Автор: Денис Аветисян
Исследователи предлагают метод адаптации языковых моделей непосредственно во время использования, что позволяет улучшить обработку длинных последовательностей без значительных вычислительных затрат.
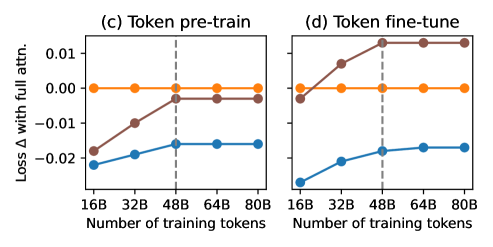
В статье представлен TTT-E2E — метод обучения во время тестирования, использующий градиенты-градиентов для быстрой адаптации весов модели к длинным контекстам.
Попытки масштабирования языковых моделей для обработки длинных контекстов часто сталкиваются с ограничениями вычислительной сложности и необходимостью разработки новых архитектур. В работе ‘End-to-End Test-Time Training for Long Context’ предложен подход, рассматривающий задачу моделирования длинных контекстов как задачу непрерывного обучения, использующий стандартную архитектуру Transformer с оконным вниманием и обновляющий веса модели непосредственно во время тестирования. Этот метод, названный TTT-E2E, позволяет достичь производительности, сопоставимой с полным вниманием, при этом обеспечивая постоянную скорость вывода независимо от длины контекста. Сможет ли такой подход стать основой для создания эффективных и масштабируемых языковых моделей будущего?
За пределами традиций: вызовы длинного контекста
Традиционные архитектуры Transformer, несмотря на свою мощь, испытывают значительные трудности при обработке чрезвычайно длинных последовательностей данных. Это связано с тем, что вычислительная сложность механизма внимания растет квадратично относительно длины входной последовательности O(n^2). По мере увеличения длины текста, необходимое количество вычислений и памяти для обработки каждого токена экспоненциально возрастает, что делает обработку длинных документов, книг или продолжительных диалогов практически невозможной на стандартном оборудовании. Данное ограничение препятствует эффективному извлечению информации и установлению связей между отдаленными частями текста, существенно снижая производительность в задачах, требующих понимания контекста и долгосрочной памяти.
Ограничения традиционных архитектур, таких как Transformer, особенно заметны при обработке задач, требующих анализа обширных контекстов. Например, при всестороннем анализе документов, будь то юридические тексты или научные статьи, способность модели учитывать взаимосвязи между отдаленными фрагментами информации критически важна для формирования адекватных выводов. Аналогичная проблема возникает в сложных диалоговых системах, где понимание предшествующей беседы, охватывающей множество реплик, необходимо для поддержания осмысленного взаимодействия. Неспособность эффективно обрабатывать долгосрочные зависимости приводит к потере важной информации и, как следствие, к снижению качества ответов или неверной интерпретации исходных данных. Таким образом, преодоление этого ограничения является ключевой задачей для развития искусственного интеллекта, способного к глубокому пониманию и логическому мышлению.
Для достижения подлинного понимания в различных задачах обработки естественного языка, таких как анализ больших текстовых массивов, машинный перевод и ведение сложных диалогов, критически важной является эффективная обработка долгосрочных зависимостей. Способность модели устанавливать связи между элементами текста, находящимися на значительном расстоянии друг от друга, позволяет ей улавливать нюансы смысла и контекста, которые могут быть упущены при рассмотрении только локальных фрагментов. Игнорирование этих долгосрочных связей приводит к поверхностному пониманию, снижая точность и релевантность результатов. Поэтому, разработка методов, способных эффективно моделировать и использовать информацию о долгосрочных зависимостях, является ключевой задачей для создания интеллектуальных систем, способных к глубокому и осмысленному взаимодействию с языком.
