Автор: Денис Аветисян
Новое исследование показывает, что стандартные методы параметрической эффективности не всегда оптимальны для обучения с подкреплением, требующего верификации наград.
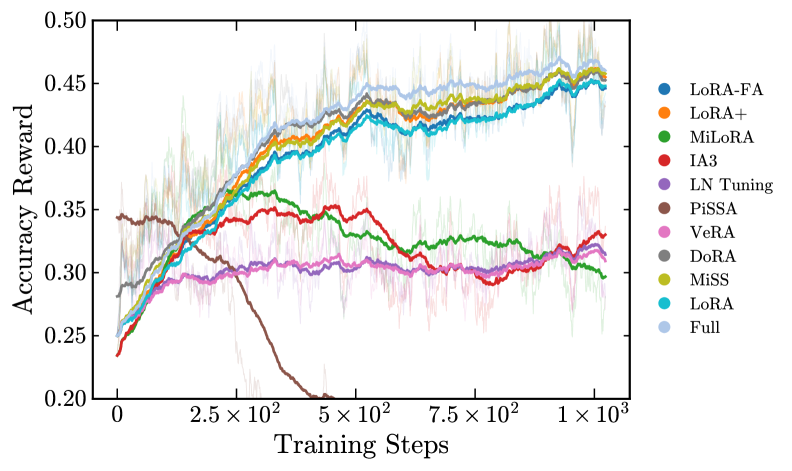
Оценка и сравнение различных методов параметрической тонкой настройки, включая LoRA и ее структурные варианты, в контексте Reinforcement Learning with Verifiable Rewards (RLVR).
Несмотря на растущую популярность методов параметрически-эффективной тонкой настройки (PEFT), оптимальная архитектура для обучения с подкреплением с верифицируемыми наградами (RLVR) остается неясной. В работе ‘Evaluating Parameter Efficient Methods for RLVR’ представлен систематический анализ более 12 PEFT-методологий на основе моделей DeepSeek-R1-Distill для задач математического рассуждения. Полученные результаты показывают, что структурные варианты, такие как DoRA и AdaLoRA, превосходят стандартный LoRA, а инициализация на основе сингулярного разложения (SVD) может приводить к неоптимальным результатам из-за несоответствия между обновлениями главных компонент и динамикой оптимизации RLVR. Не потребует ли более глубокое понимание этих закономерностей пересмотра текущих подходов к параметрически-эффективному обучению с подкреплением?
Пределы масштабируемости: вызовы логического вывода в больших языковых моделях
Несмотря на впечатляющие возможности в обработке и генерации языка, современные большие языковые модели, такие как DeepSeek-R1-Distill, демонстрируют существенные трудности при решении задач, требующих многоступенчатого логического вывода. Способность генерировать грамматически правильный и контекстуально релевантный текст не гарантирует успешное выполнение сложных вычислений или логических построений, особенно когда требуется последовательное применение нескольких шагов для достижения конечного результата. Данное ограничение связано с тем, что модели обучаются предсказывать следующее слово в последовательности, а не с моделированием самого процесса логического мышления, что создает препятствия при решении задач, требующих абстрактного мышления и последовательного применения правил.
Традиционные методы обучения больших языковых моделей, такие как полная перенастройка параметров (Full-Parameter Fine-Tuning), требуют значительных вычислительных ресурсов и времени. Этот подход часто приводит к переобучению модели на конкретном наборе данных, что существенно снижает её способность к обобщению и решению новых, ранее не встречавшихся задач. На практике, это проявляется в ухудшении результатов на стандартных бенчмарках, предназначенных для оценки математических и логических способностей, таких как MATH-500, AIME и AMC. Модель, чрезмерно адаптированная к тренировочным данным, демонстрирует высокую точность на них, но её производительность резко падает при работе с задачами, отличающимися от исходного набора, что ограничивает её практическую применимость и требует разработки более эффективных и устойчивых методов обучения.
Необходимость в более эффективных и устойчивых механизмах рассуждений для больших языковых моделей (LLM) становится все более актуальной, стимулируя исследования альтернативных парадигм. Традиционные методы, такие как полная настройка параметров, требуют значительных вычислительных ресурсов и часто приводят к переобучению, ограничивая способность моделей к обобщению на стандартных наборах данных, включая MATH-500, AIME и AMC. В связи с этим, акцент смещается в сторону разработки инновационных подходов, позволяющих LLM не просто генерировать текст, но и последовательно, логически обоснованно решать сложные задачи, требующие многоступенчатого анализа и выводов. Исследователи активно изучают методы, направленные на повышение надежности и масштабируемости рассуждений, чтобы обеспечить более эффективное использование потенциала этих мощных инструментов в различных областях, от научных исследований до принятия решений.

