Автор: Денис Аветисян
Новый подход к поиску и генерации ответов позволяет системам искусственного интеллекта более эффективно работать с длинными и сложными текстами, извлекая из них глубокий смысл.
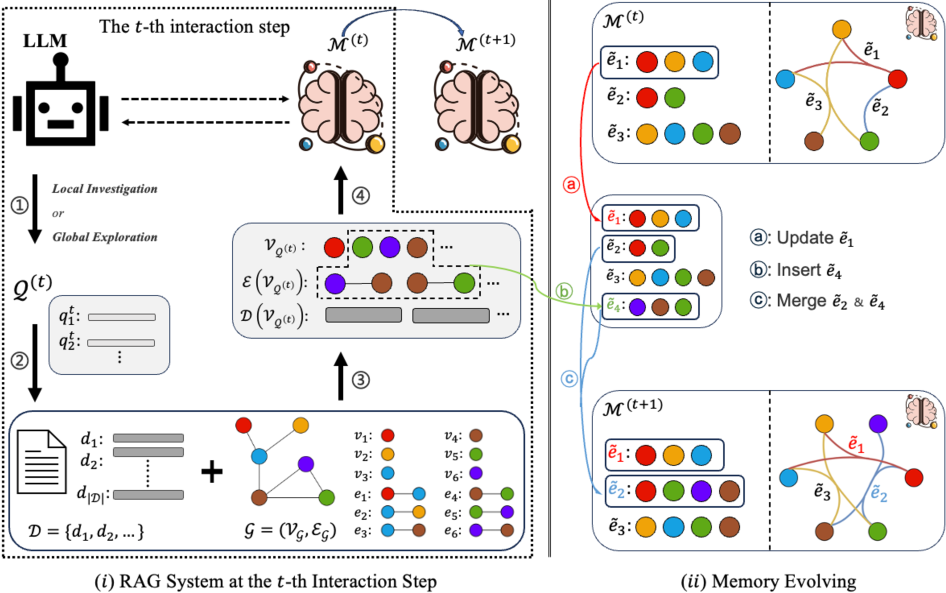
В статье представлена Hypergraph Memory (HGMem) — инновационная архитектура памяти, использующая гиперграфы для многоступенчатого извлечения и генерации, позволяющая улучшить моделирование связей и понимание контекста.
Несмотря на успехи многошагового поиска и генерации (RAG) в задачах, требующих глобального понимания, существующие подходы к организации рабочей памяти часто ограничиваются пассивным хранением изолированных фактов. В данной работе, ‘Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling’, предлагается механизм HGMem — память на основе гиперграфов, позволяющая динамически формировать связи между фактами и знаниями для более глубокого анализа и понимания длинных контекстов. HGMem представляет память как гиперграф, где связи между элементами отражают сложные взаимосвязи, обеспечивая более эффективное моделирование отношений и улучшение многошагового рассуждения. Способствует ли такое представление знаний созданию более интеллектуальных систем RAG, способных к комплексному осмыслению информации и решению сложных задач?
Преодолевая Ограничения: Поиск Контекста за Пределами Простого Извлечения
Традиционные методы поиска информации часто сталкиваются с трудностями при обработке больших объемов текста и сложных запросов. Существующие системы, как правило, фокусируются на поиске ключевых слов и фраз, упуская из виду более тонкие связи и контекстуальные нюансы. В результате, даже если релевантные документы найдены, система может не суметь установить взаимосвязь между различными частями информации, что приводит к неполным или неточным ответам. Эта проблема особенно актуальна в ситуациях, требующих глубокого понимания контекста, например, при анализе юридических документов или научных исследований, где пропуск даже незначительной детали может существенно исказить смысл.
Несмотря на впечатляющую беглость речи и способность генерировать связные тексты, современные большие языковые модели демонстрируют ограниченные возможности в области надежного, многоступенчатого рассуждения и истинного понимания контекста. Они, по сути, превосходно оперируют статистическими закономерностями в данных, но им недостает встроенных механизмов для глубокого анализа ситуаций, выявления скрытых связей и последовательного применения логических выводов. Модели могут успешно отвечать на простые вопросы, но часто терпят неудачу при решении задач, требующих интеграции разрозненной информации, учета неявных предположений или адаптации к новым, непредсказуемым обстоятельствам. В результате, даже обладая обширными знаниями, они не всегда способны к адекватному пониманию нюансов и тонкостей реального мира, что ограничивает их применение в сложных областях, требующих критического мышления и способности к принятию обоснованных решений.
