Разум на грани: Оптимизация больших моделей ИИ для воплощенного интеллекта
![Реальная тестовая среда демонстрирует совместное выполнение вычислений с учётом квантования [latex]LAIM[/latex], что подтверждает возможность эффективной работы алгоритма в практических условиях.](https://arxiv.org/html/2602.13052v1/fig/testbed.jpg)
Новый подход позволяет эффективно развертывать сложные алгоритмы искусственного интеллекта в реальном мире, снижая требования к вычислительным ресурсам и энергопотреблению.
Новый подход позволяет эффективно развертывать сложные алгоритмы искусственного интеллекта в реальном мире, снижая требования к вычислительным ресурсам и энергопотреблению.
![Количество синтезированных образцов для каждого недостающего признака напрямую влияет на точность оценки [latex] AUPRC [/latex] и общую эффективность использования данных, демонстрируя зависимость между объёмом синтезированной информации и качеством анализа.](https://arxiv.org/html/2602.10388v2/x7.png)
Исследователи предлагают эффективный метод улучшения производительности больших языковых моделей после обучения, используя синтетические данные, ориентированные на недостающие внутренние представления.
Исследователи представили MXFormer — архитектуру, использующую инновационные транзисторы и микромасштабирование данных для значительного повышения производительности и энергоэффективности при обработке коротких последовательностей.

