Автор: Денис Аветисян
Исследователи представляют масштабный мультимодальный датасет Refer360, призванный улучшить способность роботов понимать человеческие указания в реальном мире.

Представлен датасет Refer360 и модуль MuRes для повышения качества мультимодального представления данных в задачах взаимодействия человека и робота.
Несмотря на прогресс в области робототехники, обеспечение интуитивного взаимодействия человека и робота требует от последних понимания не только речи, но и невербальных сигналов в контексте окружающей среды. В статье «Embodied Referring Expression Comprehension in Human-Robot Interaction» представлена новая масштабная база данных Refer360, охватывающая разнообразные сценарии взаимодействия в помещениях и на открытом воздухе, а также модуль MuRes, улучшающий обработку мультимодальной информации. Эксперименты показали, что предложенный подход позволяет значительно повысить точность понимания роботами указаний, содержащих как вербальные, так и невербальные компоненты. Способны ли подобные решения стать основой для создания действительно адаптивных и полезных роботов-помощников в реальных жизненных условиях?
Основы воплощенного понимания: Связь языка и реальности
Современные системы искусственного интеллекта сталкиваются с существенными трудностями при соотнесении языка с реальным миром, особенно в задачах, требующих воплощенного взаимодействия. Искусственный интеллект зачастую не способен правильно интерпретировать указания и ссылки на объекты в физическом окружении, что критически важно для успешного выполнения задач, связанных с манипулированием предметами или навигацией в пространстве. Например, фраза «Передай мне красный кубик» требует не только лингвистического анализа, но и визуального распознавания и локализации конкретного объекта среди множества других. Отсутствие надежного механизма для «заземления» языка в реальном мире существенно ограничивает возможности искусственного интеллекта в робототехнике и других областях, где необходимо взаимодействие с физическим миром.
Успешное понимание воплощенных референциальных выражений (E-RFE) требует бесшовной интеграции визуальных и лингвистических сигналов. Представьте ситуацию, когда человеку указывают на предмет, используя одновременно слова и жесты — мозг мгновенно сопоставляет эти данные для точной идентификации. Аналогичным образом, для искусственного интеллекта, способного взаимодействовать с физическим миром, крайне важно объединить информацию, полученную от «глаз» (камер, сенсоров) и «ушей» (речевых команд). Эффективное сопоставление визуальных признаков объекта — его формы, цвета, местоположения — с описанием в языке позволяет системе не просто «слышать» команды, но и понимать, к чему они относятся в конкретной обстановке. Без этой интеграции, даже самое точное лингвистическое понимание может оказаться бесполезным, так как система не сможет соотнести слова с реальными объектами в окружающей среде, что существенно ограничивает возможности взаимодействия робота с человеком и миром.
Существующие подходы к пониманию естественного языка роботами часто сталкиваются с трудностями при надежном объединении визуальной и лингвистической информации. Эта проблема особенно остро проявляется при интерпретации указаний, требующих понимания контекста и взаимодействия с физическим миром. Неспособность эффективно интегрировать эти модальности приводит к тому, что роботы испытывают затруднения при выполнении даже простых задач, требующих понимания человеческих указаний, таких как «перенеси это сюда». В результате, взаимодействие человека с роботом становится неестественным и требует от пользователя адаптации к ограничениям системы, а не наоборот. Разработка методов, способных обеспечить робастное слияние визуальных и лингвистических данных, является ключевым шагом на пути к созданию действительно интеллектуальных и отзывчивых роботов, способных к плавному и интуитивно понятному взаимодействию с человеком.