Эффективные механизмы внимания: компромиссы и решения
Внимание с фиксированным окном (Sliding Window Attention) представляет собой практичный подход к снижению вычислительной сложности механизма внимания, особенно при работе с длинными последовательностями. Вместо вычисления внимания между каждым токеном и всеми остальными, рассматривается лишь ограниченное окно соседних токенов. Это существенно уменьшает количество операций, с ростом последовательности сложность снижается с O(n^2) до O(n), где n — длина последовательности. Однако, такая локализация внимания может приводить к потере информации о глобальном контексте, поскольку связи между удаленными элементами последовательности игнорируются. Размер окна является ключевым параметром, влияющим на компромисс между вычислительной эффективностью и способностью модели улавливать долгосрочные зависимости.
Оптимизация FlashAttention направлена на повышение эффективности вычислений механизма внимания за счет оптимизации паттернов доступа к памяти. Традиционные реализации внимания требуют значительного объема памяти для хранения промежуточных результатов, что приводит к узким местам при обработке длинных последовательностей. FlashAttention использует технику тайлинга (tiling) и переупорядочивает операции таким образом, чтобы минимизировать количество чтений и записей в медленную память (например, DRAM), используя более быструю память (например, SRAM) для промежуточных вычислений. Это достигается путем разделения матриц запросов (queries), ключей (keys) и значений (values) на небольшие блоки и выполнением операций внимания по этим блокам, что значительно снижает требования к пропускной способности памяти и ускоряет процесс вычислений. O(NS^2) — типичная сложность по памяти для стандартного внимания, в то время как FlashAttention стремится к линейной сложности по отношению к длине последовательности N.
Метод QK Norm повышает стабильность и производительность вычислений механизма внимания, особенно при работе с длинными последовательностями. Традиционный механизм внимания может испытывать проблемы с градиентами и численную нестабильность при увеличении длины последовательности. QK Norm нормализует векторы запросов (Q) и ключей (K) перед вычислением весов внимания, что помогает предотвратить взрыв или затухание градиентов. Нормализация выполняется путем деления Q и K на \sqrt{d}, где d — размерность векторов. Это приводит к более стабильным градиентам во время обучения и, как следствие, к улучшению производительности модели при обработке длинных последовательностей и снижению риска переполнения или потери значимости.
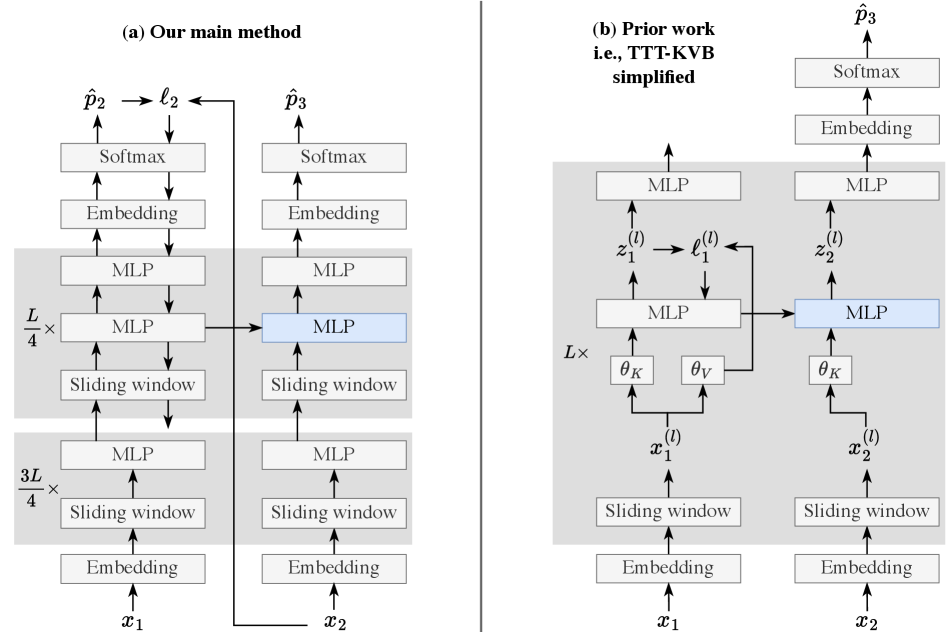
TTT-E2E: новый подход к моделированию длинного контекста
TTT-E2E представляет собой новый подход к моделированию длинных контекстов, основанный на применении обучения во время инференса (Test-Time Training, TTT). В отличие от традиционных методов, требующих предварительной настройки модели для конкретных задач, TTT-E2E позволяет модели динамически адаптироваться к особенностям входной последовательности непосредственно во время обработки данных. Этот процесс включает в себя небольшие корректировки параметров модели на основе входного контекста, что позволяет улучшить производительность и эффективность при работе с длинными последовательностями без необходимости переобучения всей модели. Такая адаптация позволяет TTT-E2E эффективно использовать ресурсы и поддерживать высокую производительность при увеличении длины контекста.
