Автор: Денис Аветисян
Новое исследование предлагает метод автоматического обучения моделей оценки мультимодальных данных, избавляя от необходимости дорогостоящей ручной разметки.

Разработана система самообучения моделей-судей, использующая синтетические данные предпочтений и итеративное улучшение для оценки соответствия изображений и текстовых описаний.
Несмотря на стремительное развитие моделей «зрение-язык» (VLM), оценка их качества традиционно требует дорогостоящих и быстро устаревающих аннотаций, созданных людьми. В статье «Self-Improving VLM Judges Without Human Annotations» представлен новый подход к обучению оценочных моделей для VLM, основанный на автоматической генерации и фильтрации синтетических данных. Предложенная итеративная методика позволяет значительно улучшить точность оценочных моделей, в некоторых случаях превосходя показатели более крупных моделей, включая Llama-3.2-90B и GPT-4o, без использования ручной разметки. Не откроет ли это путь к созданию самообучающихся систем оценки, способных адаптироваться к постоянно совершенствующимся возможностям VLM?
Понимание Системы: Вызовы Оценки Визуально-Языковых Моделей
По мере развития возможностей моделей, объединяющих зрение и язык, оценка их качества становится всё более сложной задачей. Изначально достаточно было простых метрик, но текущие модели способны генерировать ответы, требующие глубокого понимания контекста и нюансов изображения. Это приводит к тому, что стандартные методы оценки часто оказываются нечувствительными к реальным улучшениям в производительности, а также не способны уловить тонкие различия между различными моделями. Появляется потребность в более сложных и многогранных подходах, способных адекватно отразить истинный уровень развития этих интеллектуальных систем, что представляет собой значительный вызов для исследователей в области искусственного интеллекта.
Традиционные методы оценки возможностей моделей, объединяющих зрение и язык, зачастую опираются на ручную аннотацию данных, что сопряжено со значительными трудностями. Процесс привлечения экспертов для оценки качества ответов моделей требует существенных финансовых вложений и времени, необходимого для обработки больших объемов информации. Кроме того, субъективное восприятие экспертов неизбежно вносит погрешности, влияющие на объективность и воспроизводимость результатов. Различные эксперты могут по-разному интерпретировать один и тот же ответ, что приводит к расхождениям в оценках и затрудняет сравнение различных моделей. Эта проблема особенно актуальна при оценке креативных или открытых вопросов, где не существует однозначно правильного ответа. Таким образом, зависимость от ручной аннотации становится серьезным препятствием для быстрого и эффективного развития мультимодального искусственного интеллекта.
Развитие мультимодального искусственного интеллекта, объединяющего зрение и язык, требует надежных и автоматизированных методов оценки качества моделей. Отсутствие таких инструментов существенно замедляет прогресс в данной области, поскольку ручная аннотация, традиционно используемая для проверки, является дорогостоящей, трудоемкой и подвержена субъективным оценкам. Автоматизированная оценка позволит исследователям быстро и эффективно тестировать новые архитектуры и алгоритмы, выявлять слабые места моделей и направлять усилия на их улучшение. Подобный подход не только ускорит развитие более мощных и надежных систем, но и сделает процесс разработки более воспроизводимым и объективным, что крайне важно для научного прогресса и практического применения технологий компьютерного зрения и обработки естественного языка.
