Автор: Денис Аветисян
Исследователи представили Light Forcing — инновационную систему разреженного внимания, позволяющую создавать высококачественные видеоролики значительно быстрее и эффективнее.
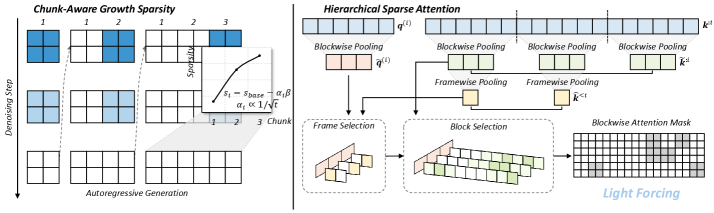
Разработанный фреймворк Light Forcing использует разреженное внимание и chunk-aware growth для ускорения авторегрессивной генерации видео, достигая state-of-the-art результатов и обеспечивая возможность синтеза видео в реальном времени на потребительском оборудовании.
Несмотря на значительный прогресс в генерации видео, авторегрессионные модели остаются вычислительно затратными из-за квадратичной сложности механизма внимания. В работе ‘Light Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention’ предложен новый подход, позволяющий ускорить генерацию видео посредством разреженного внимания, адаптированного специально для авторегрессионных моделей. Ключевым нововведением является механизм ‘Chunk-Aware Growth’, который позволяет эффективно распределять разреженность внимания, сохраняя и передавая информацию из ранее сгенерированных фрагментов, а также иерархическое разреженное внимание для захвата контекста на разных уровнях детализации. Возможно ли дальнейшее повышение эффективности и качества генерации видео за счет интеграции предложенного подхода с новыми методами квантования и оптимизации архитектур нейронных сетей?
Задача согласованности видео: вызовы и ограничения
Создание видео высокой четкости с сохранением временной согласованности представляет собой серьезную задачу, поскольку существующие методы часто испытывают трудности с установлением связей между удаленными друг от друга кадрами. Неспособность улавливать и поддерживать эти долгосрочные зависимости приводит к визуальным артефактам и несогласованностям, особенно в динамичных сценах. В частности, предсказание будущих кадров на основе предыдущих требует от алгоритмов понимания не только непосредственной последовательности событий, но и общей сюжетной линии и контекста, что требует значительных вычислительных ресурсов и сложных моделей. Эта проблема ограничивает реалистичность и правдоподобность генерируемых видеороликов, препятствуя их использованию в приложениях, требующих высокой степени визуальной достоверности и согласованности.
Авторегрессивные подходы к генерации видео, несмотря на свою перспективность, сталкиваются с проблемой кумулятивной ошибки, известной как накопление ошибок. Суть явления заключается в том, что каждая последующая часть генерируемого видео строится на основе предыдущей, и любая неточность, возникшая на раннем этапе, усугубляется с каждым новым кадром. Таким образом, даже небольшие погрешности в начальных фазах генерации могут привести к значительному снижению качества и реалистичности видеоролика по мере увеличения его длительности. Это ограничивает возможность создания длинных и правдоподобных видео, препятствуя их использованию в сложных сценариях, требующих высокой степени детализации и последовательности.
Ограничение длительности и реалистичности генерируемых видео, вызванное накоплением ошибок, существенно препятствует их использованию в сложных сценариях. Неспособность поддерживать временную согласованность на протяжении длительных последовательностей приводит к визуальным артефактам и потере правдоподобия, что делает сгенерированные видео непригодными для таких задач, как создание детализированных симуляций, реалистичная анимация или генерация обучающих материалов. В частности, для приложений, требующих прогнозирования будущих кадров или моделирования динамических процессов, даже незначительные ошибки могут быстро нарастать, приводя к полному искажению результата и снижая доверие к системе. Таким образом, преодоление этих ограничений является ключевым шагом к созданию действительно полезных и убедительных видео, генерируемых искусственным интеллектом.
Для преодоления сложностей, связанных с генерацией когерентных видео, необходимы принципиально новые подходы, направленные на поддержание временной согласованности и предотвращение распространения ошибок. Исследования в этой области акцентируют внимание на разработке архитектур, способных учитывать долгосрочные зависимости между кадрами, а также на применении методов, снижающих кумулятивное влияние погрешностей. Перспективными направлениями являются использование механизмов внимания, позволяющих модели фокусироваться на ключевых элементах предыдущих кадров, и внедрение процедур коррекции ошибок, эффективно устраняющих неточности на ранних стадиях генерации. Успешная реализация этих инноваций позволит создавать более реалистичные и продолжительные видео, открывая новые возможности для применения в различных сферах, от развлечений до научных исследований.

