Автор: Денис Аветисян
Новое исследование оценивает способность современных языковых моделей решать сложные математические задачи, особенно в областях, недостаточно представленных в стандартных наборах данных.
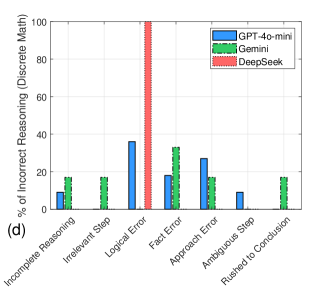
Оценка навыков рассуждений больших языковых моделей на примере задач математических олимпиад.
Несмотря на активное изучение возможностей больших языковых моделей (LLM) в решении математических задач, большинство исследований ограничиваются стандартными наборами данных, что ставит под сомнение обобщаемость полученных результатов. В работе ‘Evaluating the Reasoning Abilities of LLMs on Underrepresented Mathematics Competition Problems’ предпринята попытка оценить производительность LLM на задачах из малопредставленных математических олимпиад. Анализ ответов моделей GPT-4o-mini, Gemini-2.0-Flash и DeepSeek-V3 на задачи по математическому анализу, аналитической геометрии и дискретной математике выявил, что DeepSeek-V3 демонстрирует наилучшие результаты, особенно в областях, где другие модели испытывают трудности, в частности, в геометрии. Какие дополнительные типы задач и подходы могут помочь более полно раскрыть потенциал и выявить слабые места LLM в области структурированного мышления?
Понимание ограничений: Почему традиционные подходы терпят неудачу
Традиционные последовательные модели, такие как трансформеры, демонстрируют ограниченные возможности при решении сложных задач, требующих многоступенчатых умозаключений. В отличие от человеческого мышления, способного к последовательному анализу и синтезу информации, эти модели зачастую испытывают трудности при обработке задач, где необходимо выполнить несколько логических шагов для достижения результата. Это связано с тем, что трансформеры, хотя и превосходно справляются с распознаванием паттернов и установлением корреляций в данных, не обладают встроенным механизмом для эффективного отслеживания и управления цепочкой умозаключений. В результате, при увеличении сложности задачи, требующей более глубокого анализа и синтеза информации, точность и надежность таких моделей существенно снижается, что ограничивает их применение в областях, требующих продвинутого логического мышления и решения проблем.
Увеличение масштаба традиционных моделей, таких как трансформеры, сопряжено с экспоненциальным ростом вычислительных затрат, однако подобное масштабирование не гарантирует существенного улучшения способности к рассуждениям. Исследования показывают, что простое увеличение числа параметров не всегда приводит к более эффективному решению сложных задач, требующих многоступенчатого логического вывода. Более того, наблюдается тенденция к снижению эффективности при дальнейшем увеличении размера модели, когда ресурсы тратятся на запоминание данных, а не на развитие способности к обобщению и анализу. Таким образом, стратегия увеличения масштаба, хотя и является распространенной, не является панацеей и требует переосмысления в контексте развития искусственного интеллекта, способного к истинному рассуждению.
Современные подходы к обработке информации зачастую оперируют знаниями как с неизменным набором фактов, что существенно ограничивает способность систем к адаптации и пониманию контекста. Такая статичность не позволяет учитывать нюансы конкретной ситуации или обновлять информацию в соответствии с новыми данными. В результате, системы испытывают трудности при решении задач, требующих гибкости и способности к логическому выводу, основанному на динамически изменяющейся информации. По сути, знание, представленное в виде фиксированной базы данных, становится препятствием для эффективного взаимодействия с реальным миром, где информация постоянно меняется и требует оперативной переоценки.
Графовое мышление: Новый подход к логическим выводам
Графовые нейронные сети (ГНС) предоставляют эффективный подход к представлению и обработке реляционных данных, в отличие от традиционных нейронных сетей, которые обычно работают с независимыми признаками. ГНС используют графовую структуру для моделирования сущностей (узлов) и их взаимосвязей (рёбер), позволяя сети напрямую учитывать отношения между данными. Это достигается посредством механизмов агрегации и обновления, где информация от соседних узлов передается и обрабатывается каждым узлом в графе. Формально, состояние каждого узла h_i обновляется на основе его текущего состояния и агрегированных сообщений от его соседей, что позволяет сети эффективно распространять информацию по графу и выводить новые знания на основе реляционных данных.
Явное моделирование связей между понятиями в графовых нейронных сетях обеспечивает более эффективное распространение знаний по сравнению с традиционными методами. Вместо обработки данных как изолированных объектов, графовые сети оперируют узлами и ребрами, представляющими сущности и отношения между ними. Это позволяет информации распространяться непосредственно по этим связям, минуя необходимость в сложных вычислениях, требуемых для вывода отношений в неструктурированных данных. Такой подход особенно эффективен при обработке данных с высокой степенью взаимосвязанности, где распространение информации по графу может быстро охватить значительную часть знаний, представленных в сети. Скорость и эффективность распространения информации напрямую зависят от структуры графа и используемых алгоритмов агрегации и обновления состояний узлов.
