Искусство редактирования: Новая модель для точной обработки изображений
Представлена FireRed-Image-Edit, инновационная архитектура на основе диффузионных трансформаторов, позволяющая с высокой точностью редактировать изображения по текстовым инструкциям.
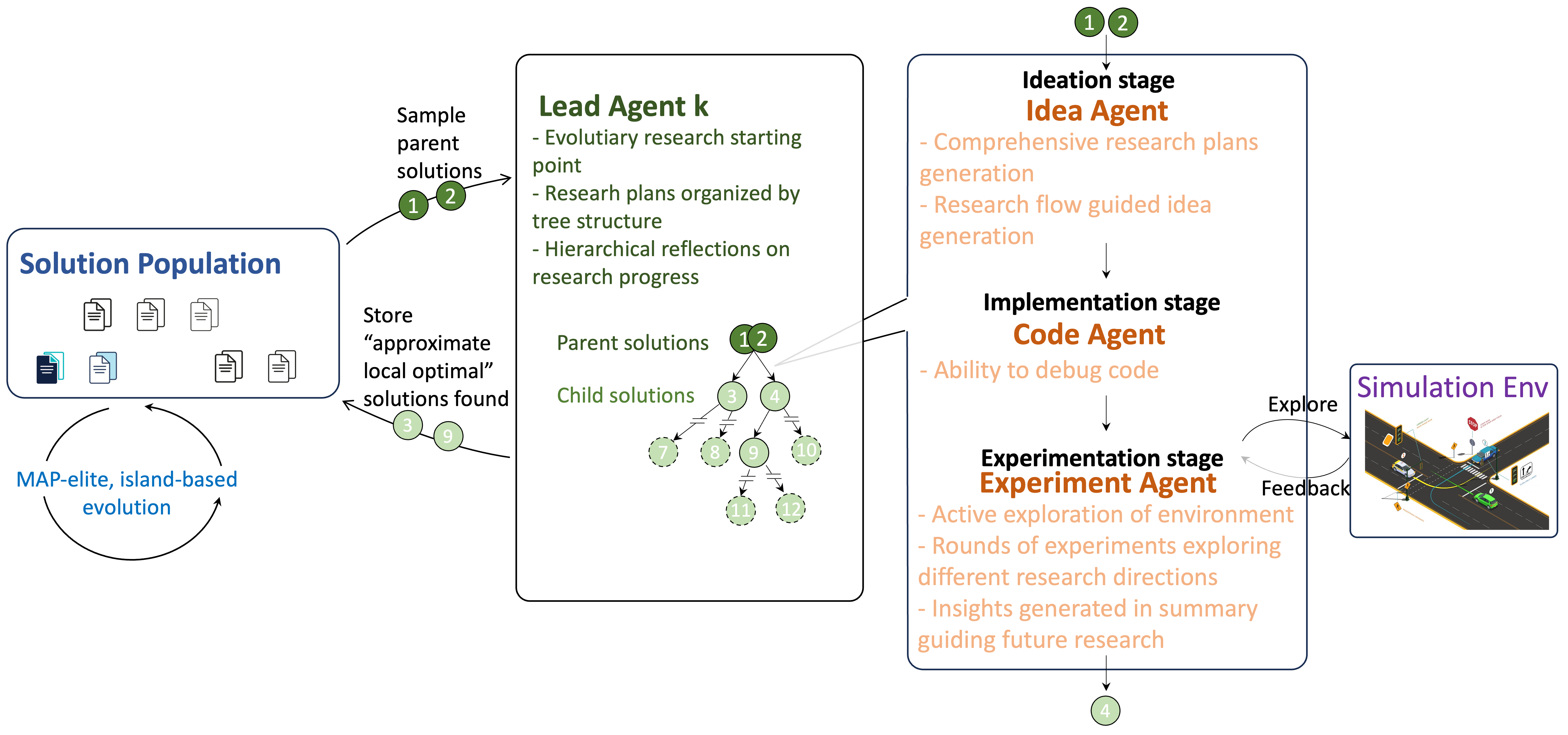
![Визуальный интеллект рассматривается как задача предсказуемого сжатия, где масштабируемое обучение возникает благодаря соответствию предсказуемой структуре мира, подобно видеокодекам, явно структурирующим визуальные сигналы на стабильный пространственный контекст и разреженные временные обновления, что позволяет OV-Encoder позиционироваться как масштабируемый механизм универсального мультимодального интеллекта, способного воспринимать, обновлять и рассуждать во времени, опираясь на принцип кодирования предсказуемой информации и минимизации избыточности, как