Автор: Денис Аветисян
Новый подход к выявлению синтетического контента фокусируется на способности современных генеративных моделей воссоздать исходное изображение, предлагая более надежный способ оценки его подлинности.
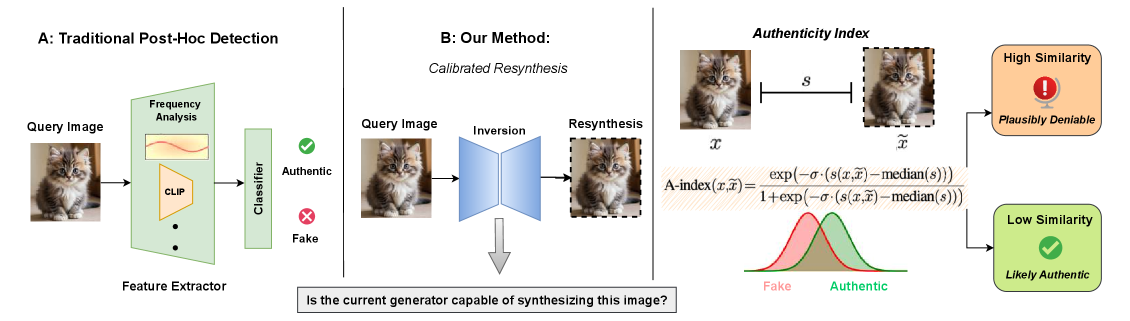
В статье представлена концепция ‘индекса подлинности’, позволяющая оценивать вероятность успешной ресинтезации изображения и повышать устойчивость к манипуляциям.
Современные генеративные модели создают контент, неотличимый от подлинного, ставя под угрозу доверие к цифровым медиа. В работе ‘Robust and Calibrated Detection of Authentic Multimedia Content’ предложен новый подход к проверке подлинности, основанный на концепции «обоснованного отрицания» — способности достоверно воссоздать изображение с помощью современных генераторов. Вместо бинарной классификации, авторы вводят «Индекс подлинности», позволяющий оценивать вероятность того, что контент является подлинным или создан искусственно, и демонстрируют устойчивость к атакам, адаптирующимся к детекторам. Сможет ли предложенный подход стать надежным инструментом в борьбе с распространением дипфейков и восстановлением доверия к цифровому контенту?
Синтетическая реальность: Нарастающая угроза подделок
В последние годы наблюдается экспоненциальный рост возможностей генеративных моделей, таких как генеративно-состязательные сети (GAN) и, в особенности, диффузионные генеративные модели. Эти алгоритмы способны создавать контент — изображения, видео, аудио и текст — с беспрецедентным уровнем реализма, часто неотличимым от созданного человеком. Подобный прогресс обусловлен не только усовершенствованием архитектур нейронных сетей, но и увеличением объемов данных, используемых для обучения. В результате, синтетический контент становится все более убедительным, представляя собой серьезный вызов для существующих методов проверки подлинности и открывая новые возможности для создания гиперреалистичных виртуальных миров и цифровых двойников.
Современные методы обнаружения синтетического контента, такие как бинарная классификация, демонстрируют растущую уязвимость перед новейшими достижениями в области генеративных моделей. Текущие детекторы дипфейков, включая GenConViT, показывают лишь умеренную эффективность, достигая значения AUC всего 0.6154. Этот показатель подчеркивает существенные ограничения существующих систем и вызывает серьезные опасения относительно подлинности цифрового контента и доверия к нему. Подобная недостаточная точность ставит под вопрос способность оперативно и надежно выявлять манипуляции, что может иметь далеко идущие последствия для информационной безопасности и общественного восприятия.
