Память, которая адаптируется: новый подход к долгосрочному мышлению
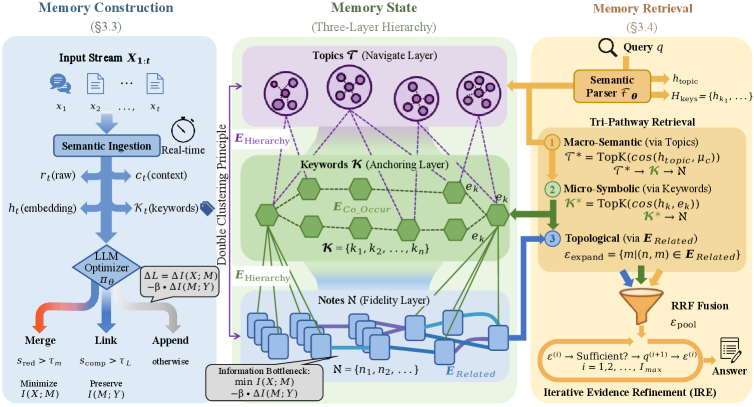
Исследователи представили MemFly — систему, оптимизирующую память языковых моделей для повышения качества рассуждений и сохранения важной информации.
Исследователи представили MemFly — систему, оптимизирующую память языковых моделей для повышения качества рассуждений и сохранения важной информации.
Новый подход к оценке надежности ИИ-помощников в сфере психического здоровья позволяет выявить риски и обеспечить более справедливый доступ к лечению.

Новая модель PISCO позволяет реалистично добавлять и перемещать объекты в видео, требуя лишь небольшое количество ключевых кадров для управления процессом.
![Оптимизация, основанная на биологических принципах, выявляет устойчивые связи между параметрами мозга и поведенческими особенностями - когнитивными способностями и различными проявлениями внутренних и внешних поведенческих проблем - что подтверждается статистически значимыми результатами, превосходящими случайный уровень и оцениваемыми с помощью [latex]R^{2}[/latex] и соответствующих [latex]p[/latex]- и [latex]q[/latex]-значений, полученных посредством перестановки меток поведения.](https://arxiv.org/html/2602.11398v1/x3.png)
Новое исследование показывает, как вдохновлённый биологией подход к оптимизации целых моделей мозга позволяет улучшить их обобщающую способность и точность предсказаний когнитивных и поведенческих особенностей.

Новое исследование выявляет фундаментальную проблему в современных алгоритмах обучения с подкреплением на основе обратной связи от человека, ограничивающую их способность к исследованию и адаптации к новым задачам.
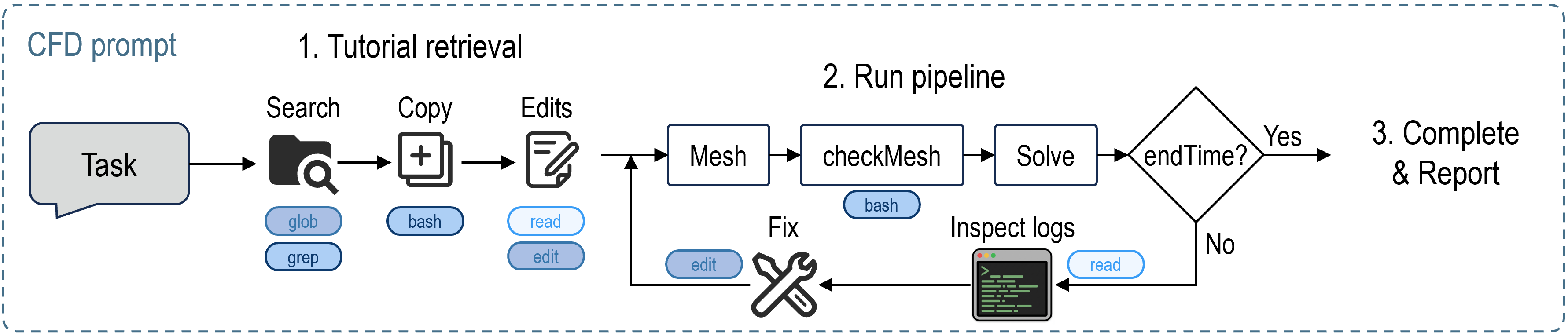
Новое исследование показывает, как системы искусственного интеллекта могут упростить и повысить надежность сложных расчетов в области гидрогазодинамики.
![В отличие от существующих методов, формирующих музыкальное сопровождение для видео на основе поверхностных визуальных признаков, предложенный подход использует глобальную сюжетную линию [latex]S_{global}[/latex] и локальные эмоциональные оттенки [latex]E_{local}[/latex] для создания темпорально связных и нарративно резонирующих саундтреков.](https://arxiv.org/html/2602.09070v2/figures/real/Fig1.jpg)
Новая система NarraScore создает динамичные саундтреки к видео, подстраиваясь под развитие сюжета и эмоциональную окраску кадров.
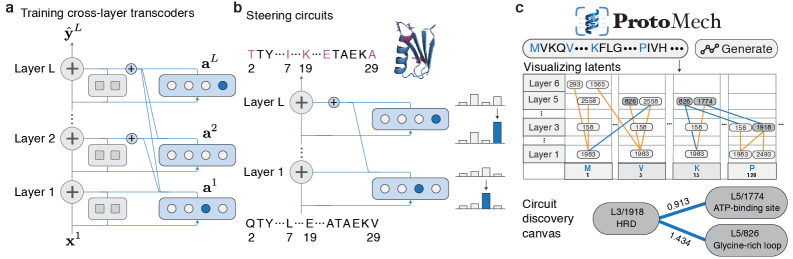
Исследователи разработали инновационный метод для анализа внутренних механизмов моделей машинного обучения, предназначенных для изучения белков, позволяющий понять, как эти модели принимают решения.
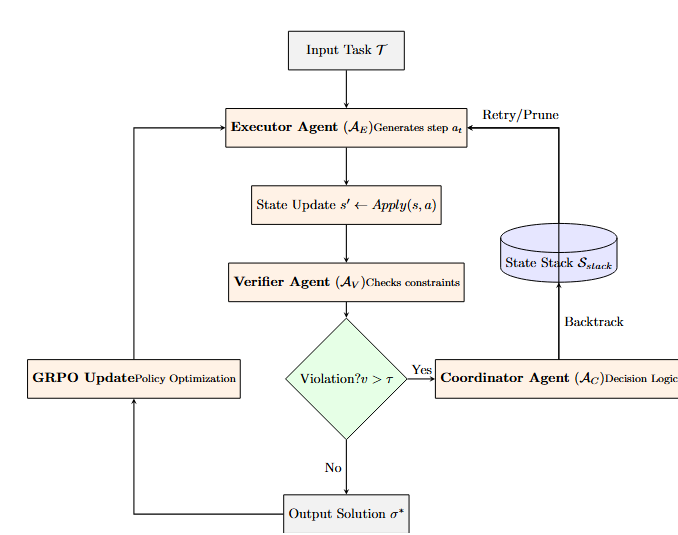
Исследователи предлагают систему, в которой несколько виртуальных агентов, управляемых большой языковой моделью, совместно решают алгоритмические задачи, значительно превосходя существующие методы.
Исследователи представили масштабируемую архитектуру и мощный токенизатор, открывающие возможности для создания продвинутых моделей обработки звука.