Роботы учатся у людей: новая эра в машинном обучении
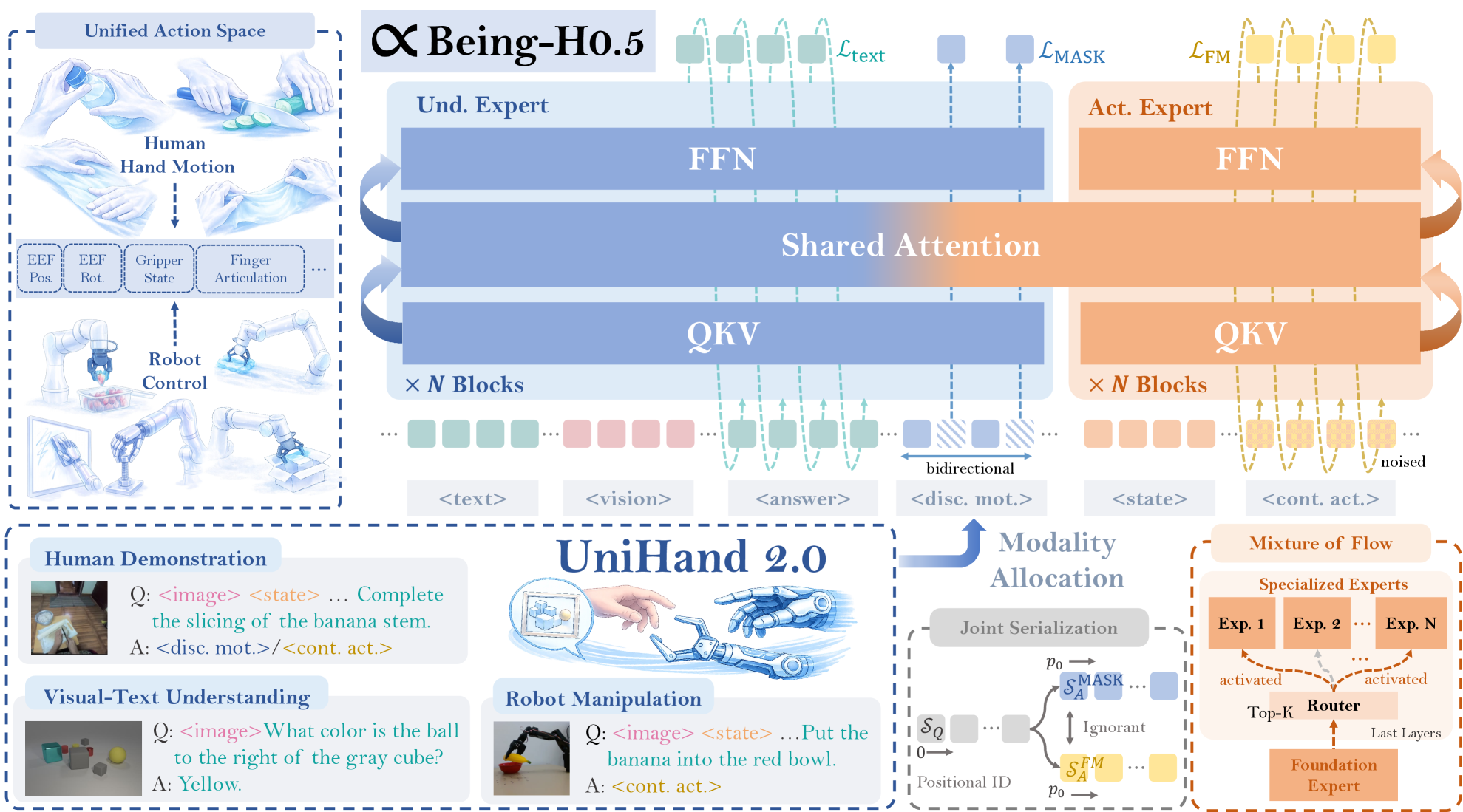
Исследователи представили модель Being-H0.5, позволяющую роботам эффективно переносить навыки между разными типами корпусов благодаря обучению на больших объемах данных, созданных людьми.
