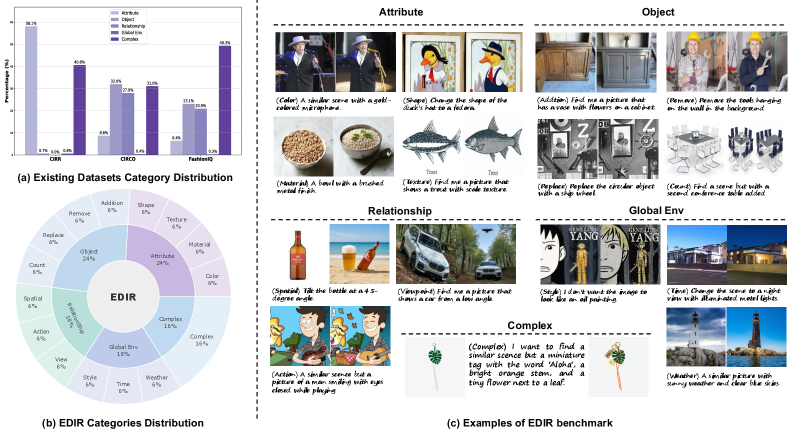
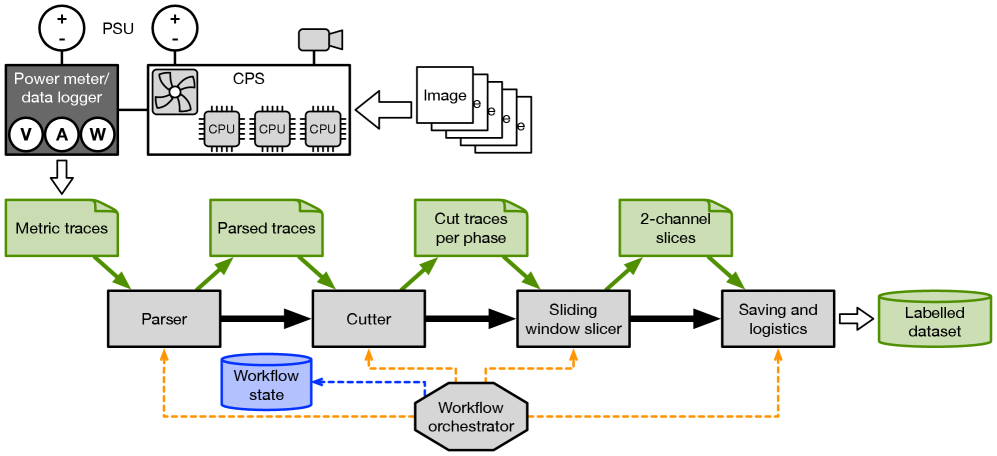
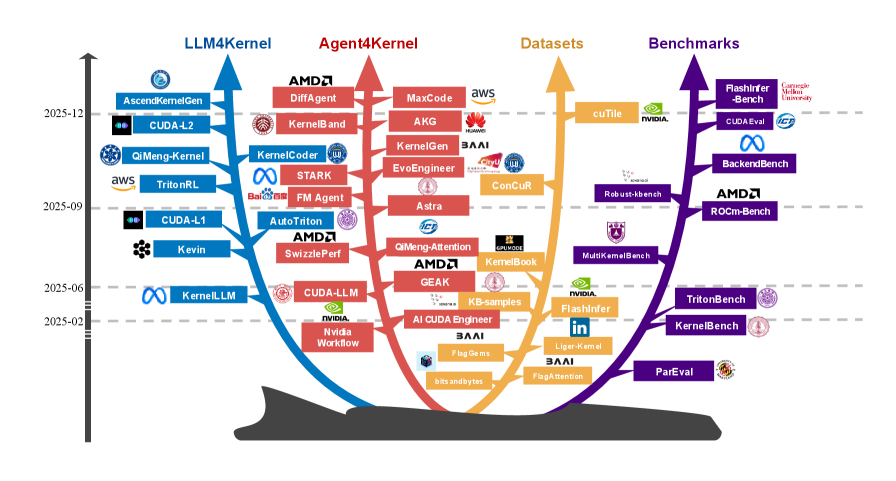
Искусственный интеллект меняет научные горизонты: влияние больших языковых моделей на финансирование исследований в США
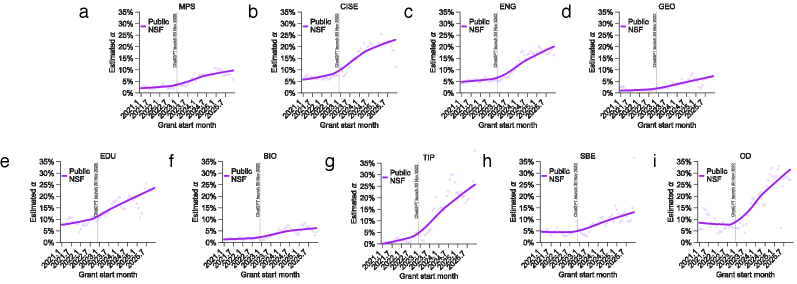
Новое исследование показывает, как появление мощных моделей искусственного интеллекта трансформирует систему федерального финансирования научных разработок в Соединенных Штатах.