Автор: Денис Аветисян
Новая архитектура объединяет возможности понимания, генерации и редактирования мультимодальных данных в единую систему.
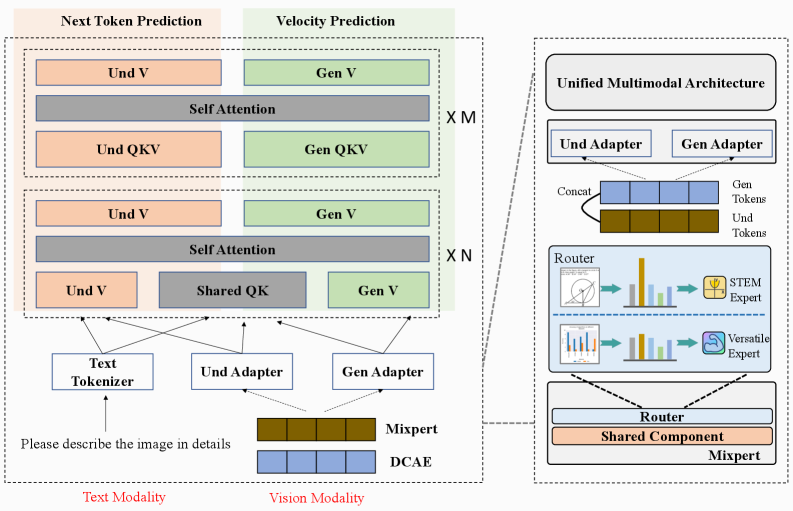
Представлена EMMA — унифицированная архитектура, эффективно сжимающая визуальную информацию и достигающая передовых результатов в задачах мультимодального обучения благодаря раздельной и совместной обработке данных.
Несмотря на значительный прогресс в области мультимодального обучения, создание единой архитектуры, эффективно справляющейся с пониманием, генерацией и редактированием данных, остается сложной задачей. В данной работе представлена EMMA (‘EMMA: Efficient Multimodal Understanding, Generation, and Editing with a Unified Architecture’), новая архитектура, обеспечивающая высокую производительность за счет эффективной компрессии визуальной информации и использования принципа раздельно-совместной сети. Эксперименты демонстрируют, что EMMA-4B превосходит современные мультимодальные подходы по эффективности и производительности, достигая конкурентоспособных результатов в задачах понимания и генерации. Способна ли данная архитектура стать основой для дальнейшего развития унифицированных мультимодальных систем и открыть новые горизонты в области искусственного интеллекта?
Понимание Системы: Открытие Новых Горизонтов Мультимодального Анализа
Традиционные подходы к обработке визуальной и текстовой информации зачастую сталкиваются с трудностями при их совместном анализе, что ограничивает возможности полноценного понимания. В большинстве случаев, визуальные и текстовые данные обрабатываются отдельными моделями, требующими сложных механизмов для обмена информацией. Такое разделение приводит к потере важных связей между модальностями, поскольку модели не способны эффективно учитывать контекст, предоставляемый обеими формами данных одновременно. Например, понимание изображения, содержащего текст, требует интеграции визуальной информации о форме букв и текстовой информации о значении слов. Неспособность к такой интеграции приводит к неполному или ошибочному пониманию, что особенно критично в задачах, требующих глубокого анализа, таких как понимание естественного языка, ответы на вопросы и генерация описаний изображений. Это подчеркивает необходимость разработки новых архитектур, способных эффективно объединять и обрабатывать различные типы данных.
Растущий спрос на модели, способные одновременно понимать и генерировать контент в различных модальностях, обусловлен расширением возможностей искусственного интеллекта за пределы обработки только текста или изображений. Современные задачи, такие как автоматическое создание подписей к изображениям, визуальный вопрос-ответ и генерация мультимедийных презентаций, требуют систем, способных эффективно объединять информацию из разных источников. Умение модели понимать взаимосвязи между текстом, изображениями, звуком и другими типами данных открывает перспективы для создания более интеллектуальных и адаптивных систем, способных к более глубокому взаимодействию с окружающим миром и удовлетворению сложных потребностей пользователей. В связи с этим, разработка архитектур, позволяющих эффективно обрабатывать и комбинировать данные различных модальностей, является ключевым направлением в современных исследованиях в области искусственного интеллекта и машинного обучения.