Исследователи представили модель Being-H0.5, позволяющую роботам эффективно переносить навыки между разными типами корпусов благодаря обучению на больших объемах данных, созданных людьми.
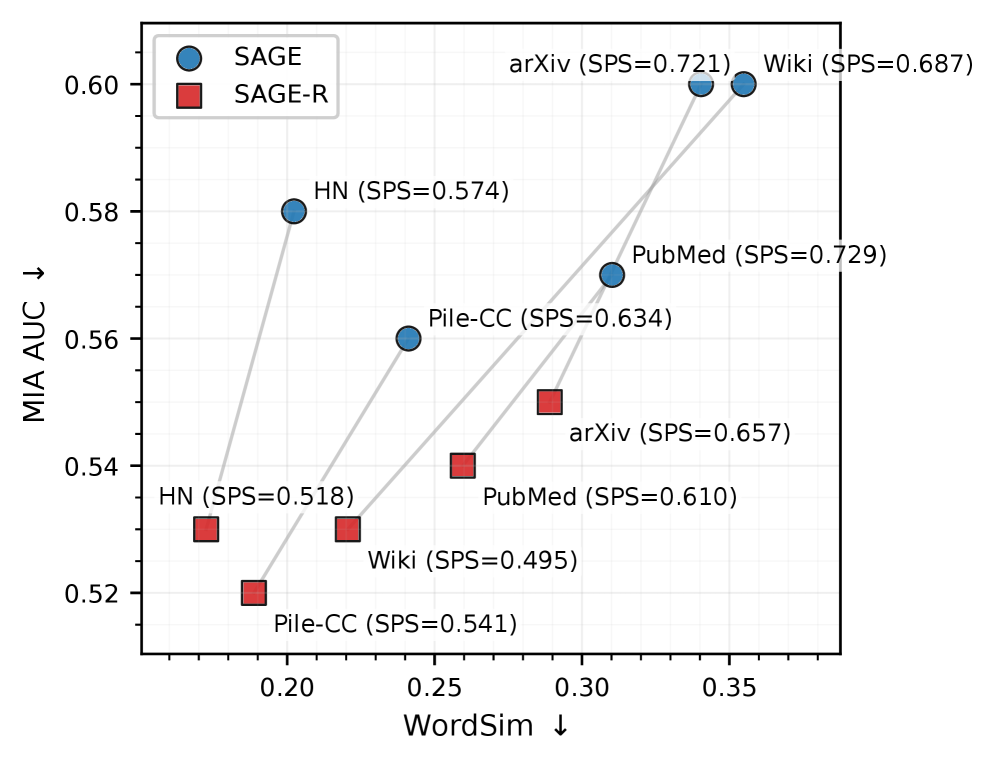
Новое исследование показывает, что существующие методы выявления использования защищенного контента большими языковыми моделями легко обойти, используя семантически эквивалентные перефразировки.
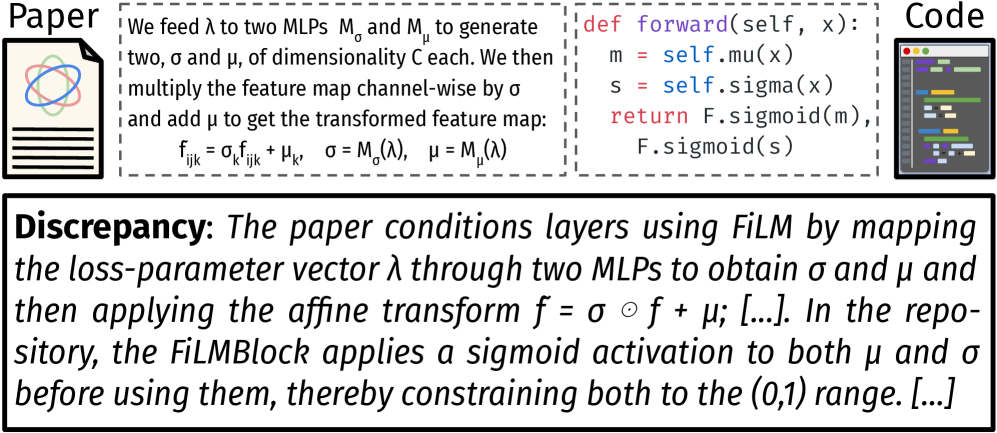
Новый подход позволяет оценить, насколько точно программная реализация соответствует описанию в научной публикации.
