Автор: Денис Аветисян
Исследователи изучают возможности применения квантовых генеративных моделей для обучения и сэмплирования сжатых представлений данных гидродинамики, открывая потенциал для более эффективных симуляций.
В статье представлено исследование применения квантовых схемных машин к методу решетчатой гидродинамики для обучения латентному пространству и сравнение с классическими LSTM сетями.
Несмотря на успехи в моделировании гидродинамических процессов, задача эффективного представления и генерации данных сложной турбулентности остается актуальной. В работе «Quantum Generative Models for Computational Fluid Dynamics: A First Exploration of Latent Space Learning in Lattice Boltzmann Simulations» представлено первое исследование применения квантовых генеративных моделей к сжатым латентным представлениям данных вычислительной гидродинамики. Показано, что квантовые модели, в частности Quantum Circuit Born Machine, превосходят классические LSTM-сети в задаче восстановления распределения вортицитетности жидкости, полученного с помощью метода Lattice Boltzmann. Открывает ли это путь к новым, более эффективным алгоритмам моделирования и прогнозирования поведения сложных жидкостных систем?
Моделирование Турбулентности: Преодолевая Границы Традиционных Подходов
Точное моделирование поведения жидкостей, особенно турбулентности, остаётся сложной вычислительной задачей, требующей значительных ресурсов и инновационных подходов. Турбулентность, характеризующаяся хаотичным и непредсказуемым движением, создает огромные трудности для существующих численных методов. Это связано с тем, что для адекватного описания всех масштабов турбулентных вихрей требуется чрезвычайно высокая разрешающая способность сетки, что приводит к экспоненциальному росту вычислительных затрат. Например, для моделирования даже относительно простых потоков необходимо учитывать широкий спектр длин волн, от крупных вихрей, определяющих общую структуру потока, до мельчайших диссипативных элементов. Решение уравнений Навье-Стокса, описывающих движение вязких жидкостей \nabla \cdot \mathbf{T} + \mathbf{f} = 0 , становится практически невозможным для задач с высоким числом Рейнольдса, характеризующим отношение инерционных сил к силам вязкости. Это ограничивает возможности точного прогнозирования и анализа сложных гидродинамических процессов в различных областях науки и техники.
Прямое решение уравнений Навье-Стокса, являющихся основой для моделирования динамики жидкости, зачастую сталкивается с колоссальными вычислительными трудностями. Сложность заключается в том, что эти уравнения описывают нелинейное поведение жидкости, особенно в условиях турбулентности, требуя экспоненциального увеличения вычислительных ресурсов при повышении точности и детализации модели. Это особенно заметно при моделировании сложных потоков, таких как обтекание крыла самолета или перемешивание в реакторе, где необходимо учитывать мельчайшие вихри и градиенты скорости. \nabla \cdot \mathbf{u} = 0 и \rho(\frac{\partial \mathbf{u}}{\partial t} + \mathbf{u} \cdot \nabla \mathbf{u}) = -\nabla p + \mu \nabla^2 \mathbf{u} — ключевые уравнения, решение которых требует значительных временных и аппаратных затрат, что ограничивает возможности моделирования и анализа сложных гидродинамических систем.
Ограничения в точном моделировании динамики жидкостей оказывают существенное влияние на прогресс в различных областях науки и техники. В метеорологии, например, неточности в прогнозировании погоды, особенно экстремальных явлений, напрямую связаны со сложностью адекватного описания турбулентных потоков в атмосфере. В авиационной промышленности совершенствование аэродинамических характеристик летательных аппаратов, снижение сопротивления и повышение эффективности требует детального анализа обтекания крыла и фюзеляжа, что становится непосильной задачей для традиционных вычислительных методов. Не менее важны эти ограничения и в биомедицинской инженерии, где моделирование кровотока в сосудах необходимо для разработки искусственных органов, систем доставки лекарств и понимания механизмов развития сердечно-сосудистых заболеваний. Таким образом, преодоление вычислительных трудностей в моделировании жидкостей является ключевым фактором для дальнейшего развития этих и многих других областей знаний.