RLVR: Смена парадигмы в логическом выводе больших языковых моделей
Метод обучения с подкреплением с верифицируемыми наградами (RLVR) представляет собой новый подход к тренировке больших языковых моделей (LLM), в котором обратная связь основана на проверяемой корректности решения, а не только на традиционных сигналах вознаграждения. В отличие от стандартного обучения с подкреплением, где вознаграждение может быть субъективным или неточно отражать желаемый результат, RLVR использует алгоритмы проверки для определения, является ли каждый шаг рассуждений логически верным. Это позволяет LLM обучаться более надежным и интерпретируемым способам принятия решений, поскольку акцент делается на подтверждаемой точности, а не на статистической вероятности генерации «хорошего» ответа. В результате, RLVR стремится создать модели, способные не только давать правильные ответы, но и демонстрировать логическую последовательность в процессе их получения.
Для эффективного обучения больших языковых моделей (LLM) в рамках RLVR используются алгоритмы оптимизации, такие как Group Relative Policy Optimization (GRPO) и DAPO. GRPO позволяет улучшать политику модели, сравнивая ее производительность с группой других политик, что повышает стабильность и скорость обучения. DAPO (Direct Advantage Policy Optimization) напрямую оптимизирует политику, используя оценку преимущества, что обеспечивает более эффективное использование данных. Ключевым элементом является применение разреженных наград (Sparse Rewards) — вознаграждение предоставляется только за полностью корректные решения, что стимулирует модель к поиску оптимальной последовательности логических шагов и снижает потребность в большом количестве размеченных данных.
Основная концепция RLVR заключается в направленном обучении языковой модели последовательности логически корректных шагов рассуждений. Вместо оптимизации на основе общих оценок, RLVR фокусируется на проверке каждого этапа вывода на соответствие логическим правилам и фактам. Такой подход позволяет не только повысить надежность и точность принимаемых решений, но и обеспечить возможность интерпретации процесса рассуждений модели, выявляя, как именно она пришла к определенному выводу. Это существенно отличает RLVR от традиционных методов обучения, где процесс принятия решений часто представляет собой «черный ящик», и позволяет создавать более прозрачные и контролируемые системы искусственного интеллекта.
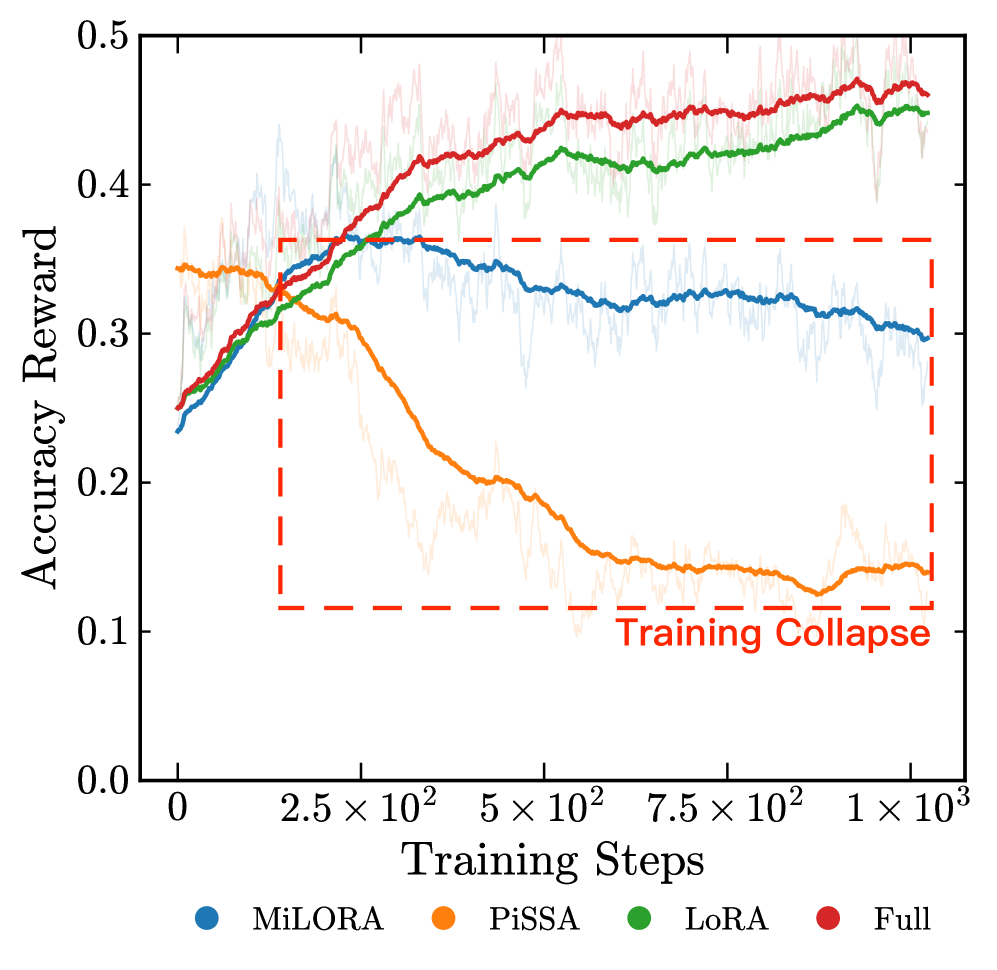
PEFT-стратегии для эффективного обучения RLVR
В рамках RLVR для снижения количества обучаемых параметров применяются различные методы PEFT (Parameter-Efficient Fine-Tuning), включая LoRA (Low-Rank Adaptation), DoRA (Dynamic Rank Adaptation), AdaLoRA, MiSS (Minimum Singular Value Decomposition), PiSSA (Prefix-tuning with Sparse Self-Attention) и VeRA. Эти методы позволяют обновлять лишь подмножество весов предобученной модели, что существенно снижает вычислительные затраты и требования к памяти, сохраняя при этом возможность адаптации к новым задачам. В отличие от полной перенастройки всех параметров модели, PEFT-методы фокусируются на обучении небольшого количества дополнительных параметров, что делает процесс обучения более эффективным и масштабируемым.