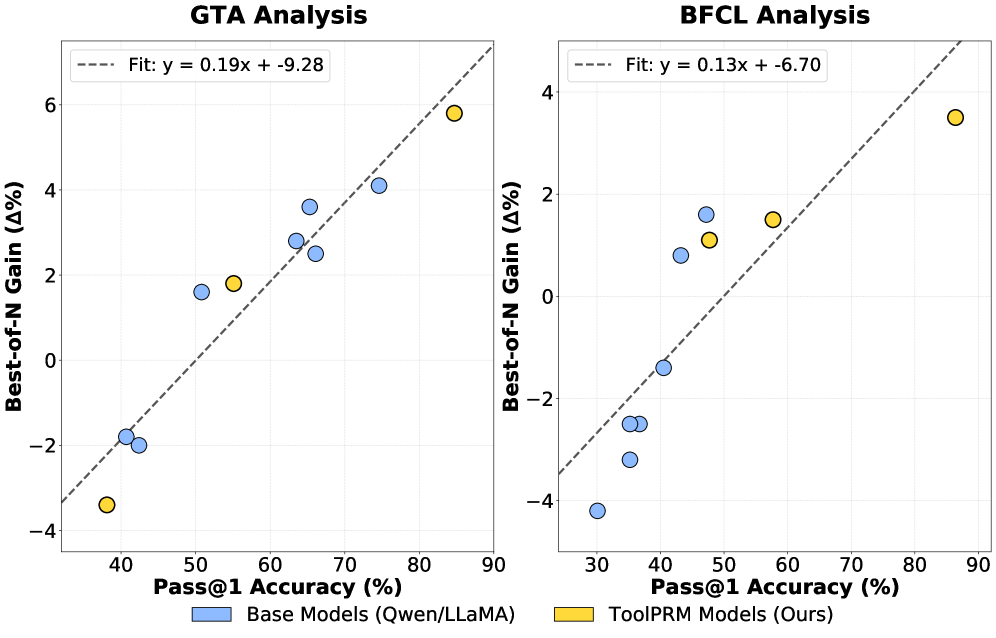
Исследователи представили масштабный бенчмарк для оценки моделей вознаграждения, управляющих агентами, использующими инструменты, что открывает путь к более эффективному и универсальному искусственному интеллекту.

Исследователи разработали метод, позволяющий системам искусственного интеллекта самостоятельно улучшать качество поиска информации для более эффективного решения задач.
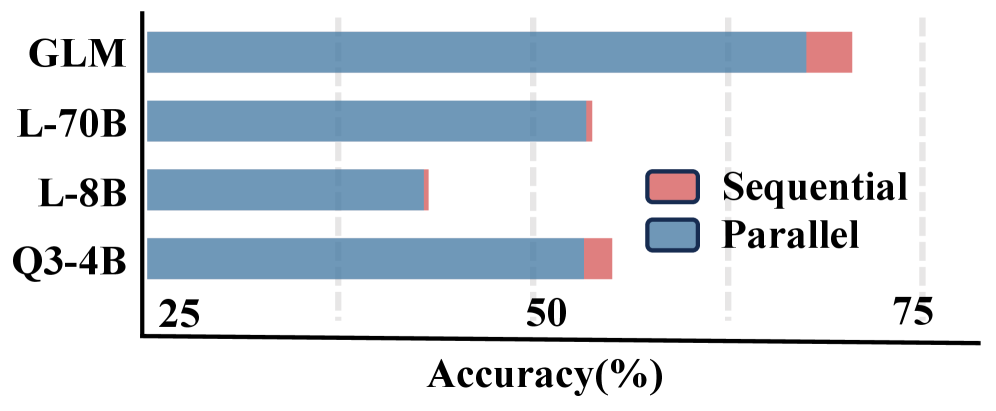
Исследователи представили новый способ оценки качества управления долгосрочной памятью в больших языковых моделях, выявляя слабые места существующих систем вознаграждения.
