Автор: Денис Аветисян
Исследователи представили инновационную систему модерации, способную эффективно блокировать нежелательный контент, генерируемый большими языковыми моделями.
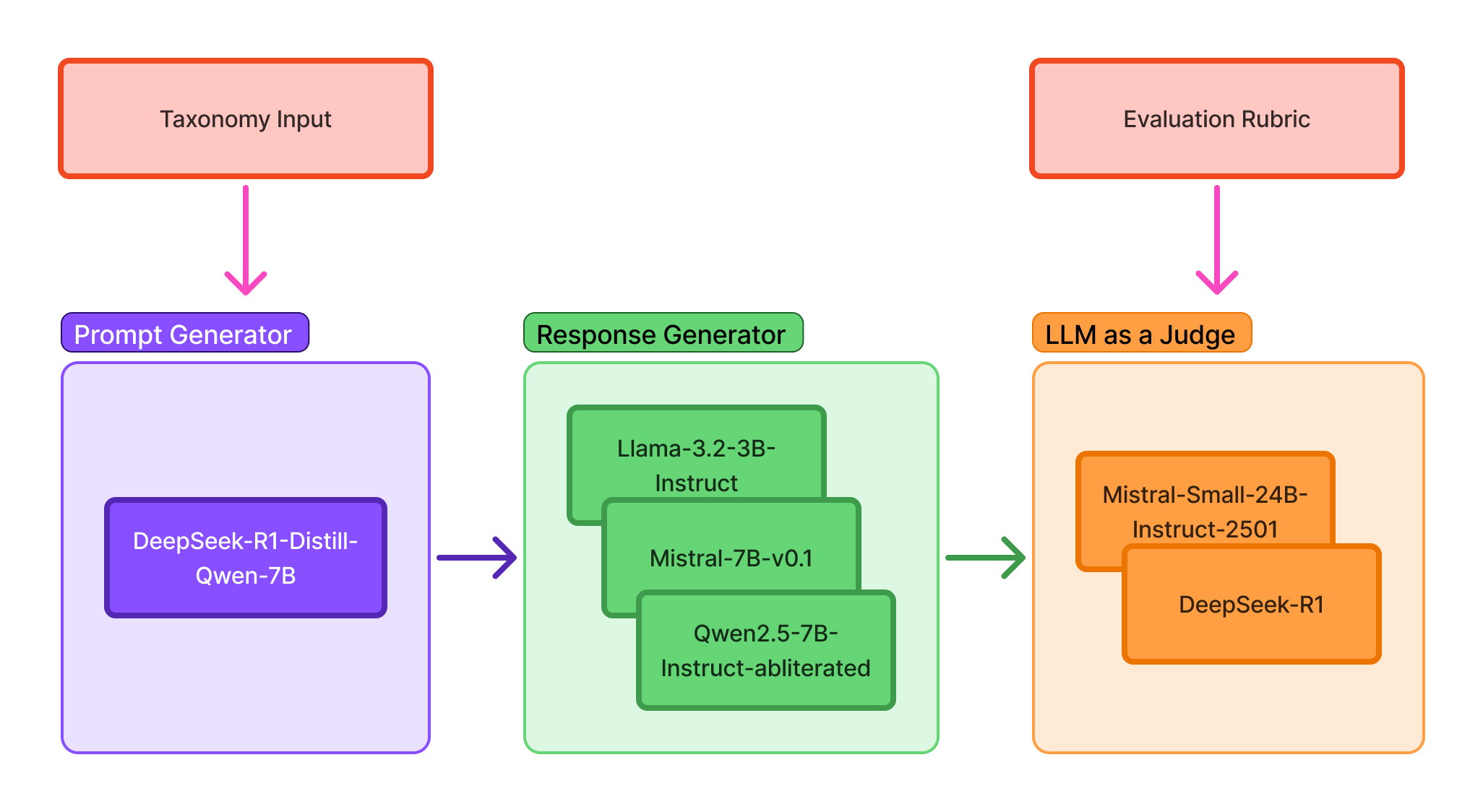
В статье представлена модель Roblox Guard 1.0, использующая синтетические данные, логическое рассуждение и новый набор оценочных данных RobloxGuard-Eval для повышения безопасности и обобщающей способности.
