Автор: Денис Аветисян
В статье рассматривается опыт создания корпоративной системы федеративного обучения, позволяющей использовать данные из разных источников для научных исследований, сохраняя при этом конфиденциальность.
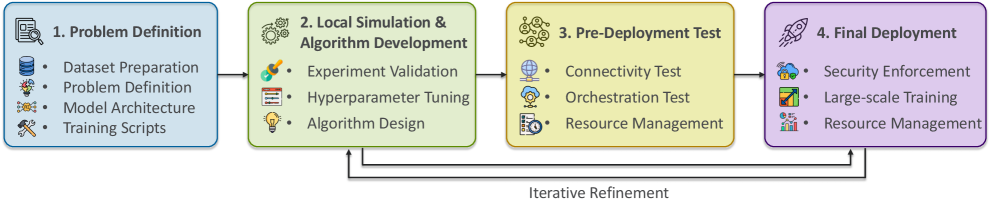
Предлагается архитектура масштабируемой и безопасной системы федеративного обучения для научных приложений с возможностью перехода от моделирования к реальному развертыванию.
Несмотря на растущий интерес к обучению с федеративным обучением (FL) как к средству сохранения конфиденциальности данных, создание масштабируемых и безопасных систем для научных вычислений остается сложной задачей. В статье ‘Experiences Building Enterprise-Level Privacy-Preserving Federated Learning to Power AI for Science’ представлен опыт разработки платформы APPFL и сформулировано видение корпоративного решения для FL, способного бесшовно переходить от прототипирования к развертыванию в гетерогенных вычислительных средах. Предлагаемая архитектура обеспечивает масштабируемость, безопасность и гибкость за счет многоуровневых абстракций и интеграции методов дифференциальной приватности и безопасной агрегации. Сможет ли эта платформа преодолеть разрыв между исследовательскими прототипами и масштабными научными приложениями, открывая новые возможности для совместного анализа данных?
Эволюция Совместного Обучения
Традиционное централизованное машинное обучение сталкивается с проблемами конфиденциальности и логистики при консолидации данных, особенно когда данные изначально распределены между участниками. Федеративное обучение (FL) позволяет обучать модели на децентрализованных данных, сохраняя конфиденциальность. Предлагаемый подход направлен на создание унифицированной платформы Federated Learning as a Service (FLaaS), предоставляющей веб-интерфейс для настройки клиентов, управления экспериментами, мониторинга и аналитики, работающей с разнородными устройствами.
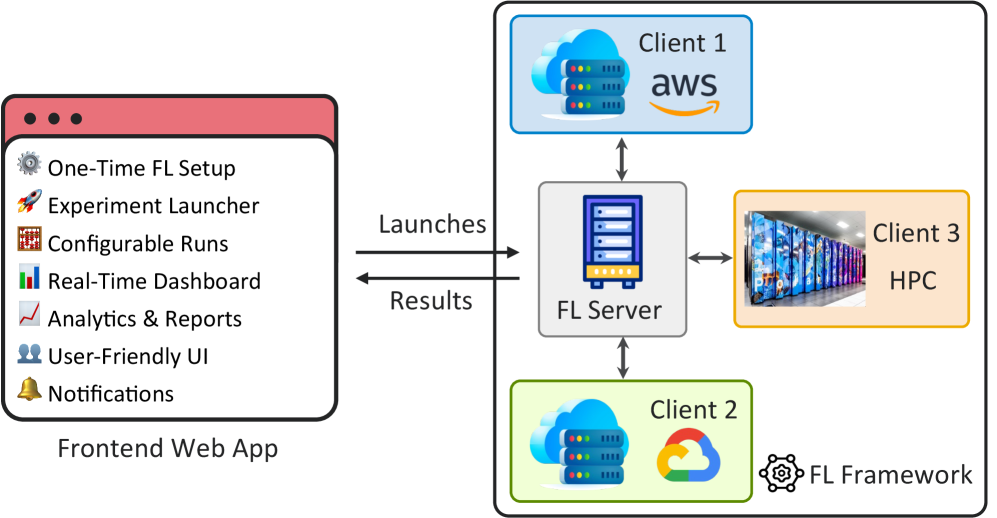
FLaaS упрощает настройку, автоматизацию и аналитику, сокращая время и ресурсы для развертывания федеративных обучающих систем. Стабильность – иллюзия, но адаптация к течению времени – истинная ценность.
