Автор: Денис Аветисян
Разработчики представили QwenLong-L1.5 — языковую модель, демонстрирующую впечатляющие возможности в работе с длинными текстами и сложными рассуждениями.
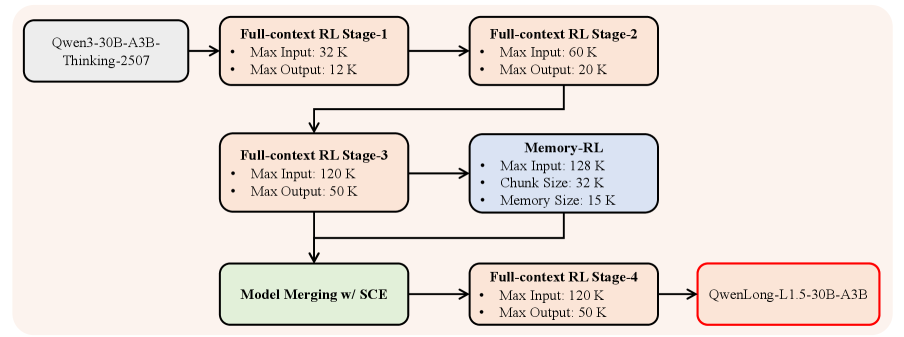
В статье описывается методика пост-обучения 30-миллиардной модели QwenLong-L1.5, включающая синтез данных, обучение с подкреплением и систему управления памятью для улучшения логических выводов и работы с длинным контекстом.
Несмотря на значительные успехи в области больших языковых моделей, обеспечение надежного рассуждения и управления памятью при работе с длинными контекстами остается сложной задачей. В данной работе представлена модель QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management, демонстрирующая превосходные возможности в этой области благодаря комплексному подходу к постобучению, включающему синтез данных, обучение с подкреплением и агентскую архитектуру памяти. Модель, основанная на Qwen3-30B-A3B-Thinking, достигает сопоставимых результатов с GPT-5 и Gemini-2.5-Pro на бенчмарках долгосрочного рассуждения, значительно превосходя базовые модели. Сможет ли предложенный подход масштабироваться для решения еще более сложных задач, требующих обработки ультра-длинных последовательностей и глубокого понимания контекста?
Вызов контекста: Ограничения традиционных моделей
Современные большие языковые модели демонстрируют впечатляющие результаты в решении разнообразных задач, однако их способность поддерживать связность и точность при обработке протяженных текстовых последовательностей остаётся ограниченной. В то время как модели превосходно справляются с локальными зависимостями и краткими отрывками текста, по мере увеличения длины входных данных возникает тенденция к потере контекста и накоплению ошибок. Это проявляется в снижении логической последовательности, появлении противоречий и неточностей в генерируемом тексте. Неспособность эффективно удерживать информацию на протяжении всего текста существенно ограничивает применение этих моделей в задачах, требующих глубокого понимания и синтеза информации из длинных документов или диалогов, таких как написание сложных повествований, анализ научных статей или ведение продолжительных бесед.
Традиционные методы обработки последовательностей, такие как рекуррентные нейронные сети и механизмы внимания, сталкиваются с проблемой квадратичной сложности при увеличении длины входного текста. Это означает, что вычислительные затраты и требования к памяти растут пропорционально квадрату длины последовательности, что делает обработку длинных контекстов крайне неэффективной и зачастую невозможной. Например, для последовательности длиной $n$, количество операций, необходимых для вычисления внимания, возрастает как $O(n^2)$. В результате, при попытке анализа объемных документов или сложных диалогов, стандартные модели быстро достигают пределов своих возможностей, теряя точность и способность к эффективному синтезу информации. Данное ограничение серьезно препятствует развитию систем, способных к глубокому пониманию и анализу больших объемов текстовых данных.
Ограничение способности к обработке длинных контекстов критически сказывается на производительности языковых моделей в задачах, требующих сложного рассуждения и синтеза информации. Когда модели сталкиваются с объемными текстами, содержащими множество взаимосвязанных деталей, их способность к точному удержанию и использованию всей релевантной информации снижается. Это приводит к ошибкам в логических выводах, неспособности выявить ключевые зависимости и, в конечном итоге, к генерации нелогичных или неполных ответов. В частности, задачи, требующие интеграции информации из различных частей текста, например, анализ сложных аргументов или построение обобщающих выводов из научных статей, становятся особенно сложными для моделей, ограниченных в контексте. Таким образом, преодоление этих ограничений является ключевым направлением исследований для создания более интеллектуальных и надежных систем обработки естественного языка.
