Автор: Денис Аветисян
Исследователи представили инновационную архитектуру памяти, сочетающую в себе высокую емкость и способность к адаптации для эффективной обработки длинных последовательностей и улучшения эпизодической памяти.
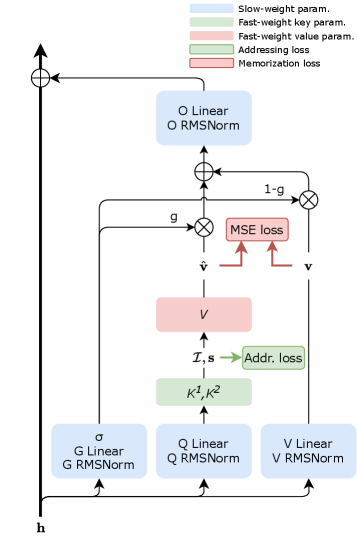
Fast-weight Product Key Memory (FwPKM) объединяет разреженную память и адаптивные веса для повышения производительности в задачах долгосрочного моделирования и обучения во время тестирования.
Современные языковые модели часто сталкиваются с компромиссом между объемом памяти и вычислительной эффективностью. В данной работе представлена архитектура ‘Fast-weight Product Key Memory’ (FwPKM), динамическая эпизодическая память, преобразующая разреженную Product Key Memory посредством “быстрых весов”. FwPKM обеспечивает адаптивное запоминание и извлечение пар ключ-значение непосредственно во время обучения и работы, сочетая высокую емкость с возможностью обучения в реальном времени. Эксперименты демонстрируют, что FwPKM эффективно дополняет семантическую память стандартных модулей, улучшая работу с длинными последовательностями и позволяя обобщать на контексты до 128К токенов, даже при обучении на данных в 4К токенов — как можно расширить возможности моделирования длинных последовательностей с помощью подобных адаптивных механизмов памяти?
Ограничения внимания: Цена масштабируемости в современных моделях
Современные архитектуры Transformer, несмотря на свою впечатляющую эффективность в различных задачах, сталкиваются с серьезными ограничениями масштабируемости. Проблема заключается в том, что вычислительная сложность обработки последовательностей растет квадратично с увеличением их длины. Это означает, что для удвоения длины обрабатываемого текста требуются не просто вдвое больше вычислительных ресурсов, а в четыре раза. O(n^2) — такая зависимость быстро делает обработку длинных текстов, например, объемных научных статей или книг, непозволительно дорогой и трудоемкой. Данное ограничение препятствует созданию моделей, способных эффективно анализировать и использовать информацию из действительно больших контекстов, что критически важно для решения сложных задач, требующих понимания долгосрочных зависимостей.
Ограничение масштабируемости современных архитектур, таких как Transformer, существенно влияет на способность искусственного интеллекта к обработке долгосрочных зависимостей — ключевого элемента сложных задач рассуждения. В частности, при анализе больших объемов информации, система сталкивается с трудностями в установлении связей между отдаленными друг от друга элементами, что критически важно для понимания контекста и принятия обоснованных решений. Например, в задачах, требующих анализа длинных текстов или последовательностей данных, невозможность эффективно учитывать все предшествующие события приводит к упрощенным или ошибочным выводам. Данное ограничение не просто снижает точность, но и препятствует созданию действительно интеллектуальных систем, способных к глубокому и всестороннему анализу информации, аналогичному человеческому мышлению.
Существенная проблема современных моделей искусственного интеллекта, особенно при работе с большими объемами данных, заключается в эффективном извлечении и использовании релевантной информации из потенциально неограниченного контекста. Вместо того чтобы анализировать всю последовательность данных, что требует огромных вычислительных ресурсов, требуется механизм, позволяющий модели фокусироваться исключительно на наиболее важных элементах. Это не просто вопрос скорости обработки, но и точности: чрезмерное внимание к несущественным деталям может привести к ошибочным выводам. Разработка таких механизмов, способных к избирательному вниманию и эффективному управлению контекстом, является ключевой задачей для создания более интеллектуальных и масштабируемых систем искусственного интеллекта, способных к глубокому пониманию и сложным рассуждениям.