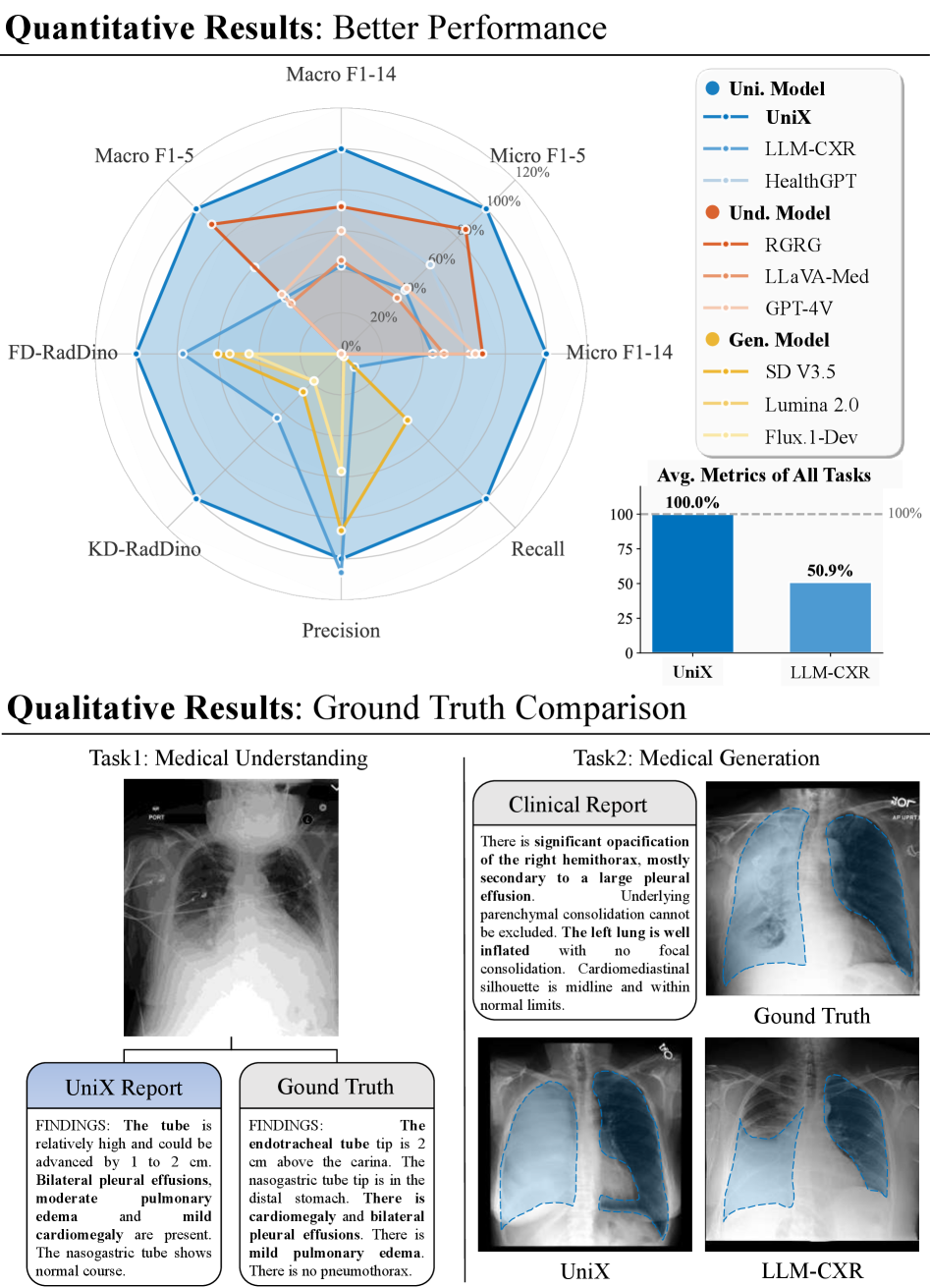
Новая модель объединяет возможности авторегрессии и диффузии для комплексного анализа и генерации изображений грудной клетки.