Несмотря на значительный прогресс в обучении больших языковых моделей (LLM), обеспечение их безопасности и предотвращение генерации нежелательного контента остается сложной задачей. В данной работе, посвященной разработке ‘Taxonomy-Adaptive Moderation Model with Robust Guardrails for Large Language Models’, представлена система Roblox Guard 1.0 — LLM, предназначенная для всесторонней модерации входных и выходных данных. Модель демонстрирует высокую производительность и обобщающую способность благодаря использованию синтетических данных, логических цепочек рассуждений (chain-of-thought) и нового эталонного набора данных RobloxGuard-Eval. Сможет ли подобный подход стать основой для создания надежных систем защиты и модерации контента в широком спектре LLM-приложений?
Ограничения Фиксированной Безопасности: Растущая Уязвимость
Современные большие языковые модели демонстрируют впечатляющие возможности в обработке и генерации текста, однако их способность создавать небезопасный контент представляет растущую угрозу в различных приложениях. Несмотря на кажущуюся интеллектуальность, эти модели не обладают встроенным пониманием этических норм или контекстуальной уместности, что делает их уязвимыми для генерации предвзятых, оскорбительных или даже вредоносных высказываний. Риск заключается не только в прямом распространении опасной информации, но и в возможности использования этих моделей для автоматизированного создания дезинформации или манипулирования общественным мнением. Поскольку применение LLM расширяется, от чат-ботов и виртуальных ассистентов до автоматизированного контент-маркетинга и научных исследований, важно осознавать эти потенциальные опасности и разрабатывать эффективные стратегии для смягчения рисков.
Традиционные системы защиты, основанные на фиксированной таксономии нарушений, демонстрируют ограниченную эффективность в условиях постоянно меняющихся угроз. Эти системы, как правило, опираются на заранее определенный набор правил и категорий, что делает их неспособными адекватно реагировать на новые или сложные случаи небезопасного контента. В результате, возникают уязвимости, когда языковые модели генерируют ответы, которые, хотя и не подпадают под известные категории нарушений, все же могут быть вредными, оскорбительными или вводящими в заблуждение. Такая негибкость особенно заметна при обработке неоднозначных запросов или при столкновении с новыми формами злоупотреблений, требуя разработки более адаптивных и динамичных механизмов обеспечения безопасности.
Жесткость традиционных систем безопасности, основанных на фиксированной таксономии, становится все более ощутимой проблемой по мере того, как большие языковые модели сталкиваются с разнообразными и непредсказуемыми пользовательскими запросами. Вместо того чтобы адаптироваться к новым, ранее не встречавшимся формам небезопасного контента или нюансам в существующих нарушениях, эти системы часто не способны распознать и нейтрализовать возникающие риски. Пользовательские запросы, отличающиеся креативностью, обходными путями или использованием сленга, легко обходят статические фильтры, что подчеркивает необходимость разработки динамических механизмов защиты, способных к самообучению и адаптации к постоянно меняющемуся ландшафту угроз. Такие системы должны не просто блокировать известные шаблоны, но и оценивать контекст и намерения, стоящие за запросом, чтобы эффективно предотвращать генерацию вредоносного или опасного контента.
Контекстуализация Безопасности: Адаптивные Защитные Ограждения
Адаптивные модели защитных ограждений (Guardrail Models) представляют собой решение проблемы применения универсальных политик безопасности, которые часто оказываются неэффективными в различных контекстах. В отличие от фиксированных таксономий, эти модели способны динамически определять и применять специфические для конкретной ситуации правила безопасности непосредственно во время работы (inference time). Это достигается за счет анализа входных данных и определения релевантного контекста, позволяя избежать ложных срабатываний и повысить точность фильтрации нежелательного контента, адаптируясь к изменяющимся условиям и требованиям безопасности.
Модели, использующие контекстные факторы, адаптируют политику безопасности в процессе инференса, учитывая такие параметры, как демографические данные пользователя или область применения приложения. Это позволяет снизить количество ложных срабатываний за счет дифференцированного подхода к оценке контента. Например, контент, допустимый в игровом окружении для взрослой аудитории, может быть заблокирован для несовершеннолетних пользователей. Применение контекстных факторов позволяет создавать более точные и гибкие системы модерации, реагирующие на специфику конкретной ситуации и пользователя, что повышает эффективность фильтрации вредоносного контента и улучшает пользовательский опыт.
Roblox Guard 1.0 представляет собой систему, демонстрирующую передовые результаты в смягчении вредоносного контента на платформе Roblox. Данная система использует адаптивные механизмы безопасности, позволяющие ей учитывать контекст взаимодействия и снижать количество ложных срабатываний. В ходе тестирования Roblox Guard 1.0 показал значительное улучшение показателей фильтрации нежелательного контента по сравнению с предыдущими решениями, обеспечивая более безопасную среду для пользователей платформы. Внедрение данной системы является ключевым элементом стратегии Roblox по поддержанию безопасности и соблюдению правил сообщества.