Организация Распределенного Обучения
Реализация федеративного обучения требует тщательно спланированного рабочего процесса: от локального моделирования до предразвертывания и тестирования. Важно обеспечить воспроизводимость результатов и отслеживание изменений. Инфраструктурной основой служат инструменты, такие как Parsl, Ray и Kubernetes, обеспечивающие масштабируемость, отказоустойчивость и эффективное использование ресурсов.
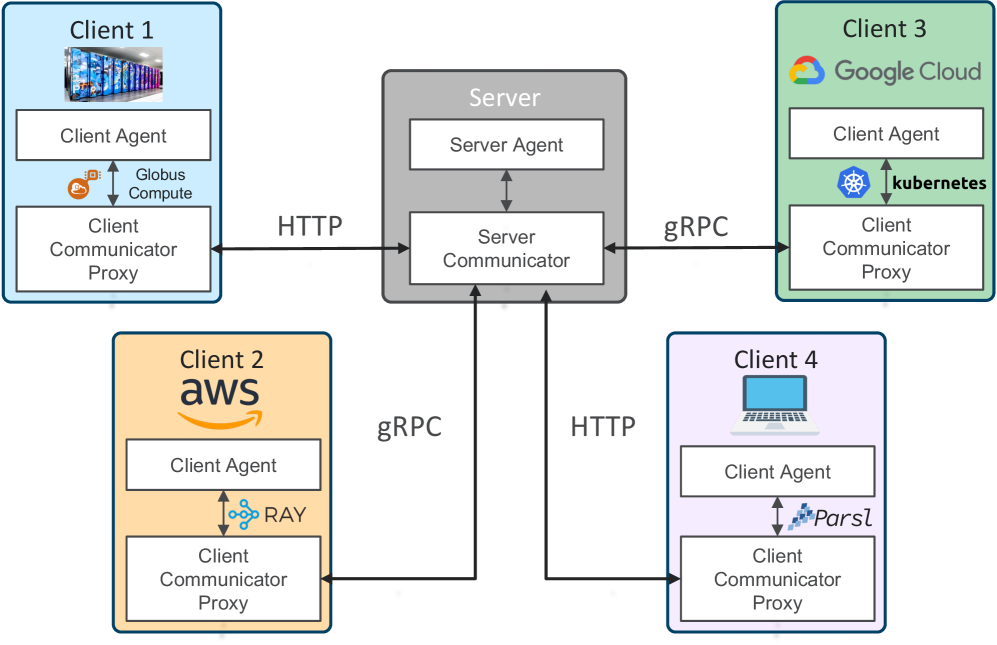
Globus Compute расширяет эту инфраструктуру для крупномасштабных ресурсов, преодолевая разрыв между прототипированием и развертыванием. Контейнеризация и оркестрация упрощают управление моделями в различных средах.
Защита Данных в Совместном Обучении
Обеспечение конфиденциальности данных – ключевая задача. Используются методы, такие как Дифференциальная конфиденциальность, Безопасная агрегация и Гомоморфное шифрование. Secure Multi-Party Computation (MPC) обеспечивает совместные вычисления без раскрытия данных. Важно решать проблемы Non-IID данных и гетерогенных клиентов для обеспечения справедливости и обобщающей способности моделей.
Неоднородность данных может приводить к смещениям и снижению производительности. Необходимо разрабатывать методы, компенсирующие эти различия и обеспечивающие справедливое обучение.
Масштабирование Федеративного Обучения
В последние годы федеративное обучение привлекает все больше внимания. Для упрощения разработки, развертывания и оценки моделей, разработаны фреймворки, такие как NVFlare, FederatedScope, Flower, FedML, OpenFL, FedScale и FedLab. Каждый из них имеет свои сильные стороны и ориентирован на решение различных задач.