Метод TTT-E2E расширяет возможности архитектуры Transformer за счет динамической адаптации к специфическим характеристикам входной последовательности. В отличие от статических моделей, TTT-E2E использует процесс обучения во время инференса (Test-Time Training) для корректировки весов и параметров модели непосредственно на основе анализируемой последовательности. Это позволяет модели учитывать уникальные статистические свойства, структуру и зависимости конкретного входного текста, что повышает ее эффективность при обработке последовательностей различной длины и сложности. Адаптация происходит путем применения небольших обновлений весов, основанных на градиентах, вычисленных на основе входной последовательности, что позволяет модели оптимизировать свою работу для конкретной задачи без необходимости переобучения всей модели.
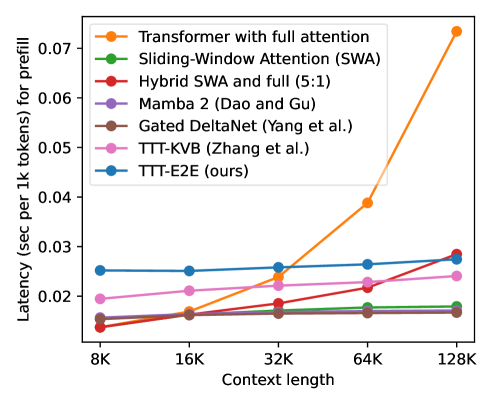
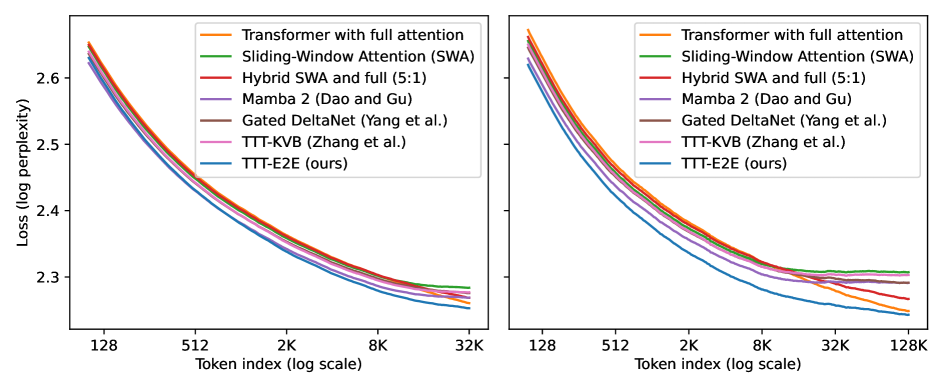
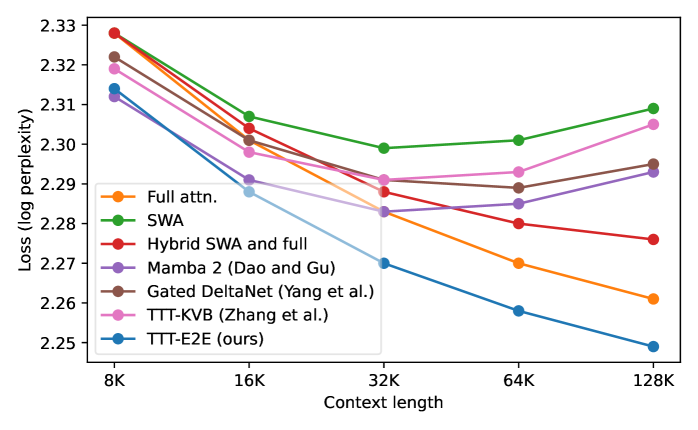
Метод TTT-E2E демонстрирует сопоставимую производительность с полной внимательностью (full attention) при длине контекста в 128К токенов. Результаты показывают сохранение паритета производительности с полной внимательностью, а также устойчивое функционирование при увеличении длины контекста сверх 128К токенов. Это означает, что TTT-E2E способен эффективно обрабатывать длинные последовательности данных без значительной потери точности по сравнению со стандартными механизмами внимания, что делает его перспективным для задач, требующих анализа больших объемов информации.