Ассоциативная память: Вдохновленные биологией альтернативы
Ассоциативная память представляет собой альтернативный подход к извлечению информации, отличный от традиционных методов, основанных на адресации по позиции. В отличие от адресной памяти, где доступ к данным осуществляется через конкретное местоположение, в ассоциативной памяти поиск осуществляется по содержанию. Это означает, что информация извлекается на основе сходства с запросом, а не по заранее известному адресу. Данный принцип позволяет осуществлять нечеткий поиск и устойчив к частичным или неточным запросам, поскольку система способна находить данные, наиболее близкие по содержанию к заданному критерию. Технологически это реализуется за счет хранения данных в виде пар “ключ-значение”, где ключ представляет собой содержание, а значение — соответствующую информацию.
В отличие от архитектуры Transformer, которая сталкивается с ограничениями по длине контекста из-за квадратичной сложности вычислений внимания, ассоциативная память не имеет принципиальных ограничений на длину входной последовательности. Это связано с тем, что информация в ассоциативной памяти извлекается по содержанию, а не по позиции, что позволяет хранить и извлекать данные из неограниченного объема памяти. Вместо последовательной обработки, как в Transformer, ассоциативная память может параллельно сравнивать входные данные со всеми сохраненными элементами, обеспечивая потенциально неограниченное хранилище и доступ к информации без существенного увеличения вычислительной сложности при увеличении объема данных.
Принципы ассоциативной памяти вдохновлены способностью человеческого мозга к быстрому доступу и интеграции информации из обширных хранилищ знаний. Нейронные сети мозга не хранят данные в строгой последовательности, а организуют их по ассоциациям, позволяя активировать связанные концепции даже при неполном или зашумленном входном сигнале. Этот механизм, основанный на синаптической пластичности и формировании нейронных ансамблей, обеспечивает эффективное извлечение релевантной информации, минуя необходимость последовательного поиска по всей базе данных. В отличие от традиционных вычислительных систем, где доступ к данным зависит от адреса, мозг использует контент-адресацию, позволяя активировать связанные воспоминания и знания на основе их семантической близости.
Линейное внимание: Эффективный поиск с ассоциативной памятью
Механизмы линейного внимания обеспечивают возможность эффективного ассоциативного поиска, снижая вычислительную сложность с квадратичной (O(n^2)) до линейной (O(n)). Традиционные механизмы внимания требуют вычисления внимания между каждой парой элементов в последовательности, что приводит к квадратичной зависимости от длины последовательности n. Линейное внимание приближает вычисления, используя разложение на векторы запроса, ключа и значения для достижения линейной сложности. Это позволяет обрабатывать значительно более длинные последовательности данных при сохранении приемлемой производительности, что особенно важно для задач, требующих анализа больших объемов информации, таких как обработка естественного языка и анализ временных рядов.
Механизмы линейного внимания позволяют ускорить обработку длинных последовательностей за счет приближения вычислений, выполняемых в механизмах полного внимания. Традиционное полное внимание требует O(n^2) операций, где n — длина последовательности, что становится узким местом при работе с большими объемами данных. Линейное внимание снижает вычислительную сложность до O(n), приближая матрицу внимания с помощью разложения на более простые операции, такие как произведения матриц меньшего размера. Несмотря на упрощение вычислений, современные реализации линейного внимания демонстрируют незначительную потерю производительности по сравнению с полным вниманием, сохраняя при этом значительное преимущество в скорости обработки.
Реализация данной системы использует принципы ассоциативной памяти для эффективного доступа к контексту. В ходе тестирования, продемонстрирована точность более 70% по метрике NIAH (Normalized Information Access Hit rate) всего за 2 итерации при работе с контекстами длиной 4K. Это свидетельствует о способности системы быстро и эффективно извлекать релевантную информацию из больших объемов данных, приближаясь к производительности традиционных методов, но с существенно меньшими вычислительными затратами.
Динамическая адаптация: Быстрые веса для эффективного вывода
В современных нейронных сетях, способность адаптироваться к новым данным без дорогостоящей переподготовки является ключевой задачей. В отличие от традиционных моделей с фиксированными параметрами, использование “быстрых весов” позволяет сети динамически изменять свои параметры непосредственно во время обработки входных данных. Этот подход существенно снижает потребность в постоянной перенастройке модели при появлении новых, ранее не встречавшихся данных, обеспечивая более гибкую и эффективную работу. Механизм быстрых весов позволяет модели “учиться на лету”, моментально приспосабливаясь к контексту и повышая точность прогнозирования без изменения основных параметров сети. Такой подход открывает возможности для создания самообучающихся систем, способных оперативно реагировать на изменения в окружающей среде и решать сложные задачи в реальном времени.