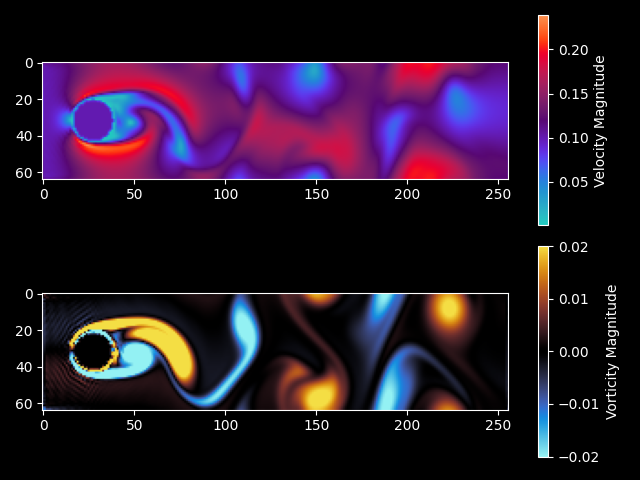
Снижение Размерности: Упрощение Сложных Данных
Методы снижения размерности, такие как метод главных компонент (Principal Component Analysis, PCA) и t-распределенное стохастическое вложение соседей (t-distributed Stochastic Neighbor Embedding, t-SNE), позволяют представить многомерные данные в пространстве меньшей размерности, сохраняя при этом наиболее важную информацию. PCA выполняет линейное преобразование данных, проецируя их на подпространство, определяемое главными компонентами — направлениями наибольшей дисперсии. t-SNE, в свою очередь, использует вероятностный подход для моделирования сходства между точками данных в исходном и целевом пространствах, эффективно сохраняя локальную структуру данных, особенно полезную для визуализации. Оба метода применяются для уменьшения вычислительной сложности, визуализации данных и выявления скрытых закономерностей в сложных наборах данных.
Автокодировщики представляют собой тип нейронной сети, предназначенный для обучения эффективным кодировкам данных и, как следствие, снижения размерности. Принцип работы заключается в обучении сети сжимать входные данные в представление меньшей размерности (кодирование) и затем восстанавливать исходные данные из этого сжатого представления (декодирование). Процесс обучения осуществляется путем минимизации ошибки реконструкции — разницы между исходными данными и восстановленными данными. Архитектура автокодировщика обычно состоит из энкодера, который отображает входные данные в скрытое пространство, и декодера, который реконструирует данные из этого скрытого пространства. В результате обучения сеть учится выделять наиболее важные признаки данных, что позволяет эффективно снизить их размерность без значительной потери информации.
Снижение размерности данных позволяет существенно уменьшить вычислительные затраты при обработке и анализе больших наборов данных. Сокращение количества признаков, сохраняя при этом наиболее важную информацию, упрощает алгоритмы машинного обучения, снижает требования к объему памяти и ускоряет обучение моделей. Кроме того, визуализация данных, сниженных до двух или трех измерений, может выявить скрытые закономерности, кластеры и взаимосвязи, которые были бы не видны в исходном многомерном пространстве. Это особенно полезно при анализе сложных наборов данных, где визуализация и интерпретация данных затруднены из-за высокой размерности.

Латентные Пространства: Дискретное vs. Непрерывное Представление
Вариационные автоэнкодеры (VAE) формируют вероятностные представления данных в латентном пространстве, что позволяет не только сжимать входные данные в компактный код, но и генерировать новые образцы, похожие на те, на которых модель обучалась. В отличие от традиционных автоэнкодеров, VAE обучаются отображать входные данные в распределение вероятностей в латентном пространстве, а не в отдельные точки. Это достигается за счет использования вероятностных кодировщиков и декодировщиков, что позволяет моделировать неопределенность и генерировать разнообразные выходные данные путем случайной выборки из этого распределения. Таким образом, p(z|x) представляет собой вероятность латентного вектора z при заданном входном векторе x, а декодировщик восстанавливает данные из этого вектора.