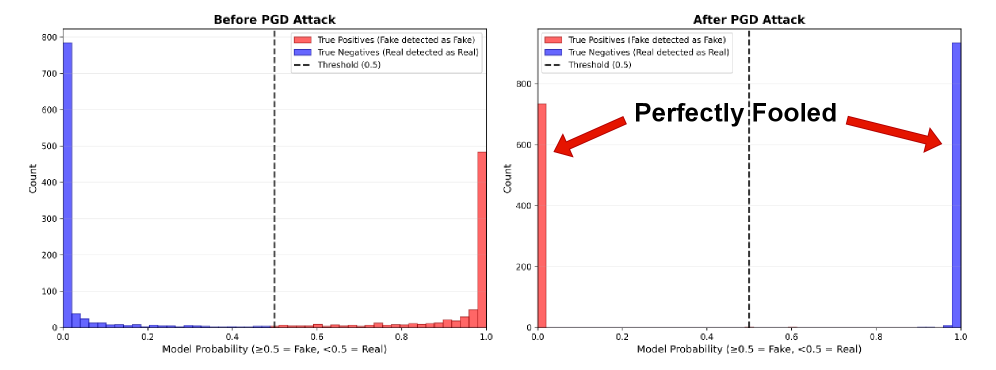
Уязвимость систем обнаружения синтетического медиа распространяется и на их устойчивость к воздействиям. Исследования показывают, что даже незначительные изменения в данных способны обмануть современные детекторы. Например, точность системы D3, демонстрировавшая результат в 83.90%, резко падает до всего 1.75% после проведения целенаправленной атаки, направленной на внесение едва заметных искажений. Данный факт подчеркивает критическую необходимость разработки более устойчивых и надежных методов обнаружения, способных противостоять подобным манипуляциям и обеспечивать достоверность цифрового контента.
Обратное моделирование: Восстановление истины из шума
Метод обнаружения на основе инверсии представляет собой новый подход, заключающийся в попытке реконструкции изображения внутри латентного пространства генеративной модели. Вместо прямой классификации, изображение проецируется в латентное пространство, где модель пытается найти ближайшее соответствие. Успешная реконструкция, при которой изображение может быть точно воссоздано из латентного вектора, указывает на его соответствие распределению данных, на котором обучалась модель. Этот процесс позволяет оценить, насколько реалистично и правдоподобно изображение с точки зрения генеративной модели, предоставляя информацию о его потенциальной подлинности или искусственном происхождении.
Метод обратного восстановления, в частности, Rectified Flow Inversion, является ключевым инструментом в анализе синтезируемости изображения. Он позволяет детально изучить, насколько точно исходное изображение может быть воссоздано генеративной моделью, путем итеративной оптимизации в латентном пространстве. В процессе восстановления оценивается разница между исходным и реконструированным изображением, что позволяет количественно определить степень соответствия изображения распределению данных, на котором обучалась модель. Низкое качество восстановления указывает на аномальность или нереалистичность изображения, поскольку модель испытывает трудности с его точной ресинтезацией. Анализ траектории восстановления в латентном пространстве также предоставляет информацию о структуре данных и особенностях обучения модели.
В отличие от традиционных методов классификации, которые просто определяют, принадлежит ли изображение к определенной категории, инверсионный подход позволяет оценить степень соответствия изображения распределению данных, на котором обучалась генеративная модель. Этот анализ выходит за рамки бинарной оценки «подлинное/поддельное», предоставляя количественную меру правдоподобия изображения. Вместо простого определения, является ли изображение «кошкой» или «не кошкой», метод оценивает, насколько хорошо изображение может быть воссоздано генератором, что позволяет выявить тонкие несоответствия и аномалии, указывающие на манипуляции или несоответствия в данных. Такой подход дает более детальное представление об аутентичности изображения, оценивая его внутреннюю согласованность и соответствие ожидаемым характеристикам.

Количественная оценка достоверности: Многомерный подход
Индекс аутентичности, формируемый на основе комбинации метрик, таких как $SSIM$ (Structural Similarity Index), $PSNR$ (Peak Signal-to-Noise Ratio), $LPIPS$ (Learned Perceptual Image Patch Similarity) и сходство $CLIP$, обеспечивает комплексную оценку точности реконструкции изображения. $SSIM$ измеряет структурное сходство, $PSNR$ — отношение сигнала к шуму на уровне пикселей, $LPIPS$ оценивает перцептуальное расстояние между изображениями, а сходство $CLIP$ позволяет оценить семантическую согласованность. Комбинирование этих метрик позволяет получить более полную и объективную оценку качества реконструкции, чем использование какой-либо отдельной метрики.