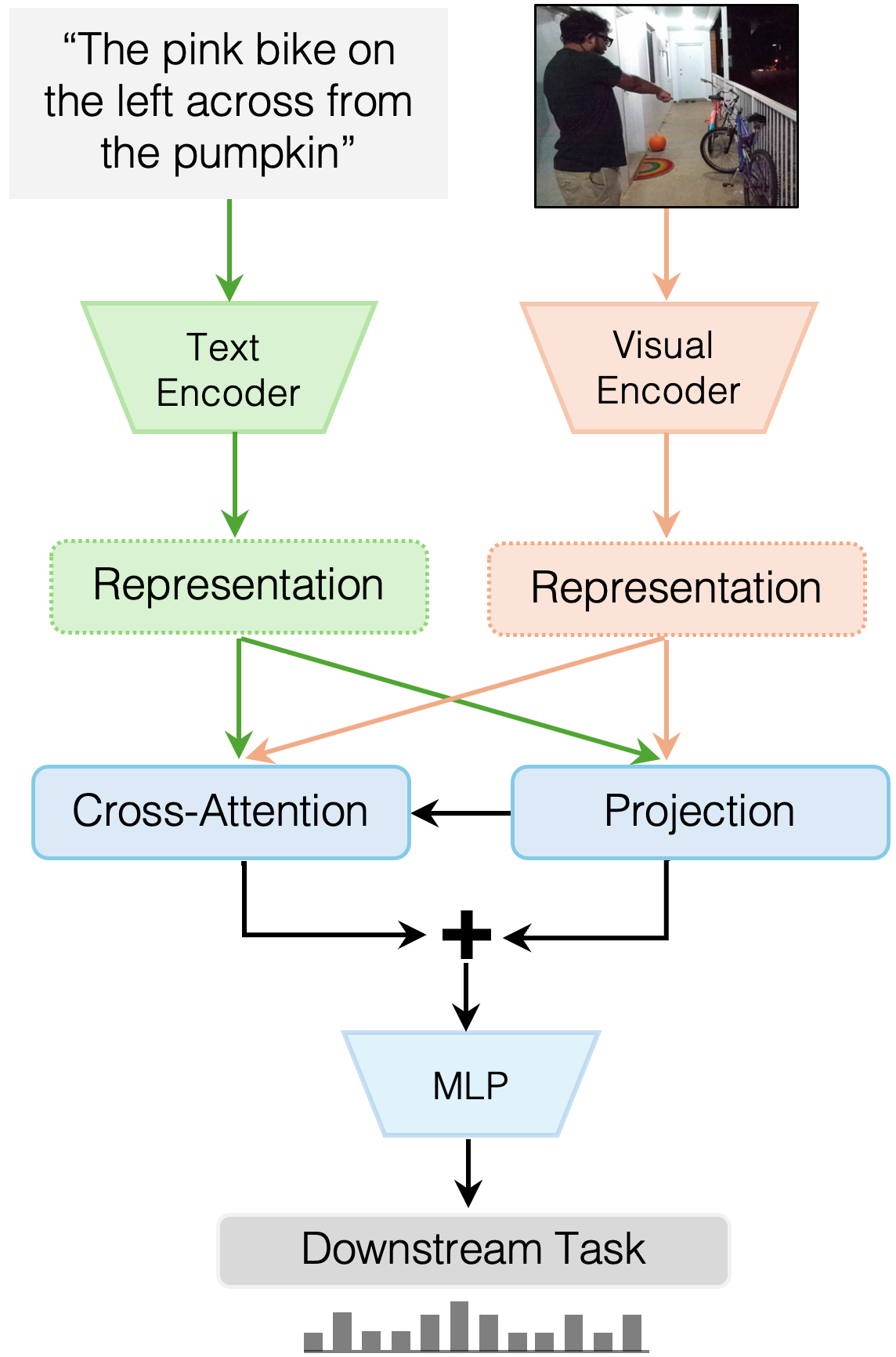
MuRes: Управляемое остаточное соединение для глубокого понимания
Модуль MuRes использует подход с управляемым остаточным соединением, что обеспечивает эффективный поток информации и предотвращает проблему затухания градиентов во время обучения. В традиционных остаточных сетях информация может теряться или искажаться при прохождении через множество слоев. В MuRes остаточные соединения не просто суммируют выходные данные слоев, но и направляют информацию, позволяя градиентам более эффективно распространяться по сети. Это достигается за счет использования управляющих сигналов, которые определяют, какая часть информации должна быть передана через остаточное соединение, и какие изменения должны быть внесены. Такая архитектура позволяет обучать более глубокие сети, сохраняя при этом стабильность обучения и улучшая общую производительность.