Векторно-квантованные вариационные автоэнкодеры (VQ-VAE) расширяют возможности стандартных VAE, используя дискретные представления в латентном пространстве. Вместо непрерывного вектора, латентное пространство моделируется как набор дискретных кодов, полученных посредством векторной квантизации. Это позволяет снизить вычислительную сложность модели, так как операции с дискретными значениями часто более эффективны. Кроме того, дискретное латентное пространство упрощает интерпретацию данных и может способствовать более целенаправленной генерации данных, поскольку отдельные коды можно ассоциировать с конкретными признаками или паттернами в исходных данных.
Дискретное латентное пространство, в отличие от непрерывного, упрощает процесс моделирования за счет представления данных в виде конечного набора дискретных значений. Это позволяет использовать категориальные распределения и алгоритмы, оптимизированные для дискретных данных, что может снизить вычислительную сложность и повысить эффективность обучения. Кроме того, дискретизация латентного пространства облегчает целенаправленную генерацию данных, поскольку конкретные дискретные значения могут быть напрямую связаны с определенными характеристиками или атрибутами генерируемых образцов, обеспечивая более точный контроль над процессом генерации.
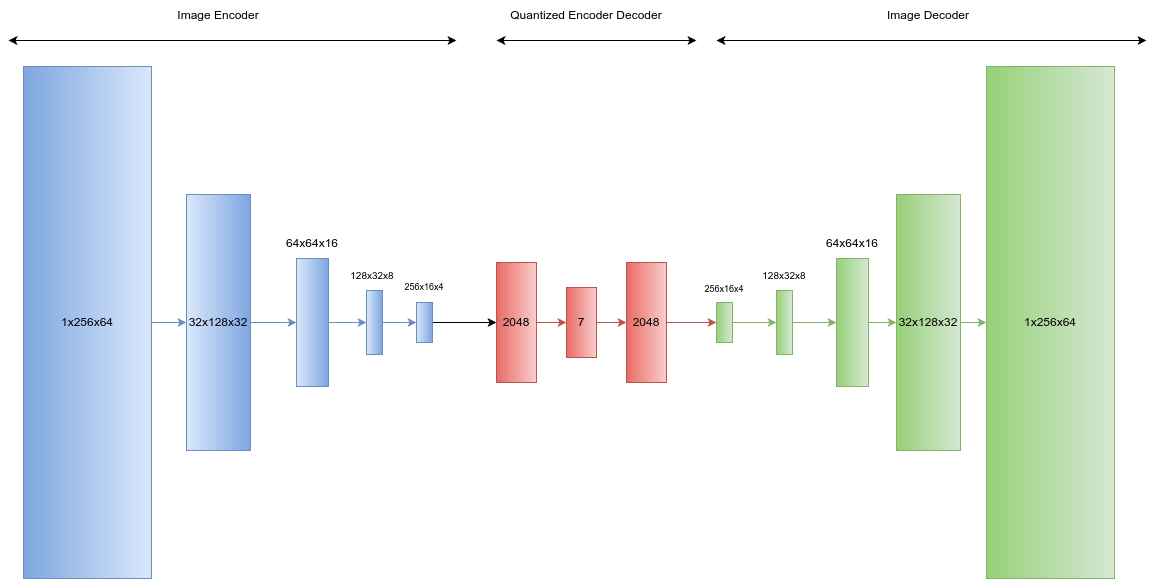
Квантовые Генеративные Модели: Новый Горизонт
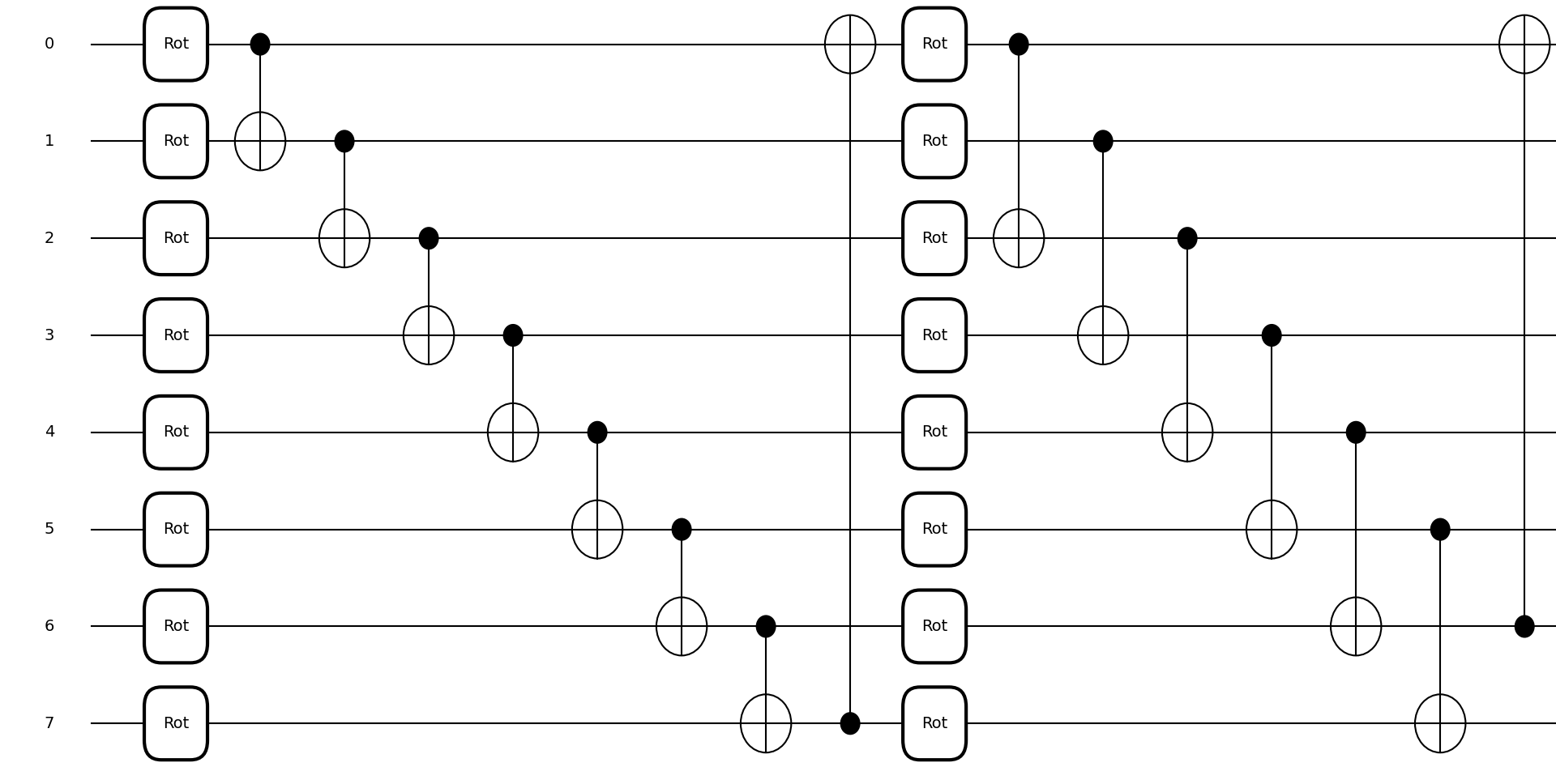