Для эффективного рассуждения недостаточно простого доступа к информации; ключевым является способность интегрировать её и формировать целостное понимание ситуации. Исследования показывают, что даже обладая обширными знаниями, системы испытывают трудности при установлении связей между разрозненными фактами, если отсутствует механизм для их синтеза. Процесс интеграции предполагает не только выявление релевантных данных, но и установление логических связей, выявление противоречий и формирование последовательного объяснения. Способность к такому синтезу позволяет не просто отвечать на вопросы, но и прогнозировать последствия, оценивать риски и принимать обоснованные решения, что является признаком истинного понимания, а не простого поиска соответствий.
RAG: Организация Знаний и Генерация Ответов
Системы генерации с расширенным поиском (RAG) объединяют возможности предварительно обученных языковых моделей с динамическим доступом к внешним источникам знаний. Это позволяет преодолеть ограничения, связанные с фиксированным объемом информации, заложенным в модель во время обучения. Вместо того, чтобы полагаться исключительно на собственные знания, RAG системы извлекают релевантную информацию из внешних баз данных или документов непосредственно во время генерации ответа. Такой подход повышает точность, актуальность и обоснованность генерируемого текста, а также позволяет модели отвечать на вопросы, требующие знаний, которые изначально отсутствовали в ее обучающей выборке. В результате, RAG системы демонстрируют повышенную гибкость и адаптивность к новым данным и задачам.
В основе систем RAG лежит генерация подзапросов для эффективного извлечения релевантной информации из графоподобных структур данных. Вместо прямого поиска по всей базе знаний, LLM формирует последовательность специализированных запросов, ориентированных на конкретные аспекты исходного вопроса. Эти подзапросы позволяют более точно локализовать узлы и связи в графе, содержащие необходимые сведения. Полученные результаты агрегируются и используются для формирования ответа, что существенно повышает релевантность и точность генерируемого текста по сравнению с системами, использующими только внутренние знания языковой модели.
Процесс, лежащий в основе систем RAG, обеспечивается большой языковой моделью (LLM), которая выполняет две ключевые функции. Во-первых, LLM генерирует поисковые запросы, необходимые для извлечения релевантной информации из внешних источников. Во-вторых, полученные фрагменты данных консолидируются LLM в связный и логичный ответ на исходный запрос пользователя. Эта консолидация включает в себя не только простое объединение информации, но и ее структурирование, устранение противоречий и адаптацию к контексту исходного вопроса, что позволяет формировать более точные и полные ответы, чем это было бы возможно при использовании только LLM без доступа к внешним данным.

Динамическая Память на Основе Гиперграфов
Для поддержания контекста при выполнении последовательных операций используется эффективная рабочая память, реализованная посредством структуры гиперграфа. В отличие от обычных графов, гиперграфы позволяют устанавливать связи между более чем двумя узлами, формируя гиперребра. Это позволяет системе представлять сложные взаимосвязи между различными элементами информации, учитывая их множественные зависимости. Каждый узел в гиперграфе представляет собой сущность или концепцию, а гиперребра — отношения между ними, что обеспечивает более полное и контекстуально-обогащенное представление данных по сравнению с традиционными структурами данных.
Гиперграфы, в отличие от традиционных графов, позволяют моделировать связи между более чем двумя сущностями одновременно. В то время как обычный граф описывает отношения между парами узлов, гиперграф может представлять связи между любым количеством узлов посредством гиперребер. Это особенно важно для представления сложных зависимостей в данных, где взаимосвязь может охватывать несколько элементов одновременно. Например, предложение «А, Б и В работают над проектом Г» может быть представлено гиперребром, соединяющим сущности А, Б, В и Г, отражая их совместную работу. Такое представление позволяет системе эффективно обрабатывать и извлекать информацию о сложных взаимосвязях, которые не могут быть адекватно описаны с помощью стандартных графовых структур.
Динамическая память системы обновляется посредством операций вставки, слияния и обновления, что позволяет ей уточнять понимание ситуации по мере получения новой информации. Этот процесс проявляется в увеличении среднего количества сущностей на гиперребро (Avg-Nv) в запросах, направленных на осмысление ситуации. Увеличение Avg-Nv свидетельствует о том, что система эффективно объединяет большее количество связанных данных в единую структуру, отражая более глубокое понимание контекста и взаимосвязей между элементами информации. Данные операции позволяют системе адаптироваться к изменяющимся условиям и формировать более точные и полные представления о происходящем.

Адаптивное Извлечение Доказательств для Надежного Рассуждения
Для повышения эффективности и точности, разработанная система извлечения информации на основе RAG использует адаптивный подход к поиску доказательств, объединяя локальное исследование с глобальным анализом. Локальное исследование фокусируется на конкретных точках памяти для получения детальной информации, необходимой для ответа на запрос. В то же время, глобальное исследование расширяет область поиска, выявляя скрытые связи и контекст, которые могут быть упущены при узкоспециализированном поиске. Такое сочетание позволяет системе не только быстро находить релевантные данные, но и формировать более полное и обоснованное заключение, что особенно важно при решении сложных вопросов и построении логических цепочек рассуждений.