Генерация Качественных Данных для Обучения Судей VLM
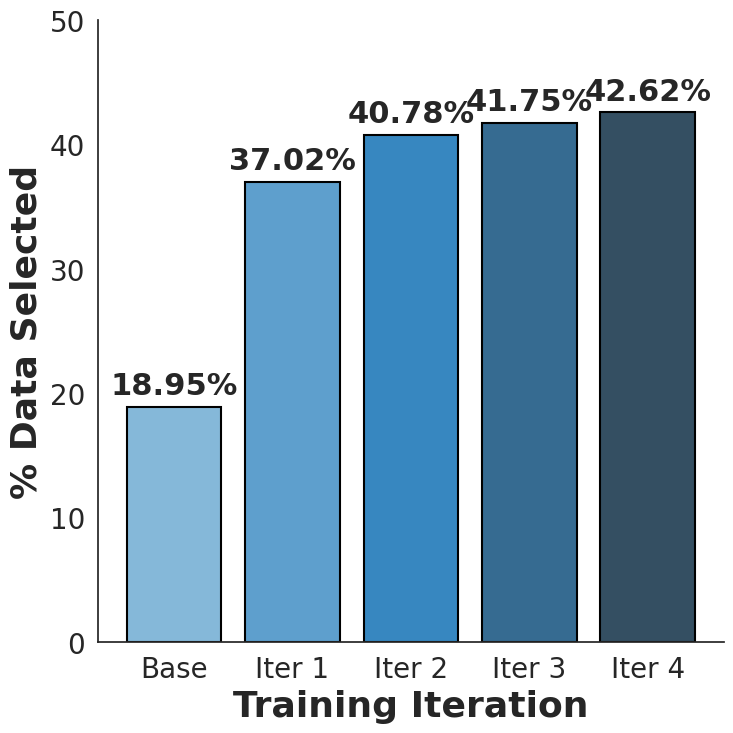
Для эффективной подготовки данных для обучения судей VLM необходимо генерировать пары предпочтений — примеры, в которых один ответ явно превосходит другой. Создание таких пар является ключевым этапом, поскольку позволяет модели научиться различать качественные и некачественные ответы. В процессе генерации пар предпочтений один ответ обозначается как предпочтительный, а другой — как менее предпочтительный, что позволяет модели оценить относительную ценность различных ответов на один и тот же запрос. Качество этих пар предпочтений напрямую влияет на эффективность обучения судей VLM и их способность точно оценивать ответы модели.
Для автоматической генерации пар предпочтений, используемых в обучении судей VLMs, применяется комбинация эвристических методов. Метод большинства голосов (majority voting) позволяет определить наиболее предпочтительный ответ на основе сравнения результатов, полученных от нескольких моделей или экспертов. Контролируемая инъекция ошибок (controlled error injection) заключается в намеренном внесении незначительных неточностей в ответы, чтобы оценить способность модели к выявлению и исправлению ошибок, а также усилить устойчивость к некачественным данным. Оба метода позволяют создать объемный и разнообразный набор данных для обучения, снижая необходимость ручной аннотации и повышая эффективность процесса.
Процесс синтетической генерации пар предпочтений основывается на использовании синтетических данных, что позволяет контролировать качество обучающей выборки для судей VLM. Для обеспечения высокой фактической точности ($Factual\,Accuracy$) генерируемые данные создаются на основе заранее определенных критериев и проверок. Это включает в себя автоматическую генерацию вопросов и ответов, а также последующую оценку ответов на предмет соответствия известным фактам и достоверным источникам. Использование синтетических данных позволяет масштабировать процесс создания обучающей выборки и снизить зависимость от ручной аннотации, сохраняя при этом контроль над качеством и точностью данных.
Процесс генерации обучающих данных для оценки моделей VLM (Visual Language Models) существенно зависит от анализа их внутренних механизмов рассуждений, которые проявляются в виде “цепочек рассуждений” (Reasoning Traces). Эти цепочки представляют собой последовательность промежуточных шагов, которые модель использует для формирования ответа. Анализ этих шагов позволяет выявить логические ошибки, неточности в использовании знаний и другие аспекты, влияющие на качество ответа. Использование Reasoning Traces позволяет генерировать обучающие данные, которые целенаправленно отрабатывают слабые места модели, улучшая её способность к логическому мышлению и обеспечению более точных и обоснованных ответов. Это особенно важно для случаев, когда требуется не просто получить правильный ответ, а понять, как модель пришла к этому ответу.
Итеративное Самосовершенствование через Обучение Судей
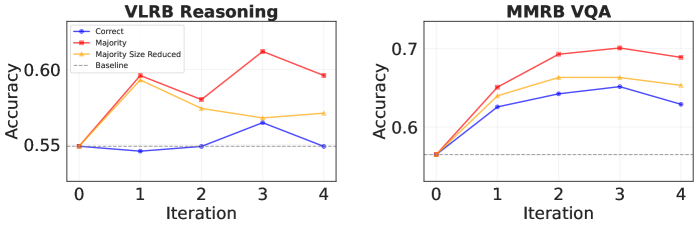
В основе нашей системы оценки визуальных моделей (VLM) лежит парадигма итеративного самосовершенствования. Это означает, что модель-судья, отвечающая за оценку качества ответов VLM, последовательно улучшается с использованием данных, которые она же и помогает создать. В процессе итерации модель-судья оценивает пары предпочтений, сгенерированные самой VLM, и использует только те оценки, которые соответствуют этим предпочтениям. Такой подход обеспечивает самосогласованный сигнал для обучения и позволяет модели-судье непрерывно повышать свою точность и надежность в процессе оценки других моделей.