Квантовые вычисления представляют собой принципиально новый подход к обработке информации, открывающий возможности для создания генеративных моделей, превосходящих классические аналоги по эффективности. В отличие от традиционных компьютеров, оперирующих битами, квантовые компьютеры используют кубиты, что позволяет им одновременно находиться в нескольких состояниях благодаря явлениям суперпозиции и запутанности. Этот качественно иной принцип работы позволяет квантовым генеративным моделям, таким как квантовые генеративно-состязательные сети (QGAN) и квантовые машины, основанные на функциях рождения (QCBM), исследовать значительно более широкое пространство возможных решений и генерировать сложные распределения данных с меньшими вычислительными затратами. Потенциал квантовых алгоритмов для моделирования вероятностных распределений может привести к прорывам в различных областях, включая машинное обучение, искусственный интеллект и научное моделирование.
Квантовые генеративные состязательные сети (QGAN) и машины, основанные на рождении квантовых схем (QCBM), представляют собой новаторский подход к генерации сложных распределений данных, использующий принципы квантовой механики. В отличие от классических генеративных моделей, QGAN используют квантовые вычисления для обучения генератора и дискриминатора, позволяя им эффективно моделировать высокоразмерные данные. QCBM, в свою очередь, оперируют квантовыми схемами, генерируя вероятностные распределения, определяемые амплитудами состояний этих схем. Такой подход позволяет создавать модели, способные генерировать более реалистичные и разнообразные данные, чем их классические аналоги, открывая новые возможности в таких областях, как машинное обучение, компьютерное зрение и обработка естественного языка.