Методы параметрно-эффективной тонкой настройки (PEFT) повышают эффективность обучения больших языковых моделей за счет обновления лишь части от общего числа весов модели. Это достигается путем введения небольшого количества обучаемых параметров, в то время как основная часть модели остается замороженной. В результате значительно сокращается объем вычислительных ресурсов и памяти, необходимых для обучения, что позволяет ускорить процесс и обучать модели на оборудовании с ограниченными ресурсами. Сокращение числа обучаемых параметров также снижает риск переобучения, особенно при работе с небольшими наборами данных.
Алгоритм DAPO повышает эффективность обучения за счет применения динамической выборки данных и оптимизации размера пакета (Batch Size). Динамическая выборка позволяет фокусироваться на наиболее информативных данных в процессе обучения, снижая вычислительные затраты и ускоряя сходимость. Оптимизация размера пакета, в свою очередь, позволяет более эффективно использовать ресурсы памяти и процессора, что особенно важно при работе с большими языковыми моделями и ограниченными вычислительными ресурсами. Комбинация этих техник позволяет достичь значительного снижения затрат на обучение без потери точности модели.
В ходе экспериментов с RLVR, метод DoRA продемонстрировал превосходство над полнопараметрической тонкой настройкой, достигнув точности 46.6% против 44.9% соответственно. Стандартный LoRA показал точность 42.5%. Эти результаты подтверждают эффективность применения PEFT-стратегий для снижения вычислительных затрат и повышения производительности при обучении больших языковых моделей в задачах RLVR, при этом обеспечивая сопоставимые или даже улучшенные показатели точности по сравнению с традиционными методами тонкой настройки.
Смягчение нестабильности и максимизация влияния
Методы, такие как PiSSA, направлены на борьбу со спектральным коллапсом — явлением, при котором сингулярные значения весовых матриц становятся чрезмерно концентрированными. Это приводит к снижению выразительности модели и, как следствие, к ухудшению её способности к обучению и обобщению. В процессе обучения глубоких нейронных сетей, особенно в задачах обучения с подкреплением, весовые матрицы могут подвергаться изменениям, которые приводят к доминированию нескольких сингулярных значений над остальными. Такая концентрация информации сужает «пространство возможностей» модели, ограничивая её способность к эффективной обработке сложных данных и решению разнообразных задач. PiSSA, в частности, стремится предотвратить эту концентрацию, поддерживая более равномерное распределение сингулярных значений и, таким образом, сохраняя способность модели к сложному рассуждению и адаптации.
