Автор: Денис Аветисян
Представлен комплексный набор тестов, позволяющий объективно оценить, насколько достоверную информацию генерируют современные языковые модели.
Комплексная оценочная платформа FACTS Leaderboard тестирует фактуальность больших языковых моделей в различных сценариях, включая мультимодальный анализ, поиск информации и обоснование ответов.
Несмотря на впечатляющий прогресс в области больших языковых моделей, оценка их способности генерировать фактологически точный текст остается сложной задачей. В данной работе представлена платформа ‘The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality’ — комплексный набор бенчмарков, предназначенный для всесторонней оценки фактологичности языковых моделей в различных сценариях, включая мультимодальные рассуждения, использование параметрических знаний, поиск информации и проверку обоснованности ответов. Платформа агрегирует результаты по четырем под-бенчмаркам, обеспечивая сбалансированную и надежную оценку общей фактологичности модели. Сможет ли данная платформа стать стандартом де-факто для оценки надежности и достоверности генерируемого текста большими языковыми моделями?
Неизбежность Старения: Проблемы Фактической Точности в LLM
Несмотря на впечатляющие возможности в генерации текста и понимании языка, большие языковые модели (LLM) последовательно демонстрируют проблемы с фактической точностью. Это несоответствие между кажущейся компетентностью и реальной надежностью информации, которую они предоставляют, вызывает серьезные опасения. Модели способны создавать связные и грамматически правильные тексты, однако часто включают в них неверные факты, вымышленные события или устаревшие данные. Данное ограничение существенно снижает доверие к LLM, особенно в контексте приложений, требующих высокой степени достоверности, таких как научные исследования, журналистика или предоставление юридических консультаций. Таким образом, обеспечение фактической точности является ключевой задачей для дальнейшего развития и широкого внедрения больших языковых моделей.
Ограничение возможностей больших языковых моделей в отношении фактической точности не связано исключительно с их размером или объемом данных, на которых они обучаются. Исследования показывают, что проблема заключается в фундаментальном разрыве между тем, как модели представляют и используют знания. В отличие от человеческого понимания, основанного на причинно-следственных связях и контекстуализации информации, языковые модели оперируют преимущественно статистическими закономерностями в тексте. Это приводит к тому, что модели могут генерировать грамматически корректные и правдоподобные тексты, не имеющие фактической основы или содержащие логические противоречия. Таким образом, ключевая сложность заключается не в увеличении масштаба моделей, а в разработке принципиально новых подходов к представлению знаний, позволяющих им понимать и верифицировать информацию, а не просто воспроизводить статистические связи.
Существующие методы оценки больших языковых моделей зачастую не способны уловить тонкости фактических ошибок, предоставляя неполную картину их производительности. Традиционные метрики, ориентированные на поверхностное совпадение слов или фраз, не учитывают контекстуальные нюансы и могут ошибочно оценивать как верными ответы, содержащие неточности или нелогичные выводы. Более того, оценка часто фокусируется на отдельных утверждениях, игнорируя взаимосвязь между ними и общую когерентность текста. Это приводит к ситуации, когда модель может демонстрировать высокие результаты по формальным показателям, но при этом генерировать информацию, требующую критической проверки и способную вводить в заблуждение. Таким образом, для более объективной и всесторонней оценки необходимо разрабатывать и внедрять более сложные методы, учитывающие семантическое значение, логическую связность и соответствие информации проверенным источникам.
Неспособность больших языковых моделей к обеспечению фактической точности представляет собой серьезное препятствие для их внедрения в критически важные сферы, где достоверность информации имеет первостепенное значение. Приложения, связанные с медициной, юриспруденцией, финансовым анализом и образованием, требуют безошибочной точности, и даже незначительные неточности могут привести к серьезным последствиям. Поэтому, разработка методов повышения фактической достоверности LLM является не просто технической задачей, а необходимостью для обеспечения безопасного и эффективного использования этих мощных инструментов. Преодоление этой проблемы позволит раскрыть весь потенциал больших языковых моделей, обеспечив их надежность и доверие со стороны пользователей и специалистов.