Исследования квантовых генеративных моделей демонстрируют потенциальное превосходство над классическими подходами в задачах генерации данных. Оценка производительности с использованием метрики Average Minimum Distance (среднее минимальное расстояние) выявила значимые результаты: модель Quantum Circuit Born Machine (QCBM) достигла показателя приблизительно 0.8. Это существенно превосходит результаты, полученные с использованием рекуррентной нейронной сети LSTM (2.4) и квантовой генеративной состязательной сети QGAN (1.5). Полученные данные указывают на то, что QCBM обладает способностью более эффективно моделировать сложные распределения данных, открывая перспективы для применения в различных областях, требующих генерации реалистичных и разнообразных данных.
Синтез Классического и Квантового: Путь к Будущему
Несмотря на потенциальные преимущества квантовых генеративных моделей, классические методы, такие как Long Short-Term Memory (LSTM), сохраняют свою ценность и актуальность. LSTM, благодаря своей способности эффективно обрабатывать последовательные данные и улавливать долгосрочные зависимости, продолжает демонстрировать высокую производительность в различных задачах, включая моделирование динамических систем. В ряде случаев, классические алгоритмы, обладая отлаженной реализацией и меньшими требованиями к вычислительным ресурсам, могут превосходить квантовые аналоги, особенно при работе с ограниченными объемами данных или в задачах, где не требуется экспоненциальное ускорение. Поэтому, при разработке новых подходов в вычислительной гидродинамике, важно учитывать сильные стороны классических методов и интегрировать их с квантовыми технологиями, создавая гибридные решения, которые максимально используют преимущества обеих парадигм.
Исследования демонстрируют, что комбинирование классических и квантовых методов может привести к созданию более эффективных решений в области вычислительной гидродинамики. Такой гибридный подход позволяет использовать сильные стороны обеих парадигм: надежность и отработанность классических алгоритмов, таких как LSTM, в сочетании с потенциальной вычислительной мощностью квантовых генеративных моделей. Например, QCBM, объединяющий в себе оба подхода, продемонстрировал значительно превосходящие результаты в задачах поиска ближайших соседей — более 1600 успешных совпадений из 1999, превзойдя как QGAN, так и LSTM. Это указывает на перспективность разработки систем, в которых классические и квантовые алгоритмы работают совместно, дополняя друг друга и позволяя решать сложные задачи, недоступные для каждой из парадигм по отдельности.
Перспективные исследования направлены на выявление конкретных областей применения квантовых генеративных моделей, где они демонстрируют ощутимое преимущество перед классическими подходами в вычислительной гидродинамике. В частности, модель квантового сопоставления ближайших соседей (QCBM) показала впечатляющие результаты, успешно сопоставив более 1600 из 1999 ближайших соседей, что значительно превосходит показатели как квантовых генеративно-состязательных сетей (QGAN), так и рекуррентных нейронных сетей с длинной краткосрочной памятью (LSTM). Эти результаты указывают на потенциал квантовых методов для решения сложных задач моделирования потоков жидкости, открывая новую эру в этой области науки и техники.