Укрепление Защиты: Синтетические Данные и Дообучение
Генерация синтетических данных играет ключевую роль в обучении эффективных моделей защиты (guardrail). В отличие от сбора и разметки реальных данных, синтетические данные обеспечивают масштабируемый и контролируемый источник разнообразных примеров, необходимых для обучения модели распознаванию и предотвращению нежелательного поведения. Это позволяет создавать наборы данных, охватывающие широкий спектр потенциальных запросов и сценариев, включая редкие или сложные случаи, которые могут быть недостаточно представлены в реальных данных. Контролируемость процесса генерации также позволяет целенаправленно создавать примеры, акцентирующие внимание модели на конкретных аспектах безопасности, повышая её устойчивость к различным типам атак и манипуляций.
Обогащение тренировочных данных посредством методов, таких как Chain-of-Thought (CoT) рационалы и инверсия входных данных, существенно повышает способность модели к рассуждениям и обобщению. CoT рационалы предоставляют пошаговые объяснения логических цепочек, что позволяет модели не просто выдавать ответ, но и понимать процесс его получения. Инверсия входных данных, в свою очередь, предполагает генерацию примеров, направленных на выявление слабых мест модели и повышение её устойчивости к манипуляциям и нежелательным запросам. Комбинирование этих методов позволяет создать более надежный и эффективный механизм защиты, способный адекватно реагировать на широкий спектр потенциально опасных сценариев.
Roblox Guard 1.0 использует метод Low-Rank Adaptation (LoRA) для эффективной дообувки базовой модели Llama-3.1-8B-Instruct. LoRA позволяет адаптировать большие языковые модели (LLM) к конкретным задачам, таким как обеспечение безопасности, путём обучения небольшого количества дополнительных параметров. Этот подход значительно снижает вычислительные затраты и требования к памяти по сравнению с полной переобучкой модели, что особенно важно при ограниченных ресурсах. В процессе дообувки LoRA замораживает веса предобученной модели и обучает только низкоранговые матрицы, представляющие изменения весов. Это позволяет достичь сравнимой или даже превосходящей производительности с меньшим количеством обучаемых параметров и, следовательно, более быстрой и экономичной дообувкой.
Обучающий набор данных для модели безопасности Roblox Guard 1.0 состоит из 384 000 примеров, что обеспечивает надежную работу в различных категориях безопасности. Этот объем данных позволяет модели эффективно обобщать знания и выявлять потенциально опасный контент. Разнообразие примеров охватывает широкий спектр сценариев, включая темы, связанные с насилием, ненавистью, сексуальным контентом и другими формами неприемлемого поведения, что позволяет модели демонстрировать высокую точность и устойчивость к различным типам вредоносных запросов. Использование большого объема данных является критически важным фактором для обеспечения надежной защиты пользователей платформы.
Для автоматизации процесса разметки данных, используемых в генерации синтетических примеров, применяется методология LLM-as-a-Judge. Данный подход предполагает использование большой языковой модели (LLM) в качестве автоматического оценщика, что позволяет значительно ускорить создание размеченных данных для обучения моделей защиты (guardrail). LLM оценивает сгенерированные примеры и присваивает им соответствующие метки, определяющие степень их соответствия требованиям безопасности. Это устраняет необходимость в ручной разметке, которая является трудоемкой и подвержена ошибкам, и позволяет масштабировать процесс создания обучающих данных для повышения надежности и эффективности моделей безопасности.
Подтверждение Эффективности: Тестовые Наборы и Реальные Результаты
Эффективность Roblox Guard 1.0 была тщательно проверена с использованием обширного набора эталонных данных, включающего Aegis Benchmark, HarmBench Benchmark, WildGuard Benchmark и RobloxGuard-Eval. Данный подход к валидации позволил комплексно оценить способность системы обнаруживать и нейтрализовать различные типы нарушений безопасности. Использование нескольких эталонных наборов гарантирует, что оценка производительности охватывает широкий спектр потенциально вредоносного контента и сценариев, подтверждая надежность и универсальность разработанной системы защиты. Полученные результаты демонстрируют способность Roblox Guard 1.0 эффективно адаптироваться к различным угрозам и обеспечивать безопасную среду для пользователей платформы.