Стабилизация генерации с помощью передовых архитектур
Авторегрессионные диффузионные модели для видео обеспечивают мощную основу для генерации, однако подвержены накоплению ошибок в процессе последовательного предсказания кадров. Поскольку каждая новая генерация зависит от предыдущей, небольшие неточности на ранних этапах могут усиливаться и приводить к значительным артефактам и потере когерентности в более поздних кадрах. Это требует применения методов оптимизации, направленных на снижение скорости накопления ошибок и поддержание стабильности генерации видео на протяжении всей последовательности. Использование оптимизаторов, коррекция входных данных и архитектурные улучшения являются ключевыми подходами к решению данной проблемы.
Диффузионные Трансформеры (DiT) представляют собой значительный прогресс в области генерации видео, поскольку используют механизм двунаправленного внимания (bidirectional attention). В отличие от традиционных авторегрессионных моделей, которые обрабатывают данные последовательно, DiT анализирует всю временную последовательность одновременно. Это позволяет модели учитывать контекст как из прошлого, так и из будущего, что существенно улучшает временную согласованность генерируемого видео и снижает накопление ошибок. Механизм двунаправленного внимания позволяет DiT устанавливать зависимости между кадрами на значительном расстоянии, обеспечивая более плавные и реалистичные переходы и предотвращая артефакты, возникающие при последовательной генерации. Использование внимания позволяет эффективно обрабатывать длинные последовательности, избегая проблем с затуханием градиента, характерных для рекуррентных нейронных сетей.
Для повышения стабильности моделей генерации видео, таких как диффузионные модели, применяются постобучающие парадигмы, в частности, Self-Forcing. Данный подход предназначен для коррекции накапливающихся ошибок, возникающих в процессе генерации длинных последовательностей, и поддержания когерентности видеоряда. Self-Forcing заключается в обучении модели предсказывать и исправлять собственные ошибки на основе анализа сгенерированных кадров, что позволяет минимизировать дрифт и улучшить визуальную согласованность. Эффективность Self-Forcing проявляется в снижении артефактов и повышении реалистичности генерируемого контента при увеличении длительности видео.
Модели, такие как LongLive, используют принципы, разработанные для стабилизации генеративных моделей, включая диффузионные трансформаторы и методы пост-обучения, для достижения увеличенной длительности генерации видео и повышения динамической реалистичности. LongLive применяет архитектуру, позволяющую последовательно генерировать большее количество кадров без существенной потери когерентности и качества. Достигается это за счет оптимизации процессов распространения шума и восстановления изображения, а также использования механизмов, корректирующих накапливающиеся ошибки в процессе генерации, что позволяет создавать более продолжительные и визуально правдоподобные видеоролики.
Повышение эффективности за счет оптимизированного внимания
Механизмы разреженного внимания (Sparse Attention) позволяют значительно снизить вычислительные затраты за счет избирательного внимания к релевантным токенам. В отличие от традиционного плотного внимания, которое обрабатывает все пары токенов, разреженное внимание фокусируется только на подмножестве наиболее значимых связей. Это достигается различными методами, такими как фиксированные паттерны разреженности или динамическое определение релевантных токенов. Снижение вычислительной сложности особенно важно при работе с длинными последовательностями, типичными для задач обработки естественного языка и анализа видео, и является ключевым фактором для масштабирования моделей до больших размеров и объемов данных.
Механизмы FlashAttention и FlashAttention 2 оптимизируют вычисление внимания за счет использования техники разбиения на блоки (tiling) и перевычисления (recomputation). Разбиение на блоки позволяет обрабатывать большие матрицы внимания порциями, снижая потребность в памяти и повышая скорость вычислений. Перевычисление позволяет отложить некоторые вычисления до момента, когда они действительно необходимы, избегая хранения промежуточных результатов и дополнительно экономя память. Данный подход значительно ускоряет процесс обучения и инференса моделей, особенно при работе с длинными последовательностями данных, и является ключевым фактором повышения эффективности обработки больших объемов информации.
Оптимизации, такие как разреженное внимание и FlashAttention, критически важны для эффективного обучения и развертывания масштабных моделей генерации видео. Требования к вычислительным ресурсам и памяти при обработке видеоданных экспоненциально возрастают с увеличением разрешения и длительности генерируемых последовательностей. Эти методы позволяют существенно снизить вычислительную сложность механизма внимания, что напрямую влияет на скорость обучения и возможность развертывания моделей на доступном оборудовании. Без данных оптимизаций, обучение и инференс моделей генерации видео высокого разрешения становятся практически невозможными из-за чрезмерных требований к ресурсам.
Эффективность предложенных оптимизаций механизма внимания была количественно оценена с использованием бенчмарка VBench. Результаты показали, что разработанный подход достиг общего балла VBench в 84.5, что незначительно превосходит показатель плотного (dense) FlashAttention, составивший 84.1. Данное превышение подтверждает эффективность оптимизаций в снижении вычислительных затрат и повышении скорости обработки данных при работе с большими моделями, в частности, при генерации видео.