Единые мультимодальные архитектуры представляют собой перспективное решение для задач, требующих одновременной обработки и понимания данных различных модальностей, таких как текст и изображения. В отличие от традиционных подходов, где каждая модальность обрабатывается независимо, эти архитектуры используют общие параметры и устанавливают связи между различными типами данных. Это позволяет модели не просто комбинировать информацию, но и извлекать более глубокие, контекстуально значимые представления. Например, общие слои внимания позволяют модели соотносить слова в текстовом описании с соответствующими областями на изображении, что значительно улучшает понимание и генерацию контента. Такой подход не только повышает эффективность и точность, но и способствует созданию более компактных и универсальных моделей, способных к решению широкого спектра задач, от автоматического описания изображений до визуального ответа на вопросы.

EMMA: Совместное и Раздельное Обработка для Мультимодального Искусственного Интеллекта
Архитектура EMMA представляет собой новый подход к построению мультимодальных моделей искусственного интеллекта, основанный на принципе совместного использования параметров с одновременным их разделением. Это достигается за счет реализации общей базы параметров, которая используется несколькими специализированными модулями (экспертами). Такой подход позволяет значительно снизить общее количество параметров модели, повышая ее эффективность и масштабируемость, при этом сохраняя или даже улучшая производительность в различных задачах. Разделение параметров позволяет каждому эксперту специализироваться на определенном аспекте обработки данных, обеспечивая гибкость и адаптивность модели к разнообразным входным сигналам и типам задач.
Модель EMMA использует высококомпрессирующий автоэнкодер (DCAE) для эффективного кодирования визуальной информации, что позволяет значительно уменьшить размер входных данных и снизить вычислительные затраты. DCAE преобразует изображения в компактное представление, сохраняя при этом ключевые визуальные характеристики. Для динамического выбора наиболее подходящих экспертов для обработки различных входных данных используется модуль Router. Этот модуль анализирует закодированное визуальное представление и направляет его к определенным экспертам, специализирующимся на конкретных аспектах изображения, обеспечивая тем самым адаптацию к различным типам визуального контента и повышение эффективности обработки.
Для улучшения взаимодействия между модальностями в архитектуре EMMA используются методы конкатенации по каналам и гибридная стратегия внимания. Конкатенация по каналам позволяет объединять признаки из различных модальностей на уровне каналов, что обеспечивает более эффективное представление информации. Гибридная стратегия внимания комбинирует механизмы самовнимания и внимания между модальностями, позволяя модели динамически определять, какие части входных данных наиболее важны для текущей задачи. В частности, самовнимание обрабатывает зависимости внутри каждой модальности, а межмодальное внимание фокусируется на корреляции между ними, что приводит к более точному и контекстно-зависимому представлению данных. Такой подход позволяет эффективно интегрировать информацию из различных источников, повышая общую производительность модели в задачах, требующих мультимодального анализа.

Оптимизация Обучения и Восприятия в EMMA: Путь к Глубокому Пониманию
В архитектуре EMMA для повышения качества понимания и генерации используется комбинация методов Next-Token Prediction и Flow Matching. Next-Token Prediction, предсказывая следующий токен в последовательности, позволяет модели более эффективно улавливать зависимости в данных и улучшает её способность к пониманию контекста. Flow Matching, в свою очередь, оптимизирует процесс генерации, обеспечивая более плавный и когерентный вывод, что особенно важно для задач, требующих высокой степени реалистичности и соответствия заданным условиям. Данный подход позволяет достичь высокого качества генерируемых результатов и стабильной работы модели в различных сценариях.
Модель EMMA использует RoPE (Rotary Positional Embeddings) для кодирования пространственных отношений между элементами входной последовательности, что позволяет ей эффективно учитывать контекст и расположение объектов. Для повышения способности к визуальному восприятию используется SigLIP2, архитектура, оптимизированная для обработки изображений. SigLIP2 дополнительно усиливается за счет использования Mixpert, что позволяет модели более точно интерпретировать визуальную информацию и улучшает качество генерируемых изображений. Комбинация RoPE и SigLIP2 с Mixpert обеспечивает надежную обработку и понимание пространственных и визуальных данных.
Модели EMU3 и D-DiT обеспечивают согласованность оптимизации в рамках унифицированной архитектуры EMMA. EMU3, использующая алгоритм диффузионных моделей, позволяет оптимизировать процесс обучения, а D-DiT (Differentiable Diffusion with Iterative Training) способствует стабильности и надёжности генерации изображений. Совместное использование этих подходов обеспечивает консистентность при обучении различных компонентов модели, предотвращая расхождения и обеспечивая предсказуемые результаты. Данная комбинация улучшает общую производительность системы, снижает потребность в тонкой настройке и повышает устойчивость к изменениям входных данных.