В статье представлена X-SYS — эталонная архитектура для создания интерактивных систем объяснения, призванная преодолеть разрыв между исследованиями в области XAI и практической реализацией.

Исследователи предлагают инновационный метод представления видеоданных для моделей, объединяющих видео и язык, позволяющий значительно сократить объем используемых токенов.
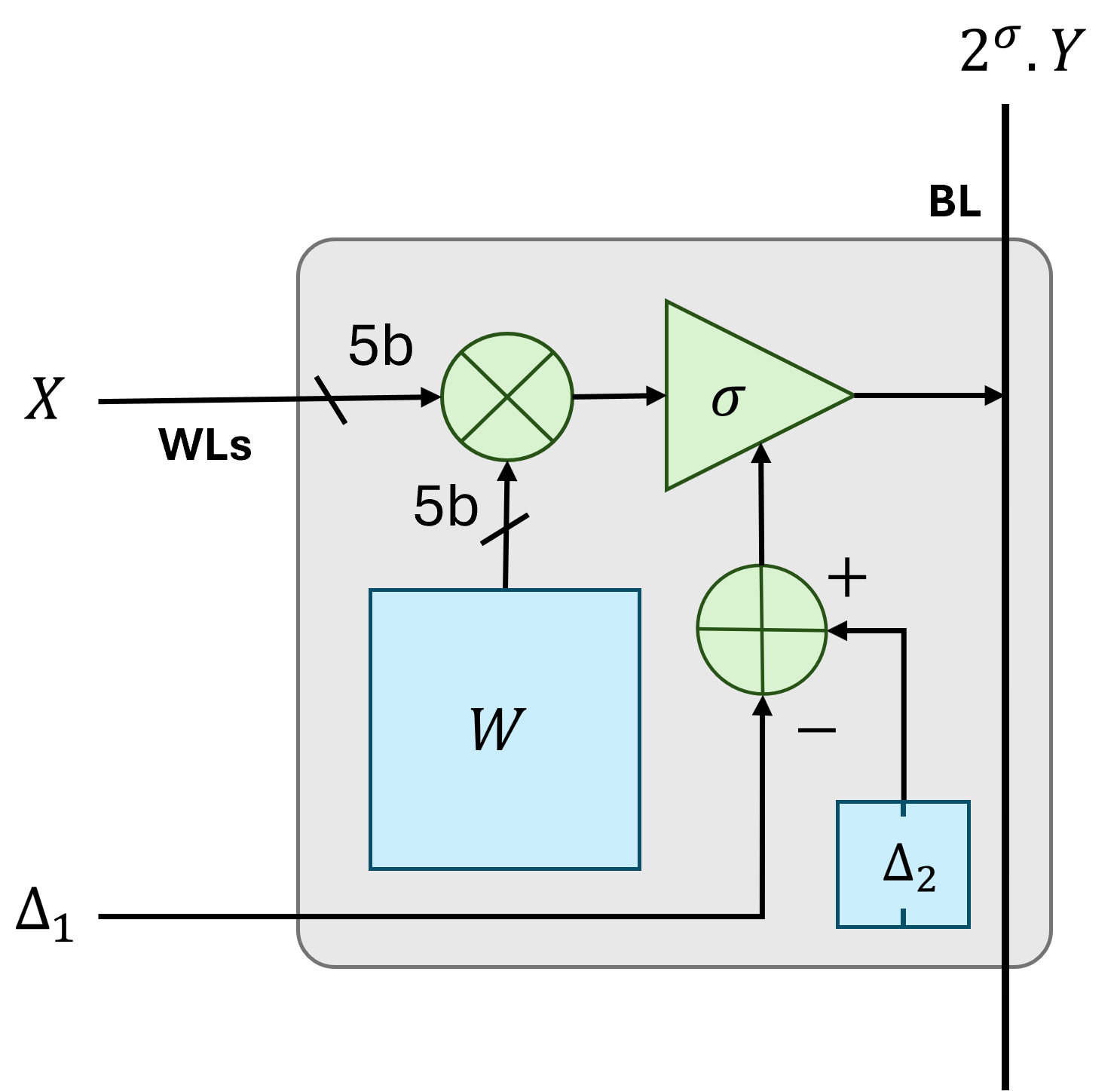
Новый подход к разработке аппаратного обеспечения для периферийных вычислений позволяет эффективно обучать нейронные сети, используя ограниченные наборы данных.
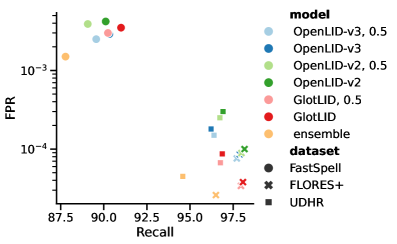
Исследователи представляют OpenLID-v3 — усовершенствованную систему определения языка, демонстрирующую высокую точность даже в сложных случаях и при работе с данными из интернета.
![Отношение интенсивности эмиссии [latex]I_{11.2}/I_{3.3}[/latex] демонстрирует чёткую зависимость от числа атомов углерода в полициклических ароматических углеводородах (ПАУ), что подтверждается анализом полного набора данных, включающего 15 022 нейтральных молекулы, и подмножества из 81 ПАУ, отобранного Maragkoudakis и соавторами (2020), при использовании каскадной модели с энергией 6 эВ, а качество аппроксимации, оцениваемое по значению [latex]R^{2}[/latex], указывает на надёжность установленной корреляции.](https://arxiv.org/html/2602.12531v1/x1.png)
Новый подход с использованием машинного обучения позволяет более точно определять размер и заряд полициклических ароматических углеводородов в межзвездном пространстве.