В основе модуля MuRes лежит использование механизмов кросс-внимания, обеспечивающих динамическое взаимодействие между визуальными и лингвистическими представлениями. Эти механизмы позволяют модели эффективно сопоставлять и интегрировать информацию из различных модальностей, фокусируясь на наиболее релевантных участках изображения и текста. В процессе работы кросс-внимание вычисляет веса, определяющие степень влияния каждого визуального элемента на лингвистическое представление и наоборот, что позволяет модели устанавливать сложные связи и учитывать контекст при обработке данных. Это приводит к более точному пониманию взаимосвязей между визуальной и текстовой информацией, улучшая общую производительность модели в задачах, требующих мультимодального анализа.
Модуль MuRes использует предварительно обученные модели для обработки визуальной и лингвистической информации, такие как CLIP, BLIP-2, ViLT, VisualBERT и DualEncoder. Интеграция этих моделей позволяет MuRes эффективно использовать накопленные знания и избегать обучения с нуля, что значительно ускоряет процесс обучения и повышает производительность. Выбор данных моделей обусловлен их доказанной эффективностью в задачах обработки изображений и естественного языка, а также их способностью к мультимодальному взаимодействию. Использование существующих архитектур также упрощает процесс развертывания и адаптации MuRes к различным задачам и данным.
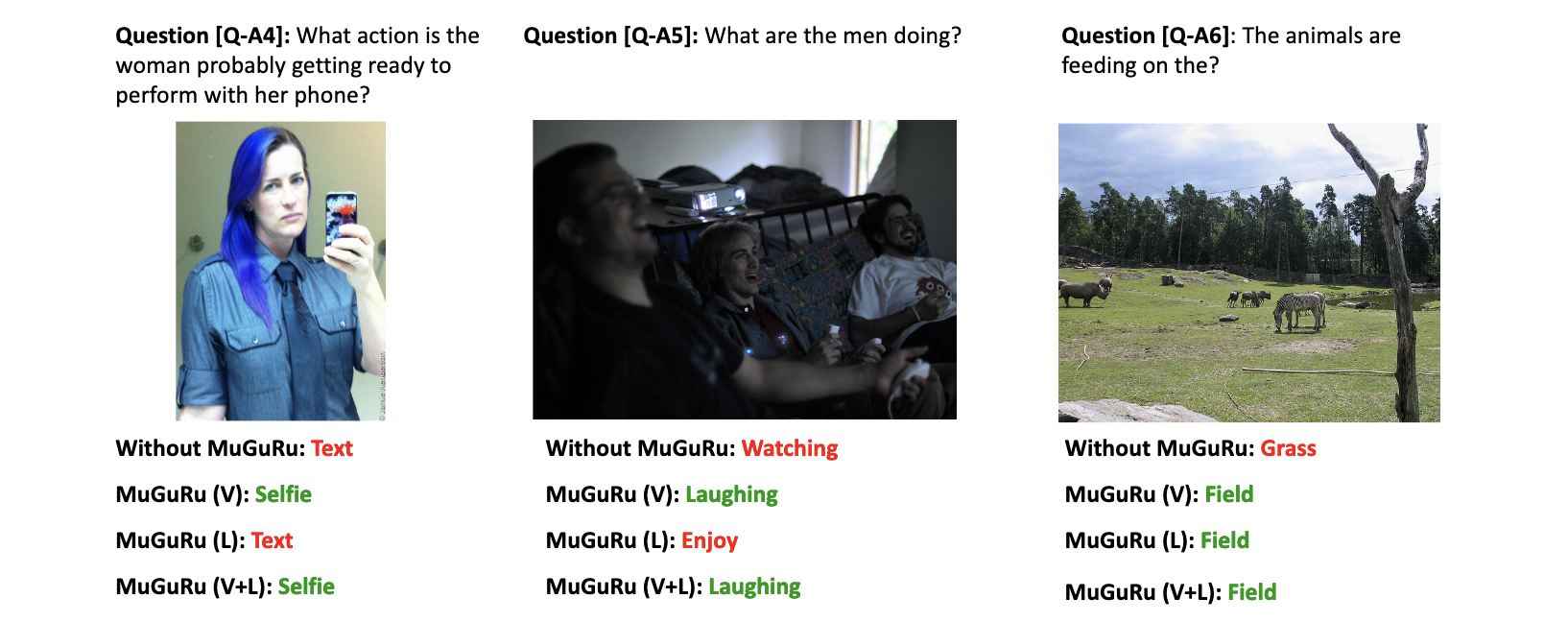
Данные и методология: Закрепление MuRes в реальности
Для обучения и оценки MuRes использовался датасет Refer360, представляющий собой обширный ресурс для изучения воплощенных отсылок. Данный датасет содержит данные, собранные в реальных условиях, и включает в себя аннотации, связывающие вербальные отсылки с объектами в трехмерном окружении. Refer360 обеспечивает разнообразие сценариев и объектов, что позволило MuRes получить широкий спектр данных для обучения и продемонстрировать способность к обобщению в различных ситуациях. Объем датасета и качество аннотаций способствовали достижению высокой точности MuRes при интерпретации отсылок в эгоцентричных визуальных средах.
