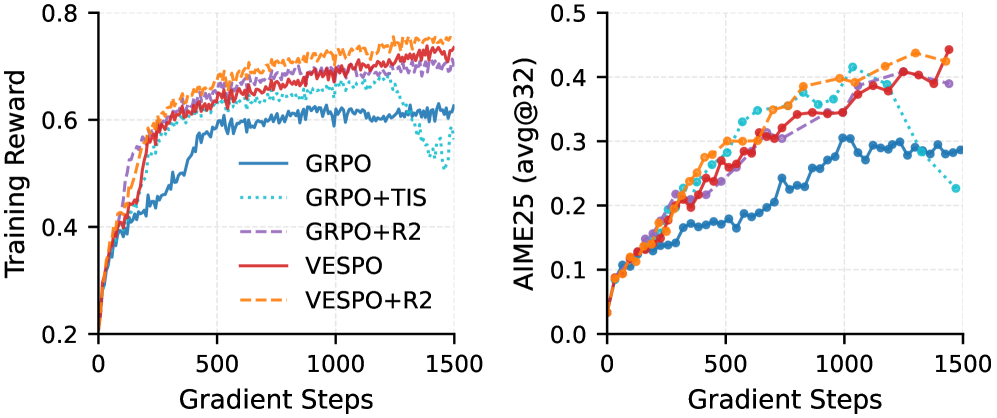
Визуальные аналогии: новый подход к редактированию изображений

Исследователи предлагают инновационный метод, позволяющий динамически комбинировать небольшие адаптеры для достижения впечатляющих результатов в задаче визуального переноса стилей и манипулирования изображениями.

![Современные методы видеосегментации, представленные, например, архитектурой CAVIS, уступают упрощенному подходу VidEoMT, использующему исключительно энкодер и опирающемуся на возможности предварительно обученных vision foundation models вместо ручной настройки компонентов, что позволяет добиться эффективности благодаря силе масштабного обучения и контекстно-зависимых механизмов [latex]TF[/latex] и [latex]CA[/latex].](https://arxiv.org/html/2602.17807v1/x1.png)
![Модель ModelSMC, вдохновлённая последовательным Монте-Карло (SMC), итеративно уточняет начальную модель посредством отбора проб с использованием большой языковой модели (LLM) и взвешивания на основе оценки правдоподобия, стремясь к сходимости к неизвестному процессу генерации данных [latex]p(m|{\bm{x}}\_{o})[/latex] в областях высокой плотности, что позволяет автоматизировать обнаружение моделей на основе текстовых формулировок задач и контекстных данных.](https://arxiv.org/html/2602.18266v1/x1.png)