Модель Roblox Guard 1.0 продемонстрировала высокую эффективность в обнаружении и смягчении нарушений безопасности, что подтверждается результатами оценки на различных эталонных наборах данных. В частности, достигнутый F1-Score составил 91.9% на Aegis 1.0 Prompt, 89.5% на WildGuard Prompt, 87.3% на BeaverTails и 79.6% на RobloxGuard-Eval. Данные показатели свидетельствуют о способности модели к точной идентификации вредоносного контента и эффективной защите пользователей, а также о ее надежности и обобщающей способности в различных сценариях использования. Высокий F1-Score указывает на сбалансированность между точностью и полнотой обнаружения, что является критически важным для обеспечения безопасности в онлайн-среде.
Комплекс тестов, включающий в себя такие наборы данных, как Aegis Benchmark, HarmBench Benchmark, WildGuard Benchmark и RobloxGuard-Eval, позволяет оценить способность модели выявлять и нейтрализовать широкий спектр нарушений правил безопасности. Данные тесты охватывают различные типы потенциально опасного контента и сценарии его появления, что позволяет продемонстрировать не только высокую точность обнаружения, но и устойчивость системы к различным манипуляциям и попыткам обхода защиты. Достигнутые результаты свидетельствуют о способности модели эффективно адаптироваться к новым угрозам и обеспечивать надежную защиту пользователей на платформе Roblox, подтверждая ее универсальность и применимость в реальных условиях.
Внедрение системы в реальную среду платформы Roblox предоставило ценные данные об ее эффективности в защите пользователей от вредоносного контента в масштабе миллионов взаимодействий. Анализ данных, полученных в процессе эксплуатации, позволил оценить способность системы выявлять и блокировать широкий спектр нарушений, включая неприемлемый язык, потенциально опасные ситуации и нежелательный контент, создаваемый пользователями. Эти результаты подтверждают, что система не только демонстрирует высокую производительность в лабораторных условиях, но и способна эффективно функционировать в динамичной и сложной среде онлайн-платформы, обеспечивая безопасность и комфорт для сообщества Roblox.
Исследование демонстрирует стремление к созданию не просто эффективной, но и адаптируемой системы модерации. Авторы, подобно скульптору, отсекают избыточное, фокусируясь на ключевых принципах безопасности больших языковых моделей. Как однажды заметил Пол Эрдёш: «Математика — это искусство находить закономерности в хаосе». Подобно этому, предложенная модель RobloxGuard 1.0 выявляет и устраняет потенциально опасный контент, используя синтетические данные и логические цепочки рассуждений. Цель — не просто достичь высокой производительности, но и обеспечить надежную защиту от нежелательных материалов, создавая систему, в которой остаётся лишь самое необходимое — безопасность и ясность.
Куда Далее?
Представленная работа, стремясь к утолению жажды безопасности больших языковых моделей, не решает, а лишь обнажает глубину проблемы. Создание синтетических данных, хоть и эффективное, по сути, является эхом существующей предвзятости, лишь замаскированным под новым обликом. Иллюзия контроля над языком возникает из-за веры в возможность полной классификации и нейтрализации всех потенциальных угроз. Однако, язык, по своей природе, текуч и непредсказуем, и попытки его обуздания всегда будут лишь временными мерами.
Настоящая работа, возможно, заключается не в создании все более сложных систем защиты, а в принятии неизбежной неопределенности. Более плодотворным путем представляется не создание “РобоксГарда 2.0”, а разработка методов, позволяющих моделям самостоятельно оценивать и признавать границы своей компетенции, признавать собственную неспособность к безошибочному суждению.
Необходима смена парадигмы: от стремления к абсолютному контролю — к осознанному принятию риска. Истинная безопасность заключается не в устранении всех потенциальных опасностей, а в способности адаптироваться к их появлению. Простота, а не сложность, станет ключом к будущему.
Оригинал статьи: https://arxiv.org/pdf/2512.05339.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Диагностика заболеваний печени: новый подход с использованием искусственного интеллекта
- Квантовые точки и литий танталат: новый путь к фотонным микросхемам
- Квантовый скачок или технологический тупик? Анализ новостей о квантовых технологиях
- Шёпот хаоса в унифицированном представлении: Ming-Flash-Omni и алхимия мульмодальности.
- Распознавание антинуклеарных антител: обучение на собственном темпе
- Упорядоченный разум: Как языковые модели учатся справляться с длинными текстами
2025-12-08 22:03