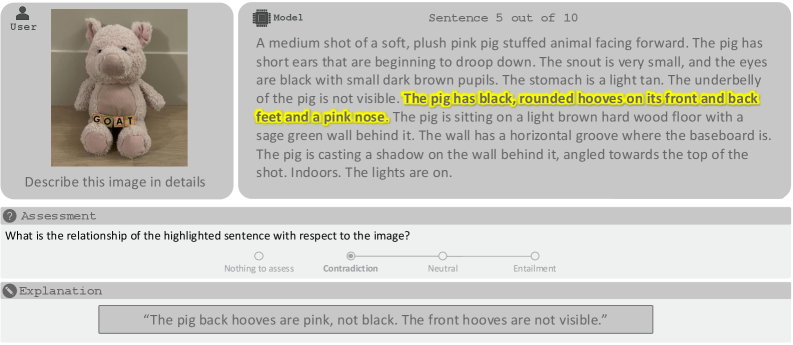
Комплекс FACTS: Холистическая Оценка Надежности
Комплекс FACTS предназначен для оценки фактической достоверности моделей искусственного интеллекта по широкому спектру возможностей. Оценка охватывает как параметрические знания — фактическую информацию, хранящуюся в параметрах модели, — так и интеграцию с поисковыми системами для получения актуальных данных. Кроме того, FACTS проверяет способность моделей сопоставлять информацию из различных модальностей (например, текст и изображения) и обосновывать свои ответы, используя внешние источники. Такой подход позволяет оценить не только знание фактов, но и способность модели эффективно использовать и комбинировать различные типы информации для получения достоверных результатов.
Набор FACTS включает в себя несколько отдельных таблиц лидеров — Parametric, Search, Multimodal и Grounding v2 — каждая из которых предназначена для оценки конкретного аспекта фактологического мышления. Parametric оценивает способность модели оперировать структурированными данными и числовыми значениями. Таблица Search проверяет умение модели использовать внешние поисковые системы для подтверждения фактов. Multimodal оценивает способность модели сопоставлять факты, представленные в различных модальностях, таких как текст и изображения. Grounding v2 фокусируется на способности модели связывать утверждения с конкретными источниками и контекстом, обеспечивая более глубокую проверку фактической обоснованности.
Для обеспечения согласованности и масштабируемости оценки ответов моделей, FACTS использует автоматизированные системы оценки и рубрики. Автоматические судьи, основанные на заранее определенных критериях, позволяют последовательно оценивать большое количество ответов, исключая субъективность, присущую ручной оценке. Рубрики, представляющие собой детализированные наборы критериев оценки, обеспечивают четкое определение ожидаемых характеристик правильных ответов и позволяют стандартизировать процесс оценки по различным метрикам. Этот подход позволяет эффективно оценивать модели на больших объемах данных и воспроизводить результаты, что критически важно для надежной оценки фактической достоверности.
В отличие от традиционных бенчмарков, оценивающих фактическую точность преимущественно по принципу соответствия ответа заданному вопросу, FACTS использует комплексный подход, охватывающий различные аспекты рассуждений, такие как параметрические знания, интеграцию поиска и мультимодальную привязку. Такая многогранность позволяет более детально оценить способность модели к надежному и обоснованному представлению фактов, избегая упрощенных оценок, которые могут быть достигнуты за счет запоминания или поверхностного сопоставления данных. Использование автоматизированных судей и рубрик обеспечивает последовательность и масштабируемость оценки, что повышает надежность получаемых результатов и позволяет более точно выявлять сильные и слабые стороны различных моделей.

Деконструкция Фактологического Мышления с Подтаблицами FACTS
Лидерборд FACTS Parametric оценивает способность модели извлекать и использовать знания, хранящиеся во внутренней памяти, посредством ответов на фактические вопросы. Тестирование строится на проверке точности предоставленных ответов, без использования внешних инструментов поиска или контекстных документов. Фактически, лидерборд проверяет, насколько полно и корректно модель запомнила и структурировала информацию в процессе обучения, и способна ли она воспроизвести её в ответ на конкретный запрос, требующий фактического ответа. Оценка производится на основе точности и полноты ответа на каждый вопрос, позволяя определить сильные и слабые стороны модели в области хранения и извлечения фактов.