Локальное исследование и глобальное расширение поиска представляют собой ключевой аспект эффективного извлечения информации. Локальное исследование фокусируется на конкретных точках памяти, позволяя получить детальные сведения о релевантных фактах и взаимосвязях. В то же время, глобальное расширение поиска выходит за рамки непосредственной релевантности, охватывая более широкий спектр данных для выявления скрытых связей и контекста, которые могут быть упущены при узконаправленном поиске. Такое сочетание позволяет системе не только отвечать на прямые вопросы, но и делать обоснованные выводы, опираясь на более полное понимание предметной области и выявляя неочевидные закономерности.
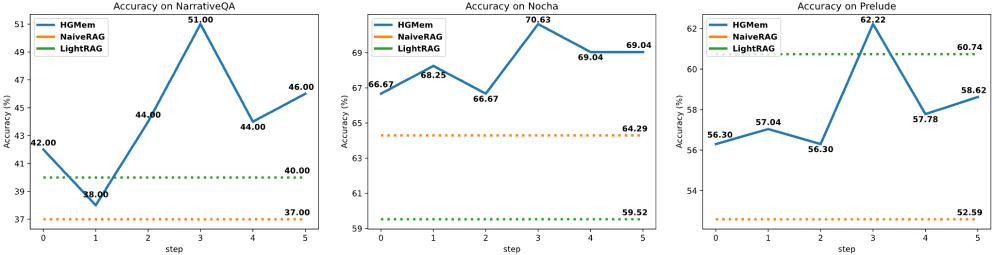
Разработанный механизм гиперграфовой памяти (HGMem) демонстрирует стабильное превосходство над существующими системами, такими как DeepRAG и LightRAG, в задачах, требующих сложного логического вывода. Оценка производительности на специализированных наборах данных, включая NarrativeQA, Nocha и Prelude, последовательно подтверждает более высокую точность и эффективность HGMem при обработке комплексных запросов. Этот результат указывает на то, что использование гиперграфовой структуры позволяет системе более эффективно извлекать и интегрировать релевантную информацию, что, в свою очередь, значительно улучшает её способность к логическому мышлению и предоставлению точных ответов на сложные вопросы.

Представленная работа демонстрирует стремление к математической чистоте в организации информации, что находит отражение в использовании гиперграфов для моделирования связей. Подход, предложенный авторами, направлен на создание доказуемо корректного механизма извлечения и генерации знаний, особенно в условиях работы с длинным контекстом. В этом контексте, как однажды заметил Анри Пуанкаре: «Наука не состоит из ряда истин, открытых раз и навсегда, а из методов». Данный метод, Hypergraph Memory, действительно, представляет собой элегантное решение, позволяющее эффективно организовать и использовать знания, что крайне важно для сложных задач, требующих глубокого понимания взаимосвязей между элементами информации.
Куда же дальше?
Представленная работа, несомненно, демонстрирует элегантность подхода к моделированию связей в длинных контекстах посредством гиперграфов. Однако, как и любое решение, оно лишь отодвигает проблему, а не уничтожает её. Вопрос не в том, насколько хорошо система помнит информацию, а в том, насколько точно она определяет её релевантность и необходимость в конкретный момент. Иными словами, чистота алгоритма должна подтверждаться его способностью к дедуктивному выводу, а не просто к статистическому сопоставлению.
Будущие исследования, вероятно, сосредоточатся на формализации понятия «смысла» для алгоритмов. Построение гиперграфа — это лишь представление структуры знаний, но не гарантия её истинного понимания. Необходимо исследовать возможности интеграции логических правил и формальных систем в архитектуру памяти, чтобы обеспечить не просто хранение фактов, а их осмысленную интерпретацию. Особенно актуальным представляется вопрос о самообучающихся системах, способных к автоматическому выявлению и формализации логических связей.
В конечном счете, успех подобного подхода будет зависеть от его способности выйти за рамки простого «рабочего» решения и приблизиться к созданию системы, способной к подлинному интеллектуальному анализу. Это не вопрос увеличения вычислительных мощностей, а вопрос математической строгости и концептуальной ясности. Простота — высшая форма сложности, и только чистый, доказуемый алгоритм может претендовать на звание действительно эффективного.
Оригинал статьи: https://arxiv.org/pdf/2512.23959.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Робот, который видит, понимает и действует: новая эра общего назначения
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-02 17:58