Оптимизация обучения и производительности: баланс ресурсов и качества
Для снижения потребления памяти в процессе обучения используется метод градиентного чекпоинтинга. Данная техника позволяет пересчитывать промежуточные активации нейронной сети по мере необходимости, а не хранить их все в памяти. Это особенно важно при работе с крупными моделями и длинными последовательностями данных, поскольку объем требуемой памяти может быстро стать непомерно большим. Применение градиентного чекпоинтинга открывает возможность обучения моделей с большим количеством параметров и обработки более длинных текстов, что в свою очередь способствует повышению качества генерируемого контента и расширению спектра решаемых задач. Данный подход является ключевым для эффективного использования вычислительных ресурсов и достижения оптимальной производительности при работе со сложными языковыми моделями.
Эффективное обучение больших языковых моделей требует тщательного баланса между объемом вычислительных ресурсов, затрачиваемых на тренировку, и желаемой длиной контекста. Недостаточное количество вычислений может привести к тому, что модель не сможет полностью усвоить информацию, содержащуюся в длинных последовательностях, что снизит ее производительность и точность. С другой стороны, чрезмерное использование вычислительных ресурсов при фиксированной длине контекста может привести к переобучению — ситуации, когда модель запоминает тренировочные данные, но плохо обобщает на новые, ранее не встречавшиеся примеры. Таким образом, оптимальный выбор длины контекста и объема вычислений позволяет максимально использовать потенциал модели, избегая как недоиспользования, так и переобучения, и обеспечивая высокую производительность и обобщающую способность.
Несмотря на то, что процесс обучения модели TTT-E2E при контекстном окне в 128 тысяч токенов оказывается на 20% медленнее, чем при использовании традиционного механизма внимания, она демонстрирует способность генерировать связный и логичный текст на протяжении всей этой длины. Важно отметить, что TTT-E2E эффективно решает проблему повторений, часто возникающую при работе с большими контекстными окнами, обеспечивая более качественный и последовательный вывод. Это достигается благодаря оптимизированной архитектуре и алгоритмам, позволяющим модели сохранять когерентность даже при обработке обширных объемов информации.
Будущие направления и широкие перспективы: эволюция интеллекта
Успешная реализация подхода TTT-E2E указывает на перспективный сдвиг в сторону создания моделей, способных к адаптации и динамическому обучению непосредственно в процессе инференса. В отличие от традиционных систем, фиксирующих знания после этапа обучения, такие модели демонстрируют возможность непрерывной эволюции, улучшая свою производительность на основе поступающих данных в реальном времени. Это открывает путь к созданию интеллектуальных систем, способных к более эффективному решению сложных задач в постоянно меняющихся условиях, а также к разработке принципиально новых подходов к машинному обучению, где обучение и применение происходят одновременно и взаимосвязано.
Перспективы развития технологии TTT (Trainable Task Transformer) простираются далеко за пределы текущих архитектур. Исследования, направленные на адаптацию TTT к таким инновационным моделям, как Mamba Architecture и Gated DeltaNet, представляются особенно плодотворными. Эти модели, обладающие уникальными свойствами обработки последовательностей, могут значительно расширить возможности TTT в решении сложных задач. Кроме того, исследование применения TTT к различным модальностям данных — от текста и изображений до аудио и видео — открывает путь к созданию универсальных систем искусственного интеллекта, способных эффективно взаимодействовать с окружающим миром и адаптироваться к разнообразным условиям. Такой подход позволит существенно повысить гибкость и эффективность моделей, сделав их более пригодными для решения реальных задач в различных областях.