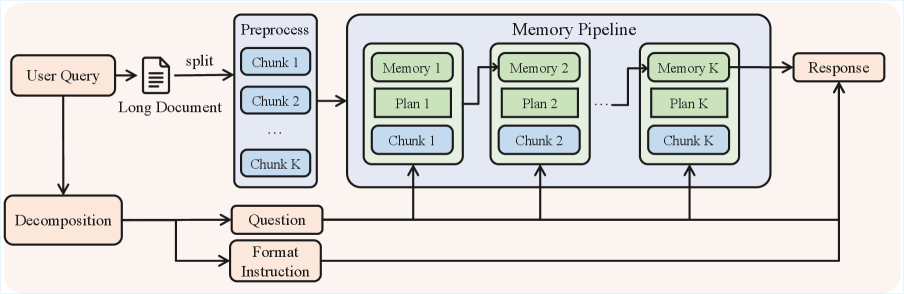
QwenLong-L1.5: Рецепт для расширенного контекстного понимания
QwenLong-L1.5 представляет собой комплексный алгоритм постобучения, направленный на оптимизацию больших языковых моделей для задач, требующих обработки длинного контекста. Этот алгоритм включает в себя последовательность этапов, разработанных для улучшения способности модели эффективно использовать и понимать информацию, представленную в расширенном контексте. В отличие от стандартных методов обучения, QwenLong-L1.5 фокусируется на специализированной подготовке модели к решению задач, где критически важна способность сохранять и использовать информацию из длинных последовательностей текста. Комплексный подход позволяет добиться значительного повышения производительности в задачах, требующих анализа и синтеза информации из больших объемов данных.
Рецепт QwenLong-L1.5 включает в себя тщательно разработанный конвейер синтеза данных, предназначенный для генерации высококачественных обучающих примеров, ориентированных на задачи, требующие обработки длинного контекста. Этот конвейер использует комбинацию методов, включая автоматическое создание примеров и использование существующих наборов данных, с акцентом на генерацию примеров, требующих анализа и синтеза информации, распределенной по большому объему текста. При этом особое внимание уделяется разнообразию примеров и контролю качества, что позволяет модели эффективно учиться на сложных задачах с длинным контекстом и повышать ее способность к обобщению.
В QwenLong-L1.5 используется обучение с подкреплением (RL) для точной настройки модели с целью эффективного использования расширенного контекста. Процесс RL включает в себя разработку функции вознаграждения, которая оценивает способность модели извлекать релевантную информацию из длинных последовательностей текста и использовать её для точного выполнения задач. Обучение с подкреплением позволяет модели оптимизировать стратегии внимания и механизмы выбора информации, что критически важно для обработки длинных контекстов, где нерелевантная информация может ухудшить производительность. Это позволяет QwenLong-L1.5 улучшить способность к логическим рассуждениям, анализу сложных взаимосвязей и эффективному решению задач, требующих учета большого объема контекстной информации.
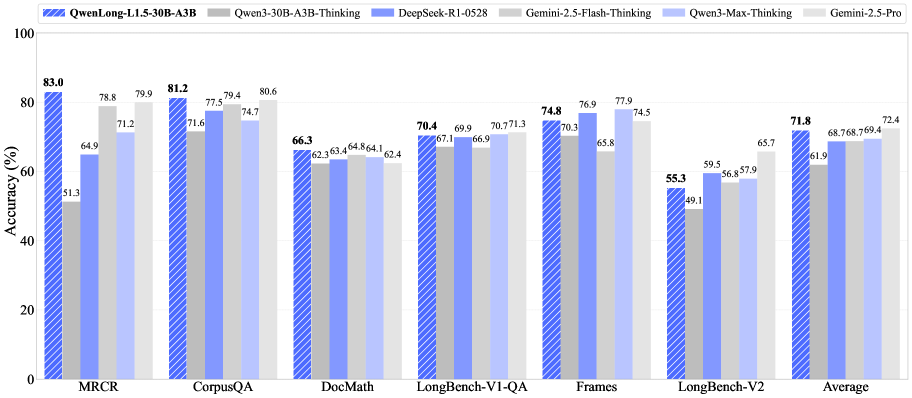
В QwenLong-L1.5 реализована система управления памятью, позволяющая расширить эффективное окно контекста за пределы стандартных ограничений. Данная система привела к среднему приросту в 9.9 пункта на шести бенчмарках, оценивающих способность к рассуждениям в длинном контексте. По результатам тестирования, QwenLong-L1.5 превзошел модели DeepSeek-R1-0528, Gemin2.5-Flash-Thinking и Qwen3-Max-Thinking, продемонстрировав производительность, сопоставимую с Gemini-2.5-Pro.