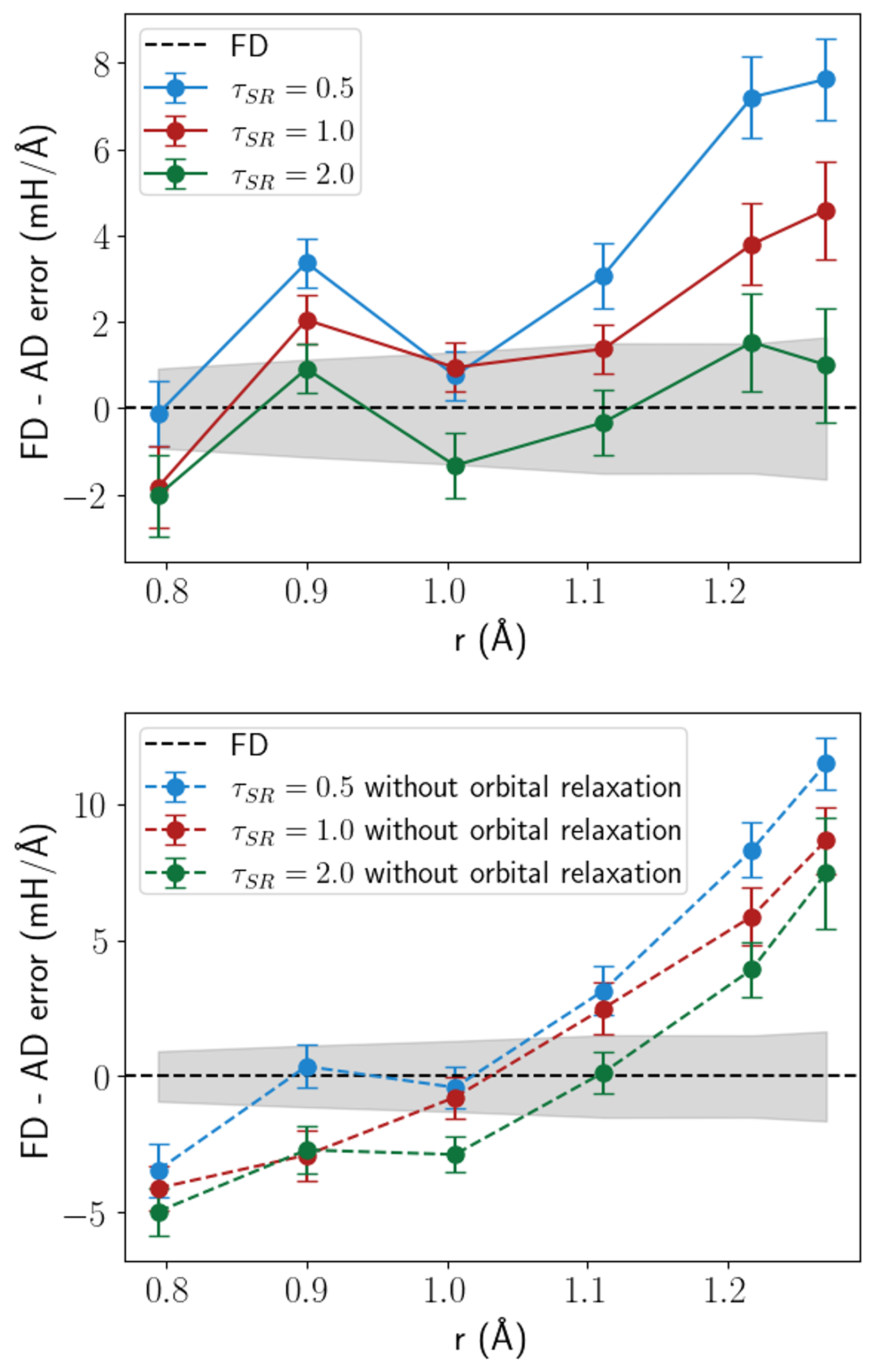
Новый метод вычисления градиентов ядер в рамках ph-AFQMC открывает возможности для высокоточного моделирования молекулярной геометрии и поиска переходных состояний.
![Наблюдается распределение индекса растительности [latex]NDVI[/latex] по сегментам крон деревьев, при этом порог отсечения, определяющий границы сегментов, обозначен пунктирной вертикальной линией, что позволяет отделить области с высокой и низкой растительной активностью.](https://arxiv.org/html/2602.13022v1/x6.png)
Новый подход позволяет обучать модели сегментации крон деревьев, используя слабо размеченные данные лидара и методы переноса знаний, значительно снижая затраты на создание обучающих выборок.