Некоторые фреймворки, такие как FederatedScope и Flower, акцентируют внимание на быстром прототипировании, другие, такие как NVFlare и FedScale, ориентированы на масштабируемые и надежные решения для промышленного применения. Ключевым компонентом является механизм агрегации моделей, обеспечивающий объединение локальных обновлений в единую глобальную модель.
Подобно эрозии, технический долг влияет на устойчивость инфраструктуры, а редкие моменты бесперебойной работы – лишь фазы гармонии.
Будущее Совместного Интеллекта
Предоставление федеративного обучения как услуги (FLaaS) снижает порог входа для организаций. Это позволяет компаниям сосредоточиться на данных и задачах, делегируя вычислительные ресурсы. Стандартизованная схема данных играет решающую роль в обеспечении совместимости и обмене данными между клиентами.
Дальнейшие исследования и разработки будут способствовать инновациям в алгоритмах FL, методах сохранения конфиденциальности и масштабируемой инфраструктуре. Особое внимание уделяется оптимизации алгоритмов для работы с неоднородными данными и ресурсами, а также разработке новых подходов к защите данных.
Исследование, представленное в статье, демонстрирует стремление к созданию масштабируемой и безопасной системы федеративного обучения. Это не просто техническая задача, но и философский вызов – попытка сохранить ценность данных в условиях их распределенности и неизбежной эволюции системы. Как отмечал Андрей Колмогоров: «Математика – это искусство находить закономерности в хаосе». В данном контексте, федеративное обучение – это поиск закономерности в распределенных данных, преодоление хаоса разнородной инфраструктуры и обеспечение безопасности. Статья подчеркивает важность перехода от симуляции к реальному развертыванию, что можно рассматривать как адаптацию системы к меняющимся условиям, её способность к долгосрочному существованию в сложной среде.
Что же дальше?
Предложенная архитектура для федеративного обучения, безусловно, представляет собой шаг вперёд, но, как и любая система, она неизбежно подвержена старению. Временная аналитика подсказывает: любое улучшение в масштабируемости и безопасности, каким бы значительным оно ни казалось, окажется недостаточным в долгосрочной перспективе. Гетерогенность инфраструктуры, изначально обозначенная как вызов, вскоре превратится в непреодолимое препятствие, требующее постоянной адаптации и, вероятно, пересмотра базовых принципов. Переход от симуляции к развёртыванию — лишь первый акт в бесконечной драме, где реальность всегда оказывается сложнее модели.
Ключевым вопросом остаётся не столько достижение максимальной производительности, сколько поддержание работоспособности системы в условиях постоянных изменений. “Откат” — это не ошибка, а естественное движение назад по стрелке времени, неизбежная часть любого эволюционного процесса. Поэтому, вместо того чтобы стремиться к совершенству, стоит сосредоточиться на создании систем, способных достойно стареть, адаптироваться к новым вызовам и извлекать уроки из собственных ошибок. Оптимизация отдельных компонентов, вероятно, будет менее ценной, чем разработка механизмов самовосстановления и предсказания отказов.
Будущие исследования должны быть направлены не на увеличение скорости, а на повышение устойчивости. Вместо того, чтобы строить более сложные модели, следует стремиться к упрощению и модульности, что позволит легче заменять устаревшие компоненты и адаптироваться к новым требованиям. И, возможно, самое важное – признать, что любая система, какой бы гениальной она ни была, обречена на увядание, и относиться к этому с философским смирением.
Оригинал статьи: https://arxiv.org/pdf/2511.08998.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Биосети в руках ИИ: Автоматизация системной фармакологии
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сияние фотонов: новый уровень точности в предсказаниях столкновений частиц
- Трансформация нейросетей: от плотных моделей к разреженным экспертам без обучения
- Квантовая Физика и Безопасность: Анализ Последних Новостей
- Искусственный интеллект проектирует белки: новый горизонт биоинженерии
- Квантовый скачок через SPAC: Анализ рынка и физика надежды
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
- Квантовый горизонт: взгляд изнутри
- Батарея под контролем: Искусственный интеллект на страже долговечности
2025-11-13 15:42