Тщательная инициализация и последовательное обновление весов в современных моделях машинного обучения направлены на сохранение способности к сложному рассуждению. Эти методы позволяют избежать явления спектрального коллапса, при котором концентрация сингулярных значений весовых матриц ограничивает обучаемость модели. Поддерживая широкий спектр значений, система способна эффективно обрабатывать и усваивать сложные зависимости в данных, что критически важно для решения задач, требующих не просто распознавания образов, а глубокого понимания и логического вывода. Именно благодаря такому подходу модели сохраняют гибкость и адаптируемость, необходимые для достижения высоких результатов в различных областях, от обработки естественного языка до решения математических задач.
Внедрение штрафа Кульбака-Лейблера (KL Penalty), особенно в алгоритмах вроде DAPO, значительно повышает стабильность процесса обучения. Этот механизм предотвращает резкие отклонения от предыдущих политик модели, что позволяет избежать нежелательных скачков в параметрах и сохранить согласованность обучения. По сути, KL Penalty действует как регуляризатор, ограничивающий изменения в распределении вероятностей, предсказываемых моделью, и тем самым предотвращая потерю накопленных знаний и обеспечивая более плавную и предсказуемую сходимость. Такой подход особенно важен в задачах, где критически важна непрерывность обучения и сохранение ранее приобретенных навыков, что позволяет модели более эффективно адаптироваться к новым данным и избегать катастрофического забывания.
Результаты тестирования на стандартных наборах данных выявили значительные различия в эффективности различных подходов. Алгоритм DoRA продемонстрировал впечатляющие показатели, достигнув точности в 83.1% на бенчмарке AMC и 38.7% на AIME25. Однако, применение PiSSA привело к резкому снижению производительности, зафиксировав точность лишь в 0.2%. Данное расхождение подчеркивает важность корректной инициализации и обновления весов в процессе обучения, а также указывает на потенциальные проблемы, связанные с конкретной реализацией PiSSA, приводящие к коллапсу производительности и утрате способности к сложному рассуждению.
Исследование показывает, что стандартные подходы к параметрически-эффективной настройке, такие как LoRA, могут оказаться неоптимальными в контексте обучения с подкреплением и проверяемыми наградами (RLVR). Вместо этого, структурные варианты, вроде DoRA, демонстрируют превосходство, обходя LoRA и даже полную настройку параметров. Это подтверждает, что архитектурные решения — не просто инструменты, а пророчества о будущих сбоях. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что мы не знаем». Подобно этому, эффективность адаптеров в RLVR указывает на то, что понимание динамики оптимизации и соответствие архитектуры задаче — ключевые факторы успеха, а не просто слепое применение существующих методов.
Что дальше?
Представленные результаты, конечно, демонстрируют превосходство структурных вариантов тонкой настройки над наивным LoRA в контексте обучения с проверяемыми наградами. Но не стоит обманываться кажущимся успехом. Каждая новая архитектура, обещающая оптимизацию, лишь отодвигает неизбежный момент DevOps-жертвоприношений. Проблема не в параметрах, а в самой природе оптимизации — в поиске равновесия между гибкостью и стабильностью. Неудачи SVD-инициализации — лишь напоминание о том, что любой старт, навязанный извне, может оказаться несовместимым с динамикой обучения.
По-настоящему интересным представляется не поиск идеального метода тонкой настройки, а изучение причин, по которым стандартные подходы терпят крах. Возможно, дело в специфике пространства наград, в нелинейности обратной связи, или в самой парадигме обучения с подкреплением. В конечном итоге, порядок — это лишь временный кэш между сбоями, и любое упрощение, направленное на повышение эффективности, неизбежно ведет к новым, неожиданным формам хаоса.
Будущие исследования должны сосредоточиться не на создании более совершенных инструментов, а на понимании принципов, лежащих в основе адаптации и обобщения. Экосистемы, а не инструменты — вот что действительно важно. И задача исследователя — не строить их, а наблюдать за их эволюцией, пытаясь уловить закономерности в кажущемся хаосе.
Оригинал статьи: https://arxiv.org/pdf/2512.23165.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Квантовые нейросети на службе нефтегазовых месторождений
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые прорывы: Хорошее, плохое и смешное
2025-12-31 13:54