Подзачетная таблица FACTS Search оценивает способность модели использовать внешние инструменты поиска — такие как Brave Search API — для извлечения и синтеза релевантной информации. В рамках этого теста модели предоставляется вопрос, после чего они выполняют поиск в интернете с использованием указанного API. Оценивается не только точность найденной информации, но и способность модели правильно интерпретировать результаты поиска и сформулировать ответ, основанный на синтезе полученных данных. Тест позволяет оценить, насколько эффективно модель может дополнять свои внутренние знания внешними источниками информации для решения задач, требующих актуальных или специализированных данных.
Тест FACTS Multimodal оценивает способность модели интегрировать визуальную информацию с общими знаниями о мире, требуя надежной привязки визуальных данных к контексту. Это предполагает, что модель не просто распознает объекты на изображении, но и способна понимать их взаимосвязь с окружающим миром и использовать эти знания для формирования осмысленных ответов. Оценка включает в себя проверку способности модели к визуальному обоснованию, то есть способности подтвердить свои ответы на основе представленной визуальной информации и общих знаний, а также к контекстуальному пониманию, то есть способности учитывать общий контекст изображения и вопроса для формирования релевантного ответа.
FACTS Grounding v2 направлена на оценку способности модели обосновывать свои ответы, опираясь на предоставленный Контекстный Документ. В отличие от предыдущих версий, данная версия использует улучшенные оценочные модели, такие как Gemini, Claude и GPT, для более точной и надежной проверки соответствия ответа контексту. Это позволяет более эффективно оценивать, насколько хорошо модель извлекает и применяет информацию из заданного источника, а также избегает галлюцинаций и нерелевантных ответов. Улучшенные модели-оценщики повышают объективность и воспроизводимость результатов, что критически важно для сравнительной оценки различных языковых моделей.
Количественная Оценка Точности: Метрики и Выводы из FACTS
Для оценки полноты и непротиворечивости ответов языковых моделей разработан инструментарий FACTS, использующий такие метрики, как Score покрытия и Score отсутствия противоречий. Score покрытия определяет, насколько полно ответ охватывает все релевантные аспекты вопроса, а Score отсутствия противоречий — насколько последовательны и логически согласованы различные части ответа. Эти метрики позволяют выйти за рамки простой оценки «правильно/неправильно», предоставляя более детальное представление о качестве генерируемого текста и выявляя слабые места моделей в плане фактической точности и логической связности. Использование данных показателей позволяет не только оценить текущее состояние моделей, но и направлять дальнейшие исследования и разработки в сторону повышения надежности и достоверности генерируемых ответов.
Анализ результатов, полученных в рамках комплекса FACTS, демонстрирует, что средний показатель точности ответов современных языковых моделей составляет 69%. Этот результат, хотя и свидетельствует о заметном прогрессе в области обработки естественного языка, указывает на существенный потенциал для дальнейшего улучшения. Низкий процент ошибок не означает полное отсутствие проблем с фактической достоверностью, а подчеркивает необходимость разработки более надежных методов оценки и повышения способности моделей к генерации информации, соответствующей действительности. Дальнейшие исследования направлены на выявление конкретных областей, где модели демонстрируют наибольшую неточность, и на разработку стратегий для минимизации ошибок и повышения общей достоверности генерируемого контента.
Согласно результатам оценки на базе набора данных FACTS Parametric, модель GPT-o3 продемонстрировала точность в 57.0%, в то время как более новая модель, GPT-5, достигла лишь 55.7%. Примечательно, что GPT-5, в отличие от своего предшественника, значительно чаще прибегала к уклонению от прямых ответов, выражая неуверенность или предоставляя неоднозначные формулировки. Данный факт указывает на то, что увеличение размера модели и сложности архитектуры не всегда приводит к повышению фактической точности, и может даже сопровождаться тенденцией к осторожности, что, в свою очередь, влияет на способность модели давать конкретные и уверенные ответы на поставленные вопросы.