Используемый подход к оценке аутентичности изображения опирается на совокупность метрик, каждая из которых измеряет различные аспекты качества реконструкции. Структурное сходство оценивается с помощью $SSIM$, отражающего восприятие изменений в изображении человеческим глазом. Пиксельная точность измеряется метрикой $PSNR$, характеризующей отношение сигнала к шуму. Восприятие различий между изображениями оценивается с помощью $LPIPS$, учитывающей перцептуальное расстояние. Наконец, семантическая согласованность проверяется с использованием $CLIP Similarity$, определяющей соответствие между изображением и его текстовым описанием. Комбинация этих метрик позволяет получить надежную и всестороннюю оценку аутентичности, учитывая как низкоуровневые, так и высокоуровневые характеристики изображения.
Подход к оценке аутентичности, основанный на комбинировании нескольких метрик качества изображения, позволяет повысить надежность анализа по сравнению с использованием единственного показателя. Разработанная система, включающая в себя такие параметры, как $SSIM$, $PSNR$, $LPIPS$ и семантическое сходство $CLIP$, демонстрирует высокую точность оценки, при этом уровень ложноположительных результатов составляет всего 1%. Это достигается за счет комплексной оценки различных аспектов качества изображения, что снижает вероятность ошибок, возникающих при использовании одного лишь критерия.

Правдоподобное отрицание: Когда реальность становится неотличимой от симуляции
Феномен правдоподобного отрицания возникает, когда изображение может быть достоверно воссоздано генеративной моделью, что делает невозможным установление его первоначального источника. Этот процесс, по сути, стирает границы между подлинностью и синтезом, поскольку воссозданное изображение неотличимо от оригинала с технической точки зрения. В результате, доказательства, основанные на визуальном контенте, становятся ненадежными, а верификация изображений — сложной задачей. Практически любое изображение может быть «объяснено» как результат работы генеративной модели, что подрывает доверие к визуальным данным и ставит под сомнение их юридическую и социальную значимость.
Возникающая проблема правдоподобного отрицания имеет далеко идущие последствия для различных сфер деятельности. В частности, это ставит под вопрос достоверность визуальных доказательств, используемых в судебных разбирательствах и расследованиях, поскольку становится все сложнее определить подлинность изображения. Журналистика также сталкивается с новыми вызовами, поскольку фальсифицированные изображения могут легко распространяться как реальные, подрывая доверие к новостным источникам и общественному дискурсу. Не менее актуальна эта проблема и для платформ социальных сетей, которым необходимо эффективно модерировать контент и бороться с дезинформацией, однако существующие методы становятся все менее эффективными перед лицом совершенствующихся генеративных моделей. Таким образом, необходимость разработки надежных методов верификации изображений становится критически важной для поддержания целостности информации и доверия к визуальному контенту в современном цифровом мире.
Предложенная методика, сочетающая в себе Zero-Shot Detection и новый аналитический фреймворк, позволяет оценивать устойчивость систем обнаружения подделок к генеративным моделям, которые ранее не встречались в процессе обучения. Исследования показали, что существующие методы, такие как UFD, FreqNet, NPR и FatFormer, демонстрируют полную уязвимость — 100% успешность атак — при использовании специально разработанных против них образцов. Этот результат подчеркивает критическую необходимость в разработке более надежных и адаптивных систем верификации, способных противостоять постоянно совершенствующимся генеративным технологиям и обеспечивать достоверность цифрового контента.

За рамки обнаружения: К устойчивой верификации
Методы пост-фактической (post-hoc) проверки, исследованные в данной работе, играют ключевую роль в выявлении манипулированного контента, не внося при этом изменений в исходные данные. В отличие от подходов, требующих предварительной обработки или водяных знаков, пост-фактическая проверка анализирует медиафайл как есть, что особенно важно для сохранения целостности доказательств или архивных материалов. Такой подход позволяет обнаружить следы редактирования, подмены или искажения информации, не нарушая при этом её подлинность. Эффективность пост-фактической проверки заключается в анализе статистических аномалий, артефактов сжатия или несоответствий в визуальных особенностях, которые могут указывать на вмешательство. Использование подобных методов становится все более актуальным в условиях распространения дипфейков и других форм цифрового обмана.