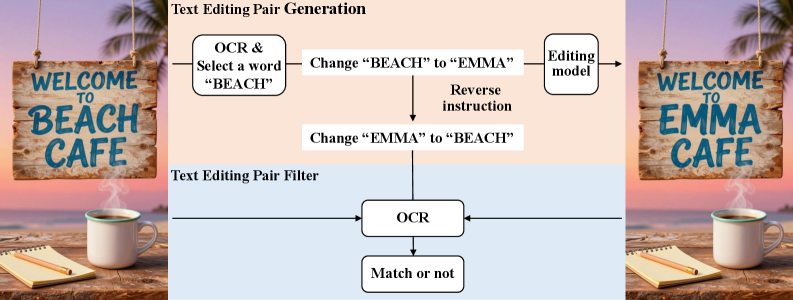
Производительность и Масштабируемость: Подтверждение Потенциала EMMA
Модель EMMA демонстрирует конкурентоспособные результаты на эталонных тестах, включая GenEval, где она достигла показателя 0.91 без использования перефразировки запросов или обучения с подкреплением. Этот результат превосходит показатели моделей BAGEL-7B (0.82) и Qwen-Image (0.87) при аналогичных условиях тестирования. Данный факт подтверждает эффективность архитектуры EMMA и её способность к выполнению задач мультимодального анализа и генерации без применения дополнительных методов оптимизации запросов или обучения с подкреплением.
Модель EMMA демонстрирует адаптивность, расширяя функциональные возможности существующих архитектур, таких как Qwen3-VL и InternVL3.5. Это достигается за счет интеграции новых методов и оптимизаций, позволяющих использовать преимущества этих базовых моделей, одновременно улучшая их производительность в различных задачах мультимодального анализа и генерации. В частности, EMMA использует и модифицирует компоненты Qwen3-VL и InternVL3.5 для улучшения обработки визуальной информации и повышения эффективности генерации ответов, что подтверждается результатами тестов на различных наборах данных.
Модель EMMA демонстрирует результат в 73.0 балла по бенчмарку MMVet, используя языковую модель размером 4 миллиарда параметров. Этот показатель превосходит результат, достигнутый моделью BAGEL-7B, которая набрала 67.2 балла в том же тесте. Бенчмарк MMVet предназначен для оценки мультимодального понимания и рассуждений, что подтверждает способность EMMA эффективно обрабатывать и анализировать визуальную информацию в сочетании с текстовыми данными.
В ходе выполнения задач по редактированию изображений, EMMA демонстрирует значительное повышение эффективности по сравнению с моделью BAGEL. В частности, EMMA достигает 5-кратного сокращения количества визуальных токенов, необходимых для обработки изображения. Это указывает на более оптимальное использование вычислительных ресурсов и потенциально более высокую скорость обработки, что делает EMMA более эффективным решением для приложений, требующих редактирования изображений в реальном времени или обработки больших объемов визуальных данных.
В ходе оценки понимания, модель EMMA демонстрирует среднее увеличение производительности на 0.4% по 11 различным оценочным наборам данных при использовании архитектуры Mixture of Experts (MoE). При сравнении с моделью InternVL3.5, EMMA показывает прирост в 2.6% по этим же наборам данных, что свидетельствует о более высокой эффективности в задачах понимания визуальной информации и генерации ответов. Данные результаты подтверждают способность EMMA к более точному анализу и интерпретации входных данных.
Модель EMMA использует масштабные наборы данных, такие как LLaVA-558K и LAION, для предварительного обучения и генерации контента. Набор данных LLaVA-558K содержит 558 тысяч пар изображений и текстовых описаний, обеспечивая обширную базу для обучения понимания визуальной информации. LAION, в свою очередь, представляет собой еще более крупный набор данных, состоящий из миллиардов пар изображение-текст, полученных из сети Интернет. Использование этих крупных и разнообразных наборов данных позволяет EMMA достигать высокой производительности и надежности в задачах, связанных с обработкой изображений и естественным языком.