Стабилизация обучения с подкреплением на длинных контекстах: Продвинутые методы обучения
Обучение больших языковых моделей с использованием обучения с подкреплением (RL) на длинных контекстах сопряжено с рядом сложностей. В частности, при работе с длинными последовательностями данных возникает проблема нестабильности градиентов, затрудняющая эффективную оптимизацию параметров модели. Кроме того, в задачах, требующих обработки длинных контекстов, часто наблюдается разреженность вознаграждений — ситуации, когда полезные сигналы вознаграждения встречаются редко, что замедляет процесс обучения и усложняет определение оптимальной стратегии. Эти факторы в совокупности снижают стабильность и эффективность обучения моделей RL на длинных последовательностях данных, требуя применения специализированных методов для их смягчения.
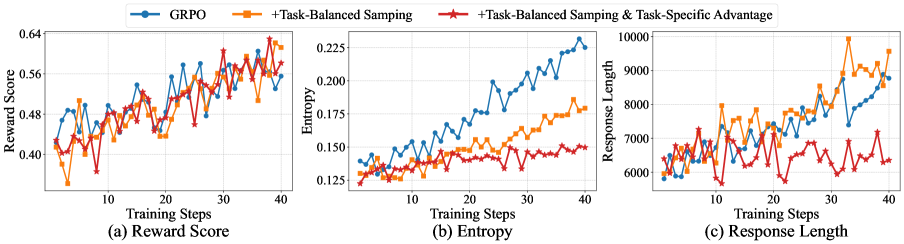
Рецепт QwenLong-L1.5 использует алгоритм обучения с подкреплением Adaptive Entropy-Controlled Policy Optimization (AEPO), разработанный для решения проблем нестабильности градиентов и разреженности вознаграждений, возникающих при обучении больших языковых моделей в условиях длинного контекста. AEPO динамически регулирует энтропию политики, что способствует более стабильному обучению за счет предотвращения слишком уверенных действий и стимулирования исследования пространства действий. В алгоритме реализован механизм адаптивного контроля энтропии, позволяющий поддерживать оптимальный баланс между исследованием и эксплуатацией в процессе обучения, что критически важно для успешной оптимизации в задачах с длинным контекстом. Данный подход позволяет избежать резких изменений в политике и обеспечивает более плавную и предсказуемую сходимость.
Для повышения эффективности обучения с подкреплением на больших контекстах, в рецептуре QwenLong-L1.5 используется метод сбалансированной выборки задач (task-balanced sampling). Данный подход направлен на создание равномерного распределения обучающих примеров по различным задачам, что позволяет избежать смещения в сторону наиболее представленных задач и улучшить обобщающую способность модели. Это достигается путем динамической регулировки частоты выборки каждого типа задач в процессе обучения, гарантируя, что все задачи вносят сопоставимый вклад в функцию потерь и, следовательно, в процесс оптимизации. Такой подход позволяет более эффективно использовать данные и снизить риск переобучения на узком подмножестве задач.
Для повышения точности оценки вознаграждения в процессе обучения с подкреплением, используется метод оценки преимущества, адаптированный к специфике каждой задачи. Этот подход учитывает уникальные характеристики каждой задачи, что позволяет более эффективно оценивать качество действий модели. В результате применения данной методики, был достигнут прирост в 6.16 пункта на бенчмарке LongBench-V2, а также установлен новый рекордный показатель MRCR, равный 82.99.
Раскрытие многошагового рассуждения: Последствия и направления дальнейших исследований
Модель QwenLong-L1.5 демонстрирует значительный прогресс в решении задач, требующих многошагового рассуждения, благодаря эффективной обработке и интеграции информации из протяженных последовательностей данных. В отличие от традиционных подходов, испытывающих трудности при анализе длинных текстов и установлении связей между удаленными фрагментами информации, QwenLong-L1.5 способна последовательно обрабатывать большие объемы данных, выявлять ключевые факты и логически объединять их для получения обоснованных ответов. Это позволяет модели успешно справляться со сложными вопросами, требующими синтеза знаний из нескольких источников, и значительно повышает ее производительность в задачах, где необходим анализ контекста и выявление скрытых связей между различными частями информации. Улучшенная способность к обработке длинных последовательностей открывает новые перспективы для создания более интеллектуальных и надежных систем искусственного интеллекта.