Тонкая настройка для производительности и реализма
Методы низкобитовой квантизации позволяют существенно уменьшить размер и объем памяти, занимаемые моделями, практически не снижая при этом качество генерируемого видео. В основе этих техник лежит представление весов и активаций нейронной сети с использованием меньшего числа битов, чем обычно. Например, переход от 32-битных чисел с плавающей точкой к 8-битным целым числам может снизить потребление памяти в четыре раза. Несмотря на снижение точности представления данных, продуманные алгоритмы квантизации минимизируют потерю информации, сохраняя ключевые особенности и детали в генерируемом видео, что делает возможным развертывание сложных моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые системы.
Сочетание квантования с оптимизированными механизмами внимания и методами регуляризации, в частности, использованием TV-loss (Total Variation loss), позволяет достичь высокой эффективности и реалистичности при генерации видео. Квантование снижает вычислительные затраты и объем памяти, необходимые для работы модели, а оптимизация внимания ускоряет обработку последовательностей. В свою очередь, регуляризация с помощью TV-loss способствует уменьшению шумов и артефактов, улучшая визуальное качество генерируемого видео. Такой комплексный подход позволяет создавать модели, способные генерировать реалистичные видеоролики с минимальными ресурсами, открывая возможности для их применения на устройствах с ограниченной вычислительной мощностью и обеспечения генерации видео в реальном времени.
Для стабилизации процесса генерации видео и повышения качества получаемых результатов активно используется регуляризация на основе дивергенции Кульбака-Лейблера (KL-дивергенции). Этот метод позволяет контролировать отклонение распределения вероятностей, генерируемого моделью, от желаемого, что особенно важно для предотвращения нестабильности и артефактов в сгенерированных видео. KL-дивергенция эффективно сглаживает процесс обучения, заставляя модель избегать экстремальных или нереалистичных состояний, и тем самым улучшает согласованность и визуальное качество видеоматериалов. Благодаря применению KL-дивергенции, модель становится более устойчивой к шуму и вариациям во входных данных, что приводит к более предсказуемым и реалистичным результатам генерации.
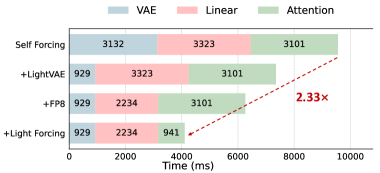
Сочетание оптимизаций позволило значительно расширить возможности развертывания моделей генерации видео на устройствах с ограниченными ресурсами. Достигнута возможность генерации видео в режиме реального времени — со скоростью 19.7 кадров в секунду на графическом процессоре RTX 5090. Общее ускорение работы модели составило 2.33 раза, а ускорение работы механизма внимания — 3.29 раза. Эти улучшения открывают перспективы для применения высококачественной генерации видео на мобильных устройствах и других платформах, где вычислительные мощности ограничены, делая передовые технологии генерации контента более доступными и эффективными.
Исследование, представленное в данной работе, демонстрирует стремление к пониманию закономерностей в генерации видео, используя подход, основанный на разреженном внимании. Авторы фокусируются на оптимизации процесса, чтобы достичь не только высокого качества генерируемого видео, но и эффективности, позволяющей запускать модели на потребительском оборудовании. Как однажды заметил Ян ЛеКун: «Машинное обучение — это не магия, а инженерия». Этот принцип явно прослеживается в Light Forcing, где инновации в разреженном внимании и иерархической структуре внимания направлены на инженерное решение сложной задачи — генерации реалистичного видео в реальном времени. Работа демонстрирует, что даже сложные системы могут быть оптимизированы, если глубоко понимать лежащие в их основе принципы.
Что дальше?
Представленная работа, безусловно, демонстрирует значительный прогресс в области авторегрессивной генерации видео, но истинный исследователь всегда видит больше вопросов, чем ответов. Эффективность разреженной матрицы внимания, особенно в контексте «Chunk-Aware Growth», поднимает вопрос о более глубоком понимании оптимальных стратегий сегментации временных рядов. Возможно ли создание универсальной схемы, адаптирующейся к различным типам видеоконтента и динамике движения?
Ограничения текущих диффузионных моделей, связанные с вычислительными затратами и требованиями к памяти, остаются существенной проблемой. Хотя «Light Forcing» и приближает возможность генерации видео в реальном времени на потребительском оборудовании, вопрос о масштабируемости до более высоких разрешений и частот кадров остаётся открытым. Необходимо исследовать альтернативные архитектуры и методы оптимизации, возможно, вдохновлённые принципами работы человеческого зрительного восприятия.
В конечном счете, успех в этой области не измеряется только скоростью и качеством генерации. Истинная цель — это создание систем, способных к осмысленному моделированию временных зависимостей и генерации видео, которые не просто реалистичны, но и обладают внутренней логикой и повествовательной структурой. Понимание этих закономерностей — вот истинный вызов для исследователя.
Оригинал статьи: https://arxiv.org/pdf/2602.04789.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Поймать Мгновение: Эволюция Детекторов Времени
- Мгновенная расшифровка: Voxtral Realtime на службе у скорости
2026-02-08 20:22