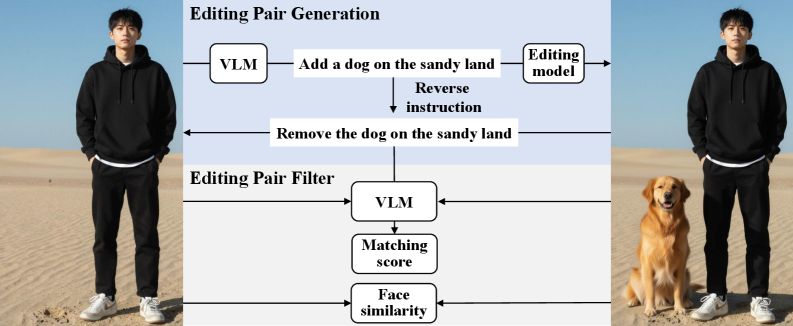
Будущие Направления: Расширение Горизонтов Мультимодального Искусственного Интеллекта
Архитектура EMMA, благодаря своей гибкости, открывает новые горизонты в таких областях, как редактирование изображений и решение сложных задач, требующих логического мышления. Эта система позволяет не просто распознавать объекты на изображениях, но и манипулировать ими, выполняя сложные преобразования по заданным параметрам. Более того, EMMA демонстрирует значительный прогресс в задачах, требующих не только визуального анализа, но и понимания контекста и установления логических связей между различными элементами. Потенциал этой архитектуры заключается в создании интеллектуальных инструментов, способных к творческой деятельности и решению проблем, которые ранее были доступны только человеку, что делает её важным шагом на пути к более продвинутым системам искусственного интеллекта.
Дальнейшие исследования направлены на интеграцию специализированных модулей, именуемых “STEM Expert”, в архитектуру мультимодальных систем искусственного интеллекта. Эти модули, обладающие углубленными знаниями в конкретных областях науки, техники, инженерии и математики, способны значительно повысить эффективность решения сложных задач, требующих экспертного уровня понимания. Например, модуль, специализирующийся на материаловедении, позволит системе более точно анализировать изображения микроструктур материалов или прогнозировать их свойства. Внедрение подобных экспертных блоков позволит преодолеть ограничения существующих моделей, расширив сферу их применения и открыв новые возможности для инноваций в различных отраслях, от медицины и энергетики до разработки новых материалов и технологий.
Разработка более эффективных и масштабируемых архитектур, подобных EMMA, открывает принципиально новые горизонты во взаимодействии человека и компьютера, а также в области искусственного интеллекта, способного к творчеству. По мере увеличения вычислительных мощностей и оптимизации алгоритмов, подобные системы смогут обрабатывать значительно большие объемы данных и решать более сложные задачи, требующие креативного подхода. Это позволит создавать инструменты для автоматизированной генерации контента — от визуального искусства и музыки до литературных произведений и научных гипотез — расширяя возможности человека и стимулируя инновации в различных сферах деятельности. Подобные архитектуры также способствуют созданию более интуитивно понятных и адаптивных интерфейсов, позволяющих пользователям взаимодействовать с искусственным интеллектом на качественно новом уровне, приближая реализацию концепции действительно интеллектуальных помощников и творческих партнеров.
Исследование, представленное в данной работе, демонстрирует важность эффективного сжатия визуальной информации для достижения передовых результатов в мультимодальном обучении. Архитектура EMMA, использующая подход сжатия и разделения, позволяет эффективно решать задачи понимания, генерации и редактирования данных. Как отмечал Эндрю Ын: «Мы должны быть осторожны с тем, как мы используем данные, потому что в конечном итоге это определит, сможем ли мы построить действительно полезные системы». Эта фраза прекрасно иллюстрирует суть работы: оптимизация использования данных, в данном случае визуальной информации, является ключевым фактором для создания мощных и универсальных мультимодальных моделей, способных к глубокому пониманию и генерации контента.
Что дальше?
Представленная архитектура EMMA демонстрирует впечатляющую способность к сжатию и обработке визуальной информации, однако, как это часто бывает, решение одной задачи неизбежно выявляет новые горизонты для исследований. Замечается, что эффективность модели тесно связана с качеством кодирования визуальных данных. Следующим шагом видится разработка более устойчивых к шумам и артефактам методов визуального представления, а также исследование возможности адаптации архитектуры к данным с более высоким разрешением — ведь детали, как известно, имеют значение.
Особый интерес представляет вопрос о расширении возможностей EMMA в области причинно-следственного анализа. Способность генерировать и редактировать изображения — это, безусловно, впечатляюще, но понимание почему изображение изменяется определённым образом, а не просто как это происходит, открывает путь к созданию действительно интеллектуальных систем. Быстрые выводы о функциональности могут скрывать структурные ошибки в понимании контекста.
Наконец, следует признать, что архитектура, основанная на смеси экспертов, требует значительных вычислительных ресурсов. Поиск компромисса между производительностью и эффективностью — это вечная проблема, и дальнейшие исследования в области квантизации и дистилляции знаний, вероятно, окажутся ключевыми для внедрения подобных моделей в реальные приложения. Понимание системы — это исследование её закономерностей, и в этом процессе нет места самоуспокоенности.
Оригинал статьи: https://arxiv.org/pdf/2512.04810.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-09 06:27