Исследование уязвимости систем обнаружения манипуляций к так называемым «атакам с возмущениями» является ключевым для создания надежных инструментов верификации. Адверсарные возмущения — это намеренные, едва заметные изменения в данных, призванные обмануть алгоритмы машинного обучения. Для оценки устойчивости систем используется техника PGD (Projected Gradient Descent) — метод, позволяющий генерировать наиболее эффективные адверсарные примеры путем итеративного внесения небольших, но целенаправленных изменений в исходные данные. Применение PGD-атак в процессе обучения и тестирования позволяет выявить слабые места в системах обнаружения и разработать более устойчивые алгоритмы, способные противостоять целенаправленным атакам и гарантировать достоверность контента. Понимание принципов генерации и воздействия адверсарных возмущений — необходимое условие для построения действительно надежных систем верификации.
Постоянная эволюция генеративных моделей и систем обнаружения манипуляций представляет собой непрерывную гонку вооружений, требующую постоянного совершенствования обеих сторон. Развитие всё более реалистичных методов генерации контента, таких как глубокие нейронные сети, неизбежно приводит к появлению новых, более изощрённых способов обмана систем обнаружения. В ответ на это, исследователи вынуждены разрабатывать более сложные алгоритмы, способные выявлять даже самые тонкие манипуляции. Этот цикл инноваций и усовершенствований не имеет конечной точки, поскольку каждая новая разработка в области генерации контента требует соответствующей адаптации и улучшения систем верификации. Таким образом, поддержание надежной защиты от манипуляций требует непрерывного инвестирования в исследования и разработку новых методов обнаружения, а также предвидения и нейтрализации будущих угроз.

Работа демонстрирует неизбежную эволюцию цифрового мира к состоянию, где достоверность контента определяется не абсолютной истиной, а степенью его воссоздаваемости. Авторы предлагают метрику — Индекс Подлинности — как попытку количественно оценить эту «пластичность» цифровых данных. Как заметил Джеффри Хинтон: «Я думаю, что мы находимся в начале пути к созданию машин, которые могут учиться и рассуждать, как люди». Эта фраза отражает суть проблемы: чем сложнее становятся генеративные модели, тем тоньше грань между оригиналом и копией, и тем больше внимания нужно уделять не просто обнаружению подделок, а оценке степени «правдоподобия» контента. В конечном итоге, каждое новое «революционное» решение в области генерации изображений лишь усложняет задачу верификации, превращая её в бесконечную гонку вооружений.
Что дальше?
Предложенный “Индекс Подлинности” — забавная попытка измерить неуловимое. Полагаться на способность генеративных моделей воссоздать изображение — это, конечно, элегантно, но напоминает попытку удержать воду решетом. Рано или поздно, найдётся генератор, который с лёгкостью обманет даже самый изощрённый индекс. И тогда придётся изобретать новый, и так до бесконечности. Этот бесконечный цикл — не столько научный прогресс, сколько дорогостоящая гонка вооружений.
Идея “правдоподобного отрицания” — любопытна, но остаётся открытым вопрос о масштабируемости. Предполагается, что каждый артефакт, каждая микроскопическая нестыковка будет обнаружена. Но что если генеративные модели научатся намеренно вносить “правдоподобные” ошибки, чтобы запутать детекторы? Тогда детекция сведётся к угадыванию намерений алгоритма — задаче, не имеющей решения.
В конечном итоге, вся эта работа — лишь временное облегчение. Продакшен всегда найдёт способ сломать любую “робастную” систему. Тесты — это, конечно, форма надежды, но не гарантия. А значит, через пару лет появятся новые, ещё более изощрённые генераторы, и вся эта история начнётся сначала. И это, пожалуй, самое предсказуемое развитие событий.
Оригинал статьи: https://arxiv.org/pdf/2512.15182.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Неупорядоченные системы с неэрмитовыми эффектами
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Джозефсоновские переходы на квантовых материалах: новые горизонты сверхпроводимости
2025-12-18 17:39