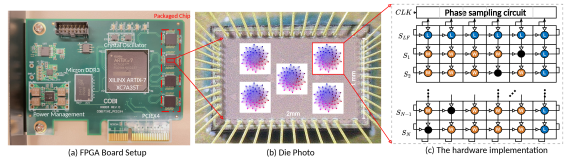
Квантовые нейросети: преодолевая ограничения масштаба
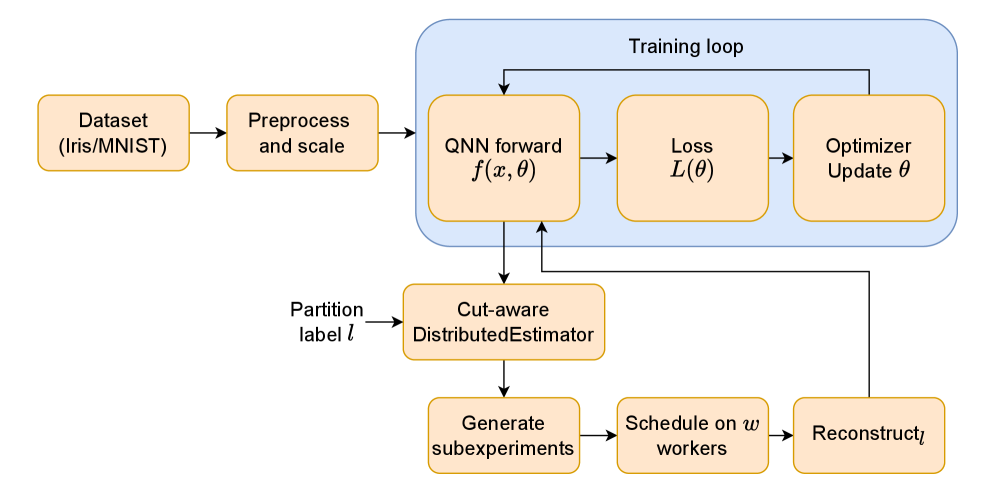
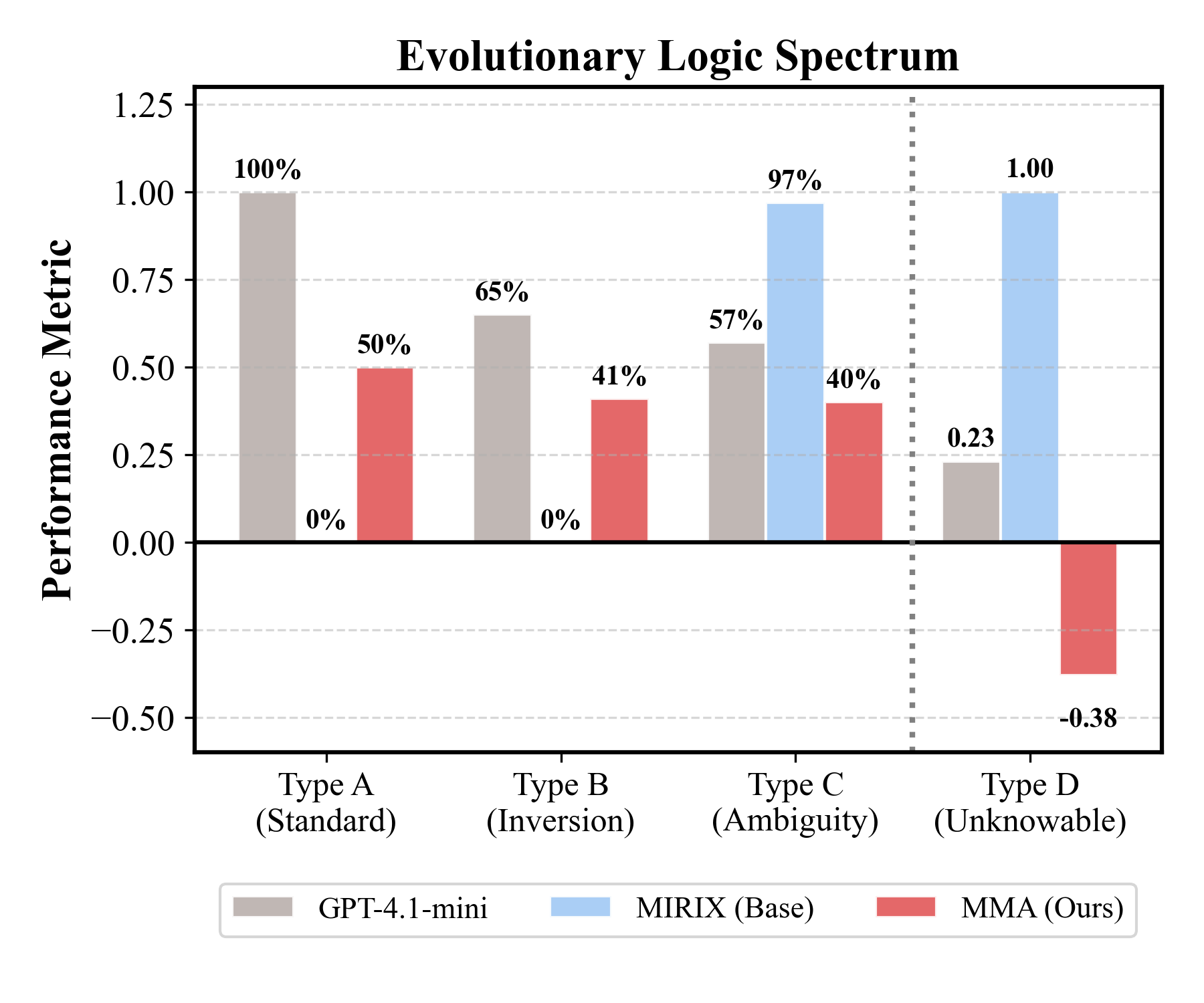
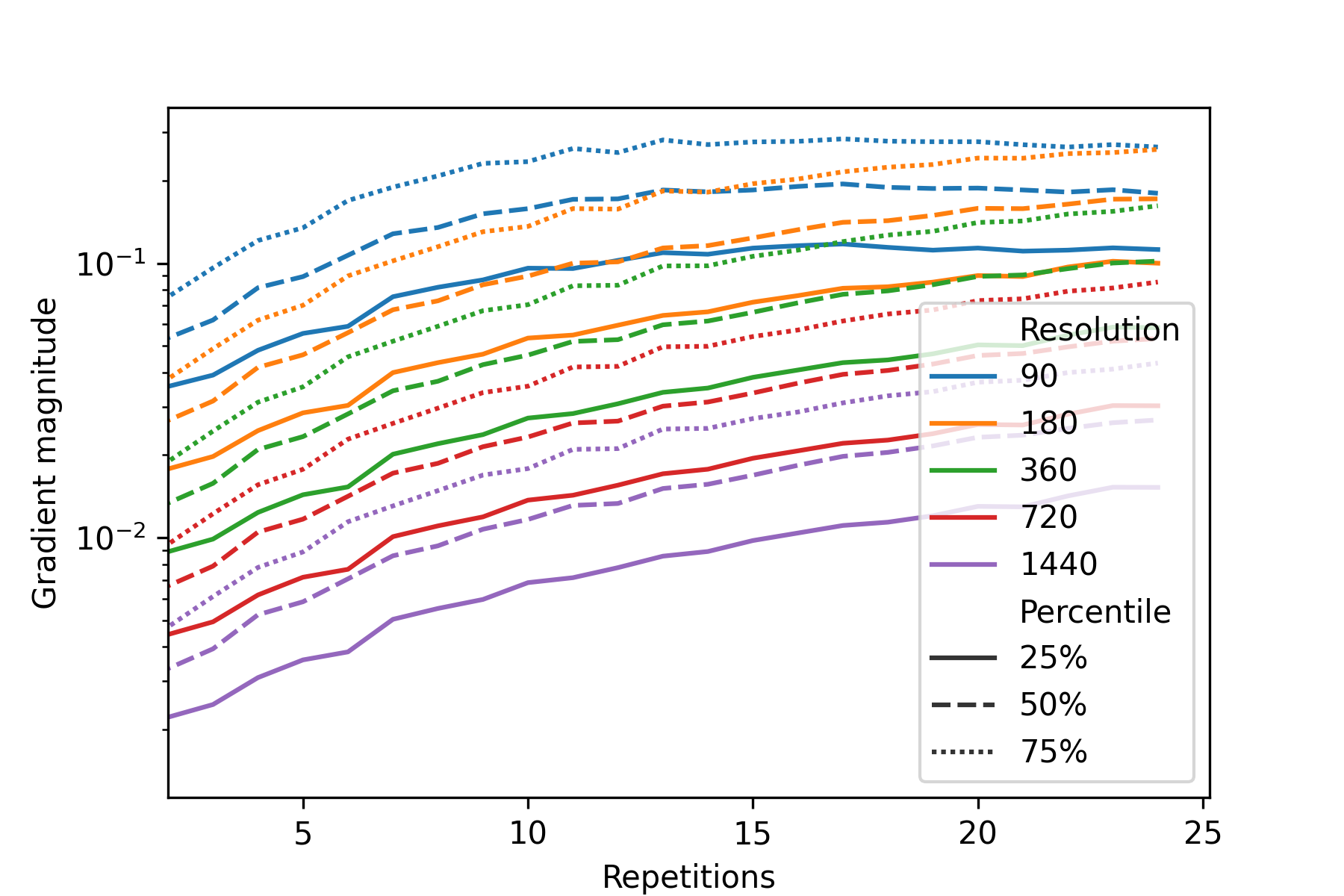
Новое исследование показывает, что для эффективного обучения больших квантовых нейросетей необходимо оптимизировать классическую обработку данных, возникающую при использовании метода разбиения квантовых схем.