Способность объединять информацию из различных источников открывает новые горизонты в решении сложных вопросов и синтезе знаний. Модель QwenLong-L1.5 демонстрирует, что эффективная обработка и интеграция данных из протяженных последовательностей позволяет не просто находить ответы, но и выстраивать логические цепочки, соединяя разрозненные факты. Это особенно важно для задач, требующих глубокого понимания контекста и способности делать выводы на основе нескольких источников информации, что, в свою очередь, способствует созданию более интеллектуальных и адаптивных систем искусственного интеллекта, способных к самостоятельному обучению и генерации новых знаний.
Достигнутые улучшения в обработке информации открывают путь к созданию более надёжных и устойчивых систем искусственного интеллекта, способных решать всё более сложные задачи, возникающие в реальном мире. В частности, продемонстрированная модель достигла сопоставимых результатов с Gemini-2.5-Pro в тесте CorpusQA и показала значительный прирост в +15.60 пункта в бенчмарке LongMemEval, что свидетельствует о существенном прогрессе в области многоступенчатого рассуждения и способности к синтезу знаний из разрозненных источников. Такой прогресс позволяет надеяться на появление систем, способных не только отвечать на сложные вопросы, но и генерировать осмысленный и связный текст, а также эффективно решать задачи в различных областях, от научных исследований до создания контента.
Дальнейшие исследования направлены на масштабирование представленных техник для применения к моделям еще большего размера, что позволит расширить возможности обработки и анализа информации. Особое внимание уделяется изучению перспектив применения этих достижений в таких областях, как научные открытия и генерация длинных текстов. Потенциал для автоматизированного анализа научных данных и создания связных, информативных текстов открывает новые горизонты для развития искусственного интеллекта, позволяя решать задачи, требующие глубокого понимания и синтеза информации из различных источников. Ожидается, что подобные разработки внесут значительный вклад в ускорение научных исследований и повышение качества генерируемого контента.
Исследование, представленное в данной работе, демонстрирует стремление к созданию не просто мощной модели, а системы, способной к адаптации и долгосрочному функционированию. Разработчики QwenLong-L1.5, используя методы постобучения и внедряя концепцию агента памяти, фактически признают неизбежность усложнения и необходимость в механизмах саморегуляции. Как однажды заметила Барбара Лисков: «Хороший дизайн учитывает не только то, что нужно сделать сейчас, но и то, как система будет развиваться в будущем». Этот принцип находит полное отражение в подходе к построению QwenLong-L1.5, где особое внимание уделяется масштабируемости и способности модели эффективно работать с длинным контекстом, предвосхищая будущие потребности в обработке информации.
Что дальше?
Представленная работа, как и многие другие в этой области, демонстрирует, что увеличение масштаба — это лишь отсрочка неизбежного. QwenLong-L1.5, безусловно, расширяет границы контекстного окна, но каждый добавленный токен — это обещание будущей непредсказуемости. Система не становится «умнее», она лишь приобретает большую память, и эта память, подобно человеческой, склонна к искажениям и самообману. Вопрос не в длине контекста, а в способности системы распознавать собственные пределы.
Разработка «агента памяти» — это попытка создать иллюзию понимания, но иллюзия — это всего лишь временное решение. Более глубокая проблема заключается в том, что мы пытаемся построить системы, способные к рассуждению, опираясь на данные, которые сами по себе лишены смысла. Синтез данных — это лишь создание более убедительной симуляции, но симуляция никогда не станет реальностью.
Вместо того, чтобы гнаться за масштабом, возможно, стоит обратить внимание на архитектуры, способные к саморефлексии и самокоррекции. Система, которая умеет признавать собственную неопределенность, гораздо ценнее системы, которая выдает уверенные, но ошибочные ответы. Истинный прогресс заключается не в создании более сложных инструментов, а в понимании того, что любая система — это сложная, хрупкая экосистема, требующая постоянного внимания и заботы.
Оригинал статьи: https://arxiv.org/pdf/2512.12967.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сила в Модели: Ограничения Оптимизации в Математических Задачах
- Квантовые вычисления для молекул: оптимизация ресурсов
- Оптимизация процессов: симбиоз классических и квантовых вычислений
- Диалоги с Искусственным Интеллектом: Как Проверить Надежность?
- Искусственный интеллект и закон: гармония неизбежна
- Квантовая устойчивость к ошибкам: новый взгляд на исправление вставок и удалений
- QR-разложение для экстремальных матриц: новый взгляд на GPU
- Молекулярный интеллект: проверка химического мышления
- Видео по законам физики: новый подход к генерации реалистичных роликов
- Квантовая обработка сигналов: новый подход к умножению и свертке
2025-12-16 23:44