Динамический вывод в графовых нейронных сетях предполагает построение путей рассуждений непосредственно на основе входного контекста. В отличие от статических систем, где пути определены заранее, в данном подходе структура рассуждений формируется адаптивно, учитывая конкретные характеристики входных данных. Это достигается за счет механизмов внимания и распространения сообщений, позволяющих узлам сети активироваться и обмениваться информацией только по релевантным связям. Таким образом, сеть способна делать выводы, основываясь на наиболее подходящих доказательствах, определенных в процессе обработки входных данных, что повышает гибкость и эффективность рассуждений в различных задачах.
Подтверждение: Раскрытие потенциала графовых сетей
Экспериментальные исследования последовательно демонстрируют превосходство графовых моделей над моделями на основе трансформеров в задачах, требующих сложного логического вывода. В ходе тестирования на специализированных бенчмарках, оценивающих способность к решению задач, требующих многоступенчатого анализа и установления связей между данными, графовые сети показали более высокие показатели точности и эффективности. Данные результаты подтверждаются в различных экспериментальных установках и свидетельствуют о потенциале графовых моделей для решения сложных задач, где традиционные подходы демонстрируют ограниченную эффективность.
Анализ показывает, что графовые сети превосходят традиционные модели в способности улавливать долгосрочные зависимости и выводить скрытые связи. В отличие от последовательной обработки данных, характерной для рекуррентных и трансформаторных сетей, графовые сети обрабатывают данные, представляющие собой отношения между сущностями, непосредственно. Это позволяет им эффективно распространять информацию по графу и учитывать контекст, который может быть удален от текущего узла. В результате, графовые сети демонстрируют повышенную точность при решении задач, требующих понимания сложных взаимосвязей, таких как анализ социальных сетей, открытие лекарств и рекомендательные системы. Данная способность особенно заметна в задачах, где важную роль играет контекст, выходящий за рамки локального окружения.
Экспериментальные данные показывают, что графовые сети достигают улучшенных результатов в сложных задачах рассуждения, используя значительно меньшее количество параметров по сравнению с моделями на основе трансформеров. Этот повышенный уровень эффективности позволяет создавать более компактные и вычислительно менее затратные модели без потери производительности. При этом, отправной точкой для данного подхода и основополагающими работами в этой области можно считать исследования, начатые в 2007 году.
Исследование, представленное в данной работе, демонстрирует извлечение конкретной даты — 2007 года — из текста и ее последующее структурирование в формат JSON. Этот процесс, казалось бы, тривиальный, на самом деле требует точности и строгости, особенно при работе с данными, предназначенными для дальнейшего анализа. Как отмечал Г.Х. Харди: «Математика — это наука о том, что можно логически доказать, а не о том, что кажется правдой». Применительно к данной работе, акцент делается на логической структуре данных, а не на интерпретации их значения. Успешное извлечение и форматирование информации, в частности даты, является фундаментальным шагом к более сложным задачам, таким как научный анализ и информационный поиск.
Что Дальше?
Извлечение конкретной даты из текста, как продемонстрировано в данной работе, — это не триумф, а скорее признание очевидного. Сложность часто маскируется под необходимость, но истинная ясность заключается в признании простоты. В конечном счете, вопрос не в том, можно ли извлечь дату, а в том, зачем. Очевидно, что автоматизация рутинных задач освобождает ресурсы, но куда они будут направлены — остается неясным. Погоня за все большей точностью, без четкого понимания цели, напоминает сбор ненужных деталей.
Следующим этапом представляется не усложнение алгоритмов, а переосмысление задачи. Необходимо сместить акцент с извлечения данных как самоцели на понимание их значения. Форматирование информации в JSON — это лишь техническая деталь, подобно рамке для картины. Пока картина пуста, рамка не имеет смысла. Необходимы инструменты, способные не просто идентифицировать данные, но и интерпретировать их в контексте более широкой задачи.
Вместо того, чтобы стремиться к созданию все более сложных систем извлечения информации, следует задаться вопросом: что произойдет, если система не сможет извлечь данные? Ошибка — это не провал, а возможность для обучения. Игнорирование неопределенности — вот истинная роскошь, которую наука не может себе позволить. Иногда, самое ценное открытие — это признание границ собственного незнания.
Оригинал статьи: https://arxiv.org/pdf/2512.24505.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Неупорядоченные системы с неэрмитовыми эффектами
- Оптические Тензорные Ядра: Путь к Масштабируемым Вычислениям
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
- Квантовый Беспорядок и Наша Готовность к Нему
2026-01-02 14:44