Сбор данных осуществлялся с использованием специализированных сенсорных систем. Для получения данных о глубине и цветового изображения использовался датчик ‘Azure Kinect DK’, обеспечивающий высококачественную 3D-реконструкцию окружения. Одновременно, для отслеживания направления взгляда участников исследования применялись очки ‘Pupil Smart Glass’, фиксирующие данные о движении глаз и позволяющие определить, на какие объекты в поле зрения направлено внимание. Комбинация этих двух типов сенсоров позволила получить комплексные данные, необходимые для обучения и оценки модели MuRes.
Оценка производительности MuRes проводилась на основе точности интерпретации указаний в захваченных эгоцентричных визуальных средах. Для количественной оценки использовались метрики, измеряющие степень соответствия между предсказанными MuRes объектами-референтами и фактическими объектами, на которые указывал пользователь в видеозаписи. Высокая точность интерпретации указывала на способность модели эффективно связывать лингвистические указания с соответствующими визуальными элементами в реальном окружении, что подтверждалось статистическим анализом результатов. Важно отметить, что оценка проводилась на разнообразном наборе сцен и типов референтов, что позволило оценить обобщающую способность MuRes.

Результаты и последствия: На пути к более интуитивному ИИ
Разработка MuRes продемонстрировала значительное превосходство над существующими моделями в задаче интерпретации воплощенных отсылок. В ходе тестирования на наборе данных Refer360, MuRes достиг показателя IOU-25 в 29.20%, что на 3.4% превышает результаты, достигнутые ранее доступными методами. Этот прирост производительности указывает на улучшенную способность системы понимать и соотносить языковые команды с конкретными объектами и локациями в физическом пространстве, открывая новые возможности для более естественного и интуитивно понятного взаимодействия человека с искусственным интеллектом.
В ходе тестирования на наборе данных CAESAR-PRO модель MuRes продемонстрировала значительное улучшение в интерпретации визуальных подсказок. Достигнутый показатель IOU-25 составил 42.91%, что на 5% превосходит результаты, полученные при использовании CLIP. Этот прирост производительности указывает на повышенную способность MuRes к точному сопоставлению текстовых инструкций с соответствующими визуальными элементами в сложных сценах, что является ключевым шагом к созданию более интуитивно понятных систем искусственного интеллекта и расширению возможностей взаимодействия человека с машиной.