это реализовано в современных видеокодеках, где [latex]I = S + R[/latex], где <i>I</i> - исходное изображение, <i>S</i> - стабильный контекст, а <i>R</i> - разреженные обновления.](https://arxiv.org/html/2602.08683v2/x1.png)
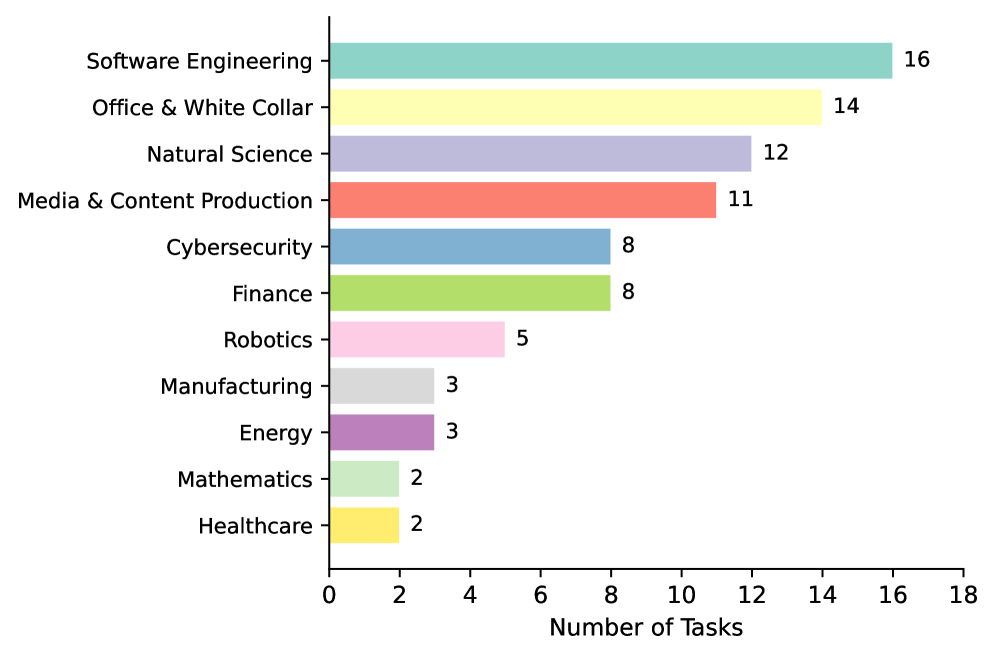
![Количество синтезированных образцов для каждого недостающего признака напрямую влияет на точность оценки [latex] AUPRC [/latex] и общую эффективность использования данных, демонстрируя зависимость между объёмом синтезированной информации и качеством анализа.](https://arxiv.org/html/2602.10388v2/x7.png)
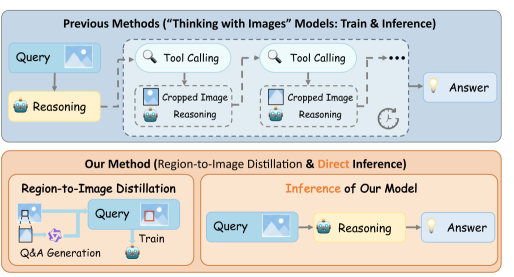
![Реальная тестовая среда демонстрирует совместное выполнение вычислений с учётом квантования [latex]LAIM[/latex], что подтверждает возможность эффективной работы алгоритма в практических условиях.](https://arxiv.org/html/2602.13052v1/fig/testbed.jpg)