Процесс итеративной генерации данных для обучения судьи заключается в оценке сгенерированных пар предпочтений текущей моделью-судьей. Каждая пара предпочтений, состоящая из двух вариантов ответа и указания на более предпочтительный, анализируется моделью. Результат этой оценки используется для фильтрации данных, при этом сохраняются только те пары, которые согласуются с предсказаниями текущей модели-судьи. Это обеспечивает самосогласованность обучающего сигнала и позволяет формировать набор данных, соответствующий текущим критериям оценки.
В процессе обучения модели-судьи используются только те оценки синтетических пар предпочтений, которые соответствуют заданным предпочтениям. Это обеспечивает получение самосогласованного сигнала для обучения, исключая противоречивые данные и усиливая стабильность и эффективность процесса тонкой настройки. Отфильтровка данных по критерию соответствия предпочтениям позволяет модели фокусироваться на наиболее релевантных примерах и повышает ее способность к последовательной и предсказуемой оценке.
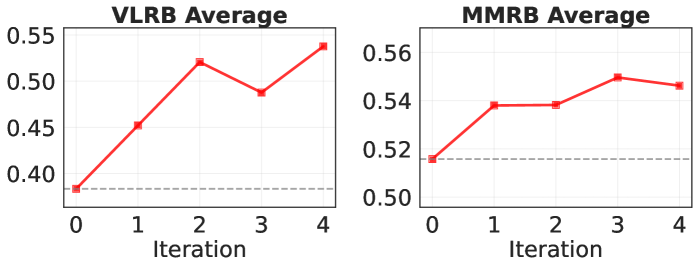
Модель-судья, основанная на архитектуре $Llama-3.2-11B$, подвергается тонкой настройке с использованием отфильтрованных данных, полученных в процессе итеративного улучшения. В результате этого обучения, реализованного в конвейере $Judge Model Training$, достигнуто относительное улучшение общей точности на $40.5\%$ на бенчмарке VL-RewardBench. Это выражается в увеличении показателя с $0.383$ до $0.538$. Данный процесс позволяет повысить качество оценок модели, используемой для ранжирования ответов визуальных языковых моделей.
Валидация Производительности Судьи и Широкие Возможности
Обученная модель, предназначенная для оценки качества работы других визуально-языковых моделей (VLM), продемонстрировала высокую эффективность на общепринятых тестовых наборах данных, таких как `VL-RewardBench` и `Multimodal RewardBench`. Достигнутая точность составила 0.538 на `VL-RewardBench` и 0.539 на `Multimodal RewardBench`, что подтверждает способность системы генерировать надежные и автоматизированные оценки. Такие результаты позволяют говорить о значительном прогрессе в области автоматизированной оценки качества мультимодальных систем и открывают новые возможности для ускорения исследований и разработок в данной сфере.
Полученные результаты подтверждают эффективность предложенного подхода к автоматизированной оценке визуальных языковых моделей (VLM). Разработанная система демонстрирует значительное улучшение качества оценок, обеспечивая относительный прирост в 7.5% на тестовом наборе Multimodal RewardBench по сравнению с базовыми показателями. Это свидетельствует о том, что автоматизированная система способна надежно и последовательно оценивать качество ответов VLM, открывая возможности для более быстрого и эффективного развития в области мультимодального искусственного интеллекта. Данный подход позволяет существенно сократить время и ресурсы, затрачиваемые на ручную оценку, и обеспечивает масштабируемый инструмент для постоянного мониторинга и улучшения производительности моделей.
Разработанная автоматизированная система оценки предоставляет возможность значительно ускорить прогресс в области мультимодального искусственного интеллекта. Благодаря своей масштабируемости, она позволяет исследователям и разработчикам быстро и эффективно оценивать производительность различных моделей, не ограничиваясь трудоемкими и дорогостоящими ручными оценками. Надёжность системы гарантирует воспроизводимость результатов и объективную оценку, что особенно важно для сравнения различных подходов и выявления наиболее перспективных направлений развития. Возможность автоматического анализа большого количества данных открывает новые горизонты для тестирования и оптимизации мультимодальных моделей, способствуя более быстрому внедрению инноваций в этой быстро развивающейся области.
