Когда данные говорят: как UME-R1 обучает модели понимать взаимосвязи

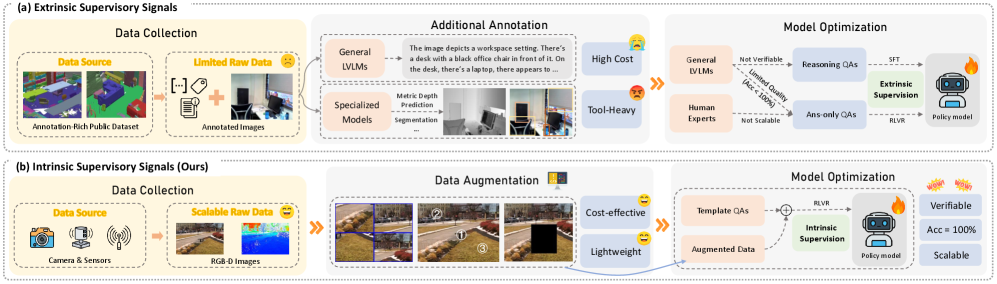
Новый фреймворк UME-R1 объединяет генеративные и дискриминативные подходы к мультимодальным эмбеддингам, используя обучение с подкреплением для улучшения рассуждений и повышения производительности.