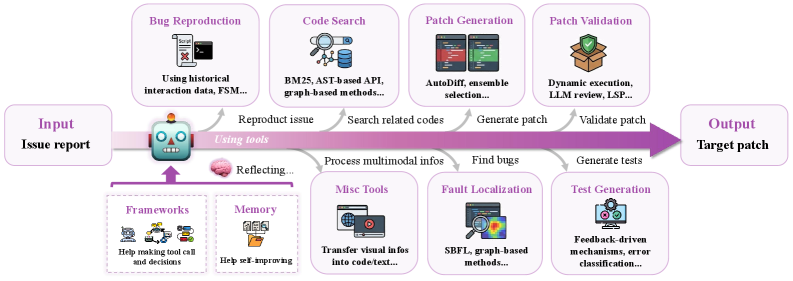
Обзор показывает, как современные модели машинного обучения автоматизируют рутинные задачи по исправлению ошибок и улучшению качества программного обеспечения.
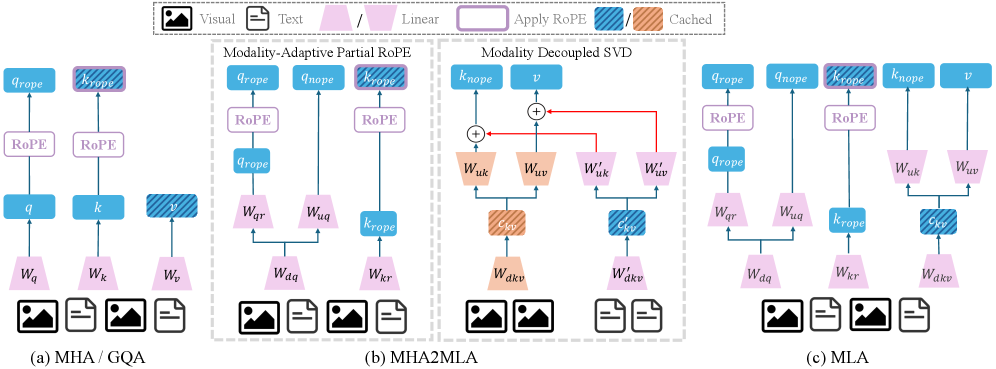
Исследователи разработали метод, позволяющий значительно снизить потребление памяти в мультимодальных моделях, не жертвуя при этом качеством обработки данных.
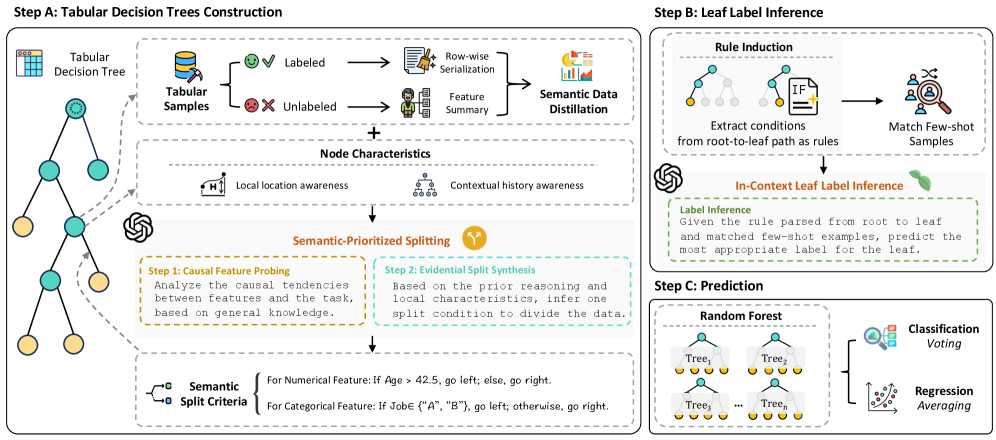
Исследователи разработали систему, использующую возможности больших языковых моделей для повышения эффективности алгоритмов случайного леса при работе с ограниченным объемом данных.