Динамические параметры, позволяющие модели адаптироваться к новым входным данным в режиме реального времени, эффективно вычисляются с использованием базовой архитектуры SwiGLU MLP. Такой подход обеспечивает практичную и вычислительно эффективную стратегию реализации, избегая необходимости в сложных или ресурсоемких операциях. SwiGLU, как разновидность многослойного персептрона, позволяет быстро и точно генерировать эти “быстрые веса”, что делает возможным адаптивное поведение модели без значительного увеличения времени отклика или потребления памяти. Эта архитектура демонстрирует оптимальный баланс между выразительностью и вычислительной сложностью, что делает её привлекательным решением для приложений, требующих динамической адаптации и эффективной обработки данных.
Разработанная система, объединяющая динамические веса с принципами ассоциативной памяти, продемонстрировала способность к обобщению на последовательностях длиной до 128 000 токенов — контекст, при котором производительность традиционных моделей существенно снижается. В ходе экспериментов на наборе данных LAMBADA, новая архитектура показала улучшенную метрику перплексии, что свидетельствует о более эффективном моделировании языковых закономерностей и способности к предсказанию следующих токенов в длинных текстах. Такой подход позволяет преодолеть ограничения, связанные с фиксированным размером контекстного окна, и открывает возможности для обработки и анализа значительно больших объемов текстовой информации.
Предложенная архитектура Fast-weight Product Key Memory (FwPKM) стремится к элегантности, отказываясь от избыточности в пользу четкой функциональности. Она объединяет возможности адаптивных весов и разреженной памяти, создавая систему, способную эффективно обрабатывать длинные контексты и улучшать работу эпизодической памяти. Тим Бернерс-Ли однажды сказал: «Интернет — это для всех». Подобно этой идее, FwPKM стремится к универсальности и эффективности, предоставляя доступ к информации из прошлого, чтобы лучше понимать настоящее, что соответствует ключевому принципу — простота и ясность, достигаемые путем исключения ненужных сложностей. В конечном счете, подобно отточенному коду, система должна быть понятна и предсказуема.
Куда же дальше?
Предложенная архитектура, с ее сочетанием разреженной памяти и «быстрых весов», несомненно, представляет интерес. Однако, не стоит обольщаться — это лишь еще один строительный блок. Они назвали это «фреймворком», чтобы скрыть панику, вызванную истинным масштабом задачи моделирования долгосрочной памяти. Главный вопрос, который остается открытым, заключается не в увеличении емкости, а в умении отсеивать действительно значимое. Эффективность работы с контекстом, без потери способности к обобщению, — вот что должно волновать исследователей.
Очевидно, что дальнейшее исследование должно быть направлено на разработку более изящных механизмов внимания и фильтрации. Слишком часто наблюдается стремление к усложнению, к добавлению все новых и новых слоев абстракции. Но зрелость, как показывает опыт, заключается в простоте. Необходимо сосредоточиться на поиске минимально достаточного набора операций, способных обеспечить необходимую функциональность.
В конечном итоге, истинным критерием успеха станет не количество параметров или терабайты обработанных данных, а способность модели к адаптации и обучению в реальном времени, в условиях неполной и противоречивой информации. Простое накопление опыта — это еще не память. Истинная память — это умение извлекать уроки из прошлого, чтобы принимать более взвешенные решения в настоящем.
Оригинал статьи: https://arxiv.org/pdf/2601.00671.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Когда мнения расходятся: как модели принимают решения при конфликте данных
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Шёпот языков: как дрессировать цифрового голема для забытых наречий.
- Взгляд в будущее: как теория динамических систем преобразит анализ временных рядов
- Наука больших команд и широких горизонтов
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Переключение намагниченности в квантовых антиферромагнетиках: новые горизонты для терагерцовой спинтроники
- Оптимизация больших языковых моделей: новый подход к снижению требований к ресурсам
- Самоуправляемая защита ИИ: Экосистема PBSAI
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2026-01-05 15:10