Исследования в рамках FACTS Search показали, что модель Gemini 3 Pro демонстрирует высокую точность ответов, при этом требуя значительно меньше поисковых запросов по сравнению с другими лидирующими моделями. Этот результат указывает на более эффективный алгоритм обработки информации и способность Gemini 3 Pro к более точной фильтрации релевантных данных. В отличие от моделей, которые полагаются на обширный поиск для подтверждения фактов, Gemini 3 Pro способна достичь высокой достоверности, используя меньшее количество источников, что свидетельствует о её способности к более глубокому пониманию и логическому выводу. Данный подход не только повышает эффективность, но и снижает вероятность включения в ответ неточной или противоречивой информации, полученной из избыточного количества источников.
Традиционные методы оценки фактической точности часто ограничиваются простой бинарной классификацией — верно или неверно. Однако, система FACTS предлагает более детальный анализ, используя такие метрики, как охват и отсутствие противоречий. Такой подход позволяет выявить не только грубые ошибки, но и неполноту ответа, а также внутренние несогласованности. Вместо простого определения «правильности», оценивается степень полноты и последовательности информации, предоставляемой моделью. Это особенно важно, поскольку даже корректный ответ может быть недостаточным или упускать важные детали. Более тонкая оценка, предоставляемая FACTS, позволяет разработчикам не только исправлять фактические ошибки, но и улучшать способность моделей предоставлять всесторонние и логически выстроенные ответы, что способствует повышению доверия к искусственному интеллекту.
Представленный FACTS Leaderboard, как комплексная система оценки, стремится зафиксировать истинность ответов больших языковых моделей в различных контекстах. Это напоминает естественные процессы износа и адаптации, ведь любая система, будь то программный код или нейронная сеть, подвержена влиянию времени и требует постоянной проверки на соответствие реальности. Как отмечал Пол Эрдеш: «Математика — это искусство видеть невидимое». В данном случае, FACTS Leaderboard позволяет увидеть «истинность», скрытую в потоке генерируемого текста, и оценить, насколько эффективно модель способна обосновывать свои ответы, используя внешние источники и контекстную информацию. Подобно эрозии, накапливающийся «технический долг» в области знаний модели может привести к искажению фактов, поэтому непрерывный мониторинг и оценка, предлагаемые FACTS Leaderboard, критически важны для поддержания ее надежности и точности.
Что дальше?
Представленная работа, создавая платформу для оценки фактической точности больших языковых моделей, неизбежно обнажает глубину непознанного. Каждая задержка в достижении абсолютной достоверности — это цена углубленного понимания природы знания и его репрезентации в искусственных системах. Фактически, FACTS Leaderboard — не финальная точка, а лишь калиброванный инструмент, позволяющий более точно определить горизонты нерешенных задач.
Архитектура, лишенная исторической перспективы — хрупка и недолговечна. В дальнейшем необходимо сосредоточиться не только на улучшении метрик, но и на изучении эволюции “знания” в этих моделях. Как меняется “правда” с течением времени, с изменением объемов данных, с появлением новых парадигм обучения? Простое увеличение масштаба недостаточно; требуется глубокое понимание механизмов, лежащих в основе фактической точности и ее деградации.
Очевидно, что оценивать “правду” в вакууме — бессмысленно. Будущие исследования должны учитывать контекст, цели и предполагаемую аудиторию. В конечном счете, система, способная лишь воспроизводить факты, — это мертвая система. Подлинная ценность заключается в способности к адаптации, к критическому осмыслению информации и к созданию новых знаний, основанных на прочном фундаменте фактической точности.
Оригинал статьи: https://arxiv.org/pdf/2512.10791.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Оптические солитоны: новый материал для нейроморфных вычислений
2025-12-13 01:24