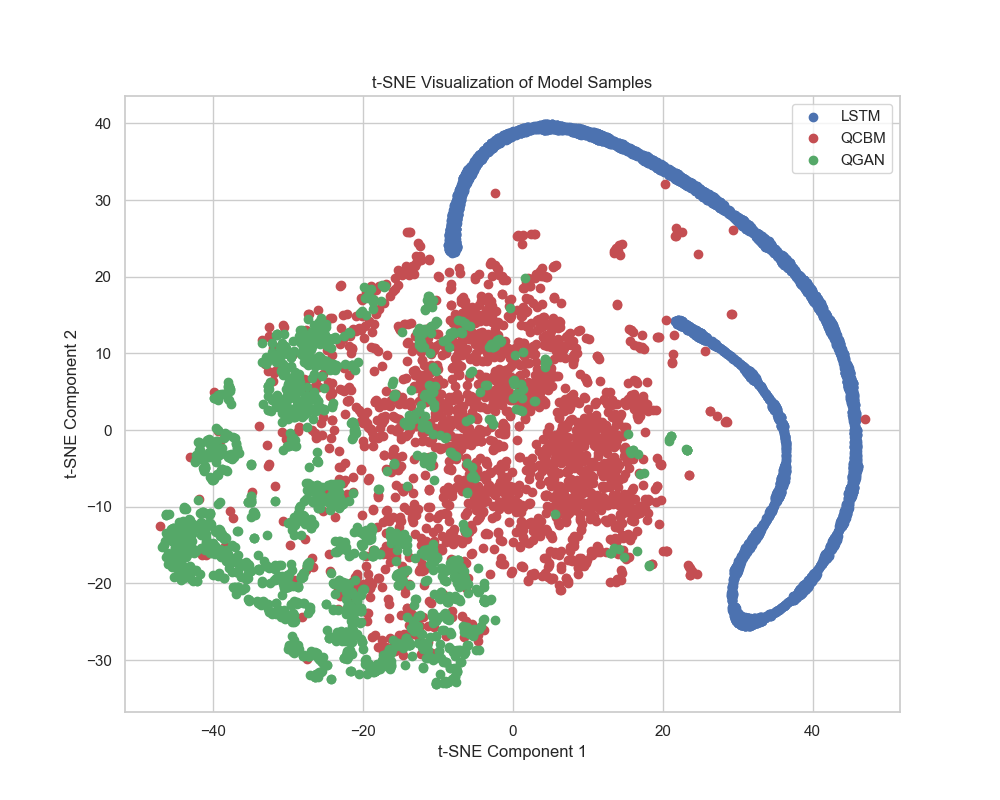
Исследование демонстрирует, что сжатое латентное пространство, полученное с помощью квантовых генеративных моделей, способно эффективно представлять сложные данные гидродинамики. Этот подход, использующий квантовые схемы, позволяет не просто фиксировать структуру данных, но и улавливать динамику взаимодействия между элементами системы. Как однажды заметил Дональд Дэвис: «Документация фиксирует структуру, но не передаёт поведение — оно рождается во взаимодействии». Данное исследование подтверждает эту мысль, показывая, что эффективное представление поведения жидкости требует не только точного описания её структуры, но и понимания принципов её динамики в сжатом латентном пространстве. Применение квантовых генеративных моделей открывает новые возможности для моделирования сложных систем, где поведение неотделимо от структуры.
Что дальше?
Представленные исследования, несомненно, открывают новые возможности для моделирования гидродинамики, однако стоит признать, что настоящая сложность кроется не в самих моделях, а в данных, которые они пытаются описать. Сжатие информации о турбулентных потоках в латентное пространство — задача, требующая не только вычислительных ресурсов, но и глубокого понимания физических ограничений. Успех квантовых генеративных моделей, продемонстрированный в данной работе, скорее указывает на потенциал, чем на окончательное решение.
Очевидно, что необходимо сосредоточиться на разработке более эффективных методов обучения и валидации латентных представлений. Простое улучшение точности прогнозирования недостаточно; необходимо понимать, какие степени свободы в латентном пространстве действительно важны для воспроизведения физически реалистичных потоков. В противном случае, рискуем получить красивые, но бесполезные модели, игнорирующие фундаментальные принципы сохранения.
Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. Будущие исследования должны быть направлены на интеграцию физических знаний непосредственно в процесс обучения, создавая модели, которые не просто имитируют поведение жидкости, но и отражают её внутреннюю структуру. И только тогда мы сможем по-настоящему оценить элегантность и эффективность предложенного подхода.
Оригинал статьи: https://arxiv.org/pdf/2512.22672.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Оптимизация больших языковых моделей: новый подход к снижению требований к ресурсам
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Внимание к квантовой теории поля: нейросети и трансформеры
- Квантовые вычисления с кубитами высшего порядка: новый подход к моделированию
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Динамика в кадре: Как научить ИИ понимать физику видео
2025-12-31 08:53