Предложенный подход открывает захватывающие перспективы в различных областях. В сфере персонализированного обучения, модели, способные адаптироваться в процессе работы, могут создавать индивидуальные образовательные траектории, учитывающие уникальные потребности и прогресс каждого ученика. В задачах принятия решений в реальном времени, динамически обучающиеся системы позволят оперативно реагировать на меняющиеся условия и оптимизировать действия в сложных ситуациях. Наконец, в области генерации творческого контента, подобная адаптивность может привести к созданию более оригинальных и релевантных произведений, будь то текст, изображения или музыка, поскольку модель сможет учиться на обратной связи и совершенствовать свои навыки непосредственно в процессе создания.
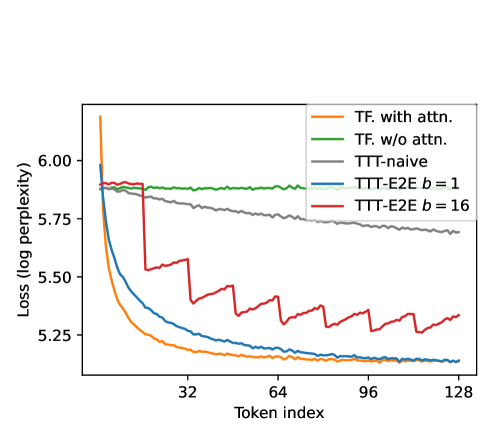
Работа демонстрирует, что стремление к созданию эффективных систем обработки длинных контекстов требует иного подхода, нежели простое масштабирование существующих архитектур. Авторы предлагают метод TTT-E2E, который, подобно живой системе, адаптируется к условиям среды, обновляя веса модели в процессе работы. Это напоминает о словах самого Тима Бернерса-Ли: «Веб никогда не был разработан как контролируемая система, а скорее как экосистема». Идея адаптации модели в реальном времени, используя градиенты-градиентов, позволяет системе самосовершенствоваться, подобно тому, как в природе эволюция находит оптимальные решения. По сути, это отказ от иллюзии полного контроля в пользу гибкости и саморегуляции, что соответствует принципу создания систем, способных к длительному и устойчивому функционированию.
Что Дальше?
Предложенный подход к адаптации моделей во время тестирования, безусловно, демонстрирует способность смягчить неизбежное столкновение с долгосрочными зависимостями в тексте. Однако, говорить о «решении» проблемы масштабируемости — наивно. Масштабируемость — это всего лишь слово, которым мы оправдываем усложнение. Каждый новый слой внимания, каждая оптимизация — это пророчество о будущем сбое, о точке, где гибкость будет принесена в жертву производительности.
Более того, сама идея «обучения во время тестирования» поднимает вопросы. Что, если адаптация к конкретному тексту лишь подчеркивает хрупкость полученных знаний? Что, если модель, оптимизированная для одного контекста, окажется бесполезной в ином? Идеальная архитектура — это миф, нужный, чтобы не сойти с ума, но за ним скрывается признание: мы строим не системы, а экосистемы, которые невозможно контролировать до конца.
Вероятно, будущее за исследованиями, направленными не на увеличение мощности моделей, а на их способность к саморефлексии, к оценке собственной неопределенности. Модель, способная признать границы своих знаний и адаптироваться к ним, будет ценнее любой, оптимизированной для достижения пиковой производительности. В конечном счете, речь идет не о том, чтобы построить идеальную систему, а о том, чтобы научиться с ней жить.
Оригинал статьи: https://arxiv.org/pdf/2512.23675.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Обучение декодированию квантовых кодов LDPC: новый подход
- Сеть, управляемая интеллектом: новые возможности для экспериментов
- Ускорение генерации текста: новый подход к спекулятивному декодированию
- Внимание к квантовой теории поля: нейросети и трансформеры
- Визуальный интеллект: обучение рассуждению через головоломки
- Искусственный интеллект в роли астрофизика: эксперимент с задачами
2025-12-31 15:21