучения, особенно в сценариях инференса. Превосходя устоявшиеся библиотеки, такие как cuBLAS и cuBLASLt, CUDA-L2 позволяет существенно ускорить процесс получения результатов из обученных моделей. Это достигается благодаря оптимизированным алгоритмам и эффективному использованию аппаратных ресурсов, что приводит к снижению задержек, увеличению пропускной способности и, как следствие, к более быстрому и эффективному развертыванию моделей в реальных приложениях. В итоге, CUDA-L2 способствует созданию более отзывчивых и масштабируемых систем искусственного интеллекта, способных обрабатывать большие объемы данных с минимальными затратами энергии.
Достигнутое повышение производительности непосредственно влияет на ключевые параметры современных систем искусственного интеллекта. В ходе тестирования в серверном режиме, CUDA-L2 продемонстрировала значительное ускорение по сравнению с существующими решениями: на 28.7% быстрее, чем torch.matmul, на 26.0% быстрее, чем cuBLAS, и на 22.4% быстрее, чем cuBLASLt-heuristic. Это выражается в снижении задержки обработки данных, увеличении пропускной способности и, что особенно важно, в уменьшении энергопотребления. Такие улучшения открывают путь к созданию более эффективных и экологичных систем искусственного интеллекта, способных решать сложные задачи с меньшими затратами ресурсов и воздействием на окружающую среду.
Будущее Автоматической Оптимизации Ядер
Интеграция больших языковых моделей (LLM) и обучения с подкреплением (RL) в рамках CUDA-L2 формирует мощную основу для автоматической оптимизации ядер, способную адаптироваться к постоянно меняющимся аппаратным и программным условиям. Данный подход позволяет системе не только находить оптимальные параметры ядра для конкретной архитектуры GPU в данный момент времени, но и динамически приспосабливаться к новым поколениям оборудования и изменениям в программном обеспечении. В отличие от традиционных методов, требующих ручной настройки и глубокого понимания архитектуры, CUDA-L2 использует LLM для понимания структуры кода ядра и генерации стратегий оптимизации, а RL — для оценки эффективности этих стратегий и их дальнейшей доработки. Такая синергия позволяет значительно сократить время разработки и повысить производительность приложений, особенно в областях, где требуется максимальная эффективность вычислений, например, в задачах искусственного интеллекта и глубокого обучения.
Предстоящие исследования направлены на значительное расширение возможностей CUDA-L2, охватывая более широкий спектр вычислительных ядер и внедряя инновационные методы оптимизации. В частности, планируется адаптировать систему к различным архитектурам графических процессоров и усовершенствовать алгоритмы обучения с подкреплением, что позволит достигать еще более высоких показателей производительности. Особое внимание будет уделено оптимизации ядер, использующих сложные структуры данных и алгоритмы, а также исследованию новых подходов к параллелизации и управлению памятью. Разработка и внедрение этих улучшений позволит CUDA-L2 стать еще более мощным и универсальным инструментом для автоматической оптимизации, способствуя ускорению развития искусственного интеллекта и научных вычислений.
Предвидится, что автоматизированные инструменты оптимизации, подобные CUDA-L2, станут ключевым фактором в раскрытии всего потенциала современного аппаратного обеспечения. Такие системы позволят разработчикам значительно ускорить вычислительные процессы, освободив их от рутинной настройки и тонкой оптимизации кода. В перспективе, это приведет к существенному прогрессу в области искусственного интеллекта, поскольку более эффективные вычисления позволят создавать и обучать более сложные и мощные модели. Автоматизация оптимизации станет особенно важна для решения задач, требующих огромных вычислительных ресурсов, таких как обработка больших данных, машинное обучение и научные симуляции, открывая новые возможности для инноваций и открытий.
Исследование демонстрирует, что оптимизация производительности вычислений, в частности, умножения матриц, может быть значительно улучшена за счет использования методов машинного обучения с подкреплением. Система CUDA-L2, представленная в работе, эффективно находит оптимальные конфигурации CUDA-ядер, превосходя производительность традиционных библиотек, таких как cuBLAS. Это подтверждает важность целостного подхода к проектированию систем, где оптимизация одной части требует понимания общей структуры. Как однажды заметил Джон фон Нейманн: «В науке не бывает готовых ответов, только более или менее полезные вопросы». Данное исследование, задавая новые вопросы в области автоматической оптимизации, открывает путь к созданию более эффективных и адаптивных вычислительных систем.
Что Дальше?
Представленная работа демонстрирует, что автоматизация оптимизации CUDA-ядер посредством обучения с подкреплением и использования больших языковых моделей — путь, безусловно, перспективный. Однако, кажущийся успех не должен заслонять фундаментальные вопросы. Если система кажется сложной, она, вероятно, хрупка. Повышение производительности умножения матриц — лишь вершина айсберга; истинная проблема заключается в создании систем, способных адаптироваться к постоянно меняющейся архитектуре GPU и требованиям задач. Архитектура — искусство выбора того, чем пожертвовать, и пока неясно, какие компромиссы неизбежны при стремлении к абсолютной производительности.
Очевидным направлением для будущих исследований представляется расширение области применения данной методики за пределы умножения матриц. Автоматическая оптимизация других вычислительно интенсивных операций, таких как свёртки или преобразования Фурье, может принести значительную пользу. При этом важно учитывать, что каждый алгоритм имеет свои особенности, и универсального решения, вероятно, не существует. Необходимо разрабатывать специализированные стратегии обучения с подкреплением, учитывающие специфику каждой задачи.
В конечном итоге, успех подобного подхода будет зависеть не только от алгоритмических усовершенствований, но и от развития инструментов для анализа и верификации оптимизированного кода. Оптимизация ради оптимизации — путь в никуда. Необходимо гарантировать, что повышение производительности не приводит к ухудшению стабильности или увеличению энергопотребления. Иначе, кажущаяся победа окажется пирровой.
Оригинал статьи: https://arxiv.org/pdf/2512.02551.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Искусственный интеллект в роли астрофизика: эксперимент с задачами
- Где большие языковые модели терпят неудачи в программировании?
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Сеть, управляемая интеллектом: новые возможности для экспериментов
- Наука больших команд и широких горизонтов
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2025-12-03 19:13