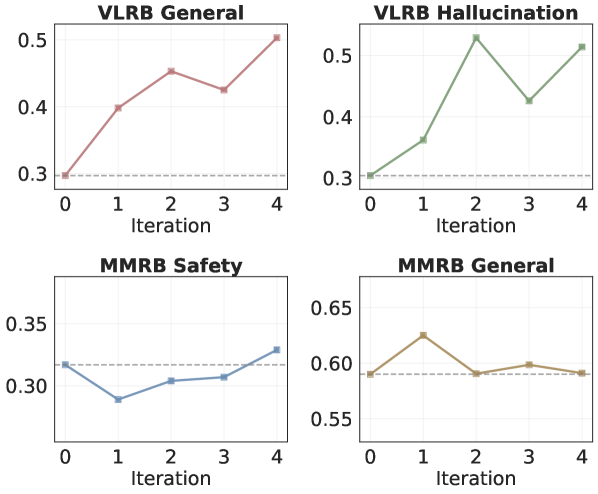
Разработанная система оценки продемонстрировала превосходство над крупными языковыми моделями, такими как Llama-3.2-90B и Claude-3.5-Sonnet, в задаче следования общим инструкциям на бенчмарке VLRB, достигнув точности в 0.503. При этом, результаты в области выявления галлюцинаций оказались сопоставимы с показателями более крупных и сложных моделей, достигнув точности 0.514. Данные результаты свидетельствуют о высокой эффективности предложенного подхода в автоматической оценке визуально-языковых моделей и открывают возможности для создания более надежных и точных систем искусственного интеллекта, способных понимать и следовать инструкциям, избегая при этом генерации недостоверной информации.
Исследование демонстрирует, что развитие систем оценки, основанных на визуальных моделях, возможно без постоянного участия человека. Подобный подход к самосовершенствованию, где модель учится на синтетически сгенерированных данных, напоминает принципы эволюции в биологических системах — адаптация и отбор наиболее эффективных решений. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен расширять возможности человека, а не заменять его». Этот принцип находит отражение в предложенной архитектуре, где автоматизация процесса оценки позволяет значительно снизить затраты и повысить масштабируемость систем, оценивающих соответствие визуального контента текстовым описаниям. Ключевым аспектом является итеративное обучение, которое позволяет модели постоянно улучшать свои навыки, подобно тому, как физические системы стремятся к состоянию равновесия.
Что дальше?
Представленная работа, подобно тщательно настроенному микроскопу, позволяет рассмотреть мир многомерных оценок, избегая дорогостоящей и субъективной ручной разметки. Однако, даже самый совершенный инструмент не открывает всей истины сразу. Самообучающаяся модель-судья, хоть и демонстрирует впечатляющие результаты, все еще ограничена качеством синтетических данных, используемых для её тренировки. Вопрос о том, насколько точно искусственно сгенерированные предпочтения отражают реальное восприятие, остаётся открытым — это эхо в цифровом пространстве, но не сама реальность.
Будущие исследования должны быть направлены на преодоление этой искусственности. Возможно, ключ кроется в гибридных подходах, объединяющих синтетические данные с небольшим объемом экспертных оценок, служащих «якорем» для модели. Не менее важным представляется изучение устойчивости системы к «шуму» и предвзятостям, неизбежно возникающим при генерации данных. Иначе, мы рискуем создать самоподдерживающуюся систему, усиливающую собственные ошибки.
В конечном итоге, задача состоит не в создании идеального автоматического судьи, а в расширении границ понимания — в создании инструментов, позволяющих увидеть закономерности там, где раньше была лишь хаотичная масса информации. Эта работа — лишь первый шаг на пути к этой цели, и дальнейшие исследования, несомненно, откроют новые горизонты в области мультимодальной оценки.
Оригинал статьи: https://arxiv.org/pdf/2512.05145.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Диагностика заболеваний печени: новый подход с использованием искусственного интеллекта
- Квантовые точки и литий танталат: новый путь к фотонным микросхемам
- Квантовый скачок или технологический тупик? Анализ новостей о квантовых технологиях
- Шёпот хаоса в унифицированном представлении: Ming-Flash-Omni и алхимия мульмодальности.
- Распознавание антинуклеарных антител: обучение на собственном темпе
- Упорядоченный разум: Как языковые модели учатся справляться с длинными текстами
2025-12-08 06:50