Искусство видеть и создавать: Новая эра генерации изображений по тексту
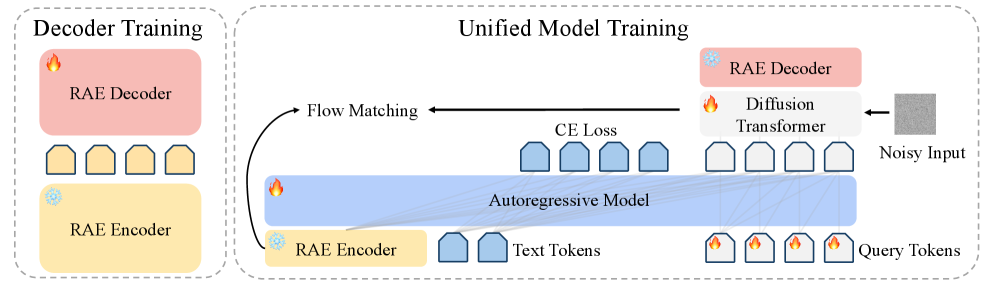
Исследователи предлагают упрощенный подход к обучению масштабных моделей генерации изображений, основанный на автоэнкодерах представлений, что открывает возможности для более быстрого обучения и повышения качества.