Исследование продемонстрировало, что модель MuRes, использующая архитектуру VisualBERT, достигла точности в 51.85% при решении задач из набора данных ScienceQA. Этот результат свидетельствует о значительном прогрессе в области развития способностей к рассуждению у искусственного интеллекта. В отличие от простых алгоритмов сопоставления шаблонов, MuRes способна анализировать сложные вопросы, требующие понимания научных концепций и логических связей, что позволяет ей успешно отвечать на вопросы, требующие не просто извлечения информации, а её синтеза и применения. Данное достижение открывает новые перспективы для создания интеллектуальных систем, способных к более глубокому и осмысленному взаимодействию с человеком в различных областях, включая образование и научные исследования.
Данное достижение открывает широкие перспективы для развития систем, взаимодействующих с человеком в естественной манере, в частности, в сфере помощи и совместной работы. Разработка более интуитивных интерфейсов «человек-робот» позволит создавать ассистивные устройства, способные понимать и выполнять сложные команды, адаптируясь к потребностям пользователя. Более того, улучшенное понимание контекста и намерений человека способствует созданию эффективных коллаборативных сред, где роботы могут выступать в роли полноценных партнеров, повышая производительность и безопасность в различных отраслях, от промышленности до здравоохранения. Перспективы включают в себя разработку роботов-помощников для людей с ограниченными возможностями, а также создание интеллектуальных систем для совместной работы в производственных цехах и исследовательских лабораториях.

Представленная работа демонстрирует стремление к созданию систем, способных к осмысленному взаимодействию с окружающим миром. Разработка датасета Refer360 и модуля MuRes направлена на улучшение обучения мультимодальных представлений, что особенно важно для задач взаимодействия человека и робота. Этот подход перекликается с принципами математической строгости, ведь корректность восприятия и интерпретации информации роботом должна быть доказуема, а не полагаться на статистическую вероятность. Как некогда заметил Г.Х. Харди: «Математика — это наука о том, что можно доказать, а не о том, что можно вычислить». Следовательно, создание надежных алгоритмов для embodied AI требует не только способности робота ‘видеть’ и ‘слышать’, но и строгого математического обоснования его действий.
Что Дальше?
Представленный набор данных Refer360, несомненно, является шагом вперед в области воплощенного искусственного интеллекта. Однако, необходимо признать, что само по себе увеличение объема данных не гарантирует фундаментального прорыва. Проблема понимания отсылок, даже в контролируемой среде, остается сложной задачей, требующей не просто распознавания модальностей, а истинного понимания намерений говорящего. Модуль MuRes, безусловно, демонстрирует улучшения, но его эффективность в условиях реального мира, с шумом и неполнотой данных, остается вопросом дальнейших исследований.
Критически важным представляется переход от обучения на размеченных данных к самообучению и обучению с подкреплением. Робот, взаимодействующий с миром, должен не просто «узнавать» объекты, но и активно исследовать их свойства, задавать вопросы и проверять гипотезы. Иначе, мы рискуем создать системы, которые кажутся умными лишь на поверхности, не обладая истинной способностью к обобщению и адаптации.
В конечном счете, истинный прогресс в области воплощенного искусственного интеллекта требует не только разработки более сложных алгоритмов, но и переосмысления самой концепции «интеллекта». Недостаточно просто «научить» машину выполнять задачи; необходимо создать системы, способные к самостоятельному обучению, творчеству и решению проблем в условиях неопределенности. Иначе, все наши усилия будут лишь демонстрацией математической элегантности, лишенной практической ценности.
Оригинал статьи: https://arxiv.org/pdf/2512.06558.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- От миллиметровых волн к кубитному управлению: единый подход
- Квантовые схемы: универсальность и сложность
- Автоматический анализ алгоритмов: новый подход к оптимизации
- Визуальная навигация по множеству изображений: новый подход с использованием больших языковых моделей
- Автоматизация интеллекта: как оптимизировать сложные задачи
- Квантовые точки и литий танталат: новый путь к фотонным микросхемам
2025-12-09 11:31