Автор: Денис Аветисян
Исследование демонстрирует, как современные языковые модели могут эффективно управлять экспериментами в материаловедении, предлагая гибкую альтернативу традиционным методам машинного обучения.

Предложена методика активного обучения без необходимости обучения моделей, использующая большие языковые модели для оптимизации поиска новых материалов.
Традиционные подходы к ускорению научных открытий в материаловедении часто требуют значительных усилий по разработке признаков и страдают от проблем «холодного старта». В работе ‘Training-Free Active Learning Framework in Materials Science with Large Language Models’ предложен новый подход, использующий большие языковые модели (LLM) для активного обучения без предварительного обучения, напрямую оперируя текстовыми описаниями материалов. Показано, что LLM-AL позволяет снизить количество необходимых экспериментов для достижения оптимальных результатов более чем на 70% и превосходит традиционные методы машинного обучения по эффективности поиска. Может ли эта гибкая и интерпретируемая система стать основой для автономных циклов открытия новых материалов?
Предел Совершенства: Трудности Открытия Новых Материалов
Исторически, открытие новых материалов являлось длительным, затратным и зачастую зависело от случайных открытий или исчерпывающих, но неэффективных экспериментов. Традиционный подход предполагает синтез и тестирование множества соединений, что требует значительных временных и финансовых ресурсов. Ученым приходилось полагаться на интуицию и опыт, а не на систематический анализ данных, что замедляло процесс инноваций. Такой метод часто приводил к тому, что перспективные материалы оставались незамеченными, а ресурсы тратились впустую на неэффективные соединения. Отсутствие предсказуемости и высокая стоимость экспериментов создавали серьезные препятствия для развития материаловедения, стимулируя поиск более эффективных и целенаправленных подходов к открытию новых материалов.
Пространство материалов чрезвычайно обширно, что делает систематический, основанный на данных подход к их открытию не просто желательным, но и необходимым. Традиционно, для достижения оптимальных результатов требовалось исследовать значительную часть этого пространства, что было связано с колоссальными вычислительными затратами. Однако, представленная работа демонстрирует, что применение методологии LLM-AL (Language Model-Active Learning) позволяет находить наиболее перспективные кандидаты, используя менее 30% данных в большинстве исследуемых наборов. Это значительно снижает вычислительную нагрузку и ускоряет процесс открытия новых материалов с заданными свойствами, открывая возможности для более эффективных и целенаправленных исследований в материаловедении.

Активное Обучение: Умный Поиск в Хаосе
Активное обучение представляет собой эффективный подход к материаловедению, основанный на итеративном выборе наиболее информативных экспериментов. В отличие от традиционных методов, где выбор экспериментов может быть случайным или основан на заранее определенной стратегии, активное обучение динамически адаптирует процесс исследования. На каждом этапе алгоритм оценивает потенциальную информативность различных экспериментов, используя данные, полученные в ходе предыдущих итераций, и выбирает тот, который, как ожидается, принесет наибольшее увеличение знаний о целевых свойствах материала. Этот процесс позволяет существенно сократить количество необходимых экспериментов для достижения желаемого результата, оптимизируя время и ресурсы, затрачиваемые на поиск новых материалов с заданными характеристиками.
Активное обучение оптимизирует процесс материаловедческих исследований за счет баланса между исследованием (exploration) и использованием (exploitation). Стратегия исследования направлена на поиск новых, потенциально перспективных областей экспериментального пространства, в то время как использование фокусируется на более детальном изучении уже известных, перспективных регионов. Такой подход позволяет минимизировать общее количество необходимых экспериментов для достижения целевого результата, поскольку алгоритм динамически адаптирует выбор экспериментов, отдавая предпочтение тем, которые наиболее эффективно уменьшают неопределенность в предсказаниях свойств материалов. Это особенно важно в высокопроизводительных экспериментах, где стоимость и время проведения каждого эксперимента являются критическими факторами.
В рамках методологии активного обучения для предсказания свойств материалов могут использоваться различные суррогатные модели. К ним относятся регрессия Гаусса-Маркова (Gaussian Process Regression), случайный лес (Random Forest Regressor), XGBoost и байесовские нейронные сети (Bayesian Neural Networks). Эти модели служат для аппроксимации зависимости между структурой материала и его свойствами, позволяя эффективно оценивать свойства новых, еще не исследованных материалов на основе ограниченного набора экспериментальных данных. Выбор конкретной суррогатной модели зависит от характеристик данных и требуемой точности предсказания, при этом каждая из указанных моделей имеет свои преимущества и недостатки в контексте материаловедческих задач.
Функция приобретения Upper Confidence Bound (UCB) направляет выбор экспериментов, максимизируя прирост информации путем учета как предсказанного значения, так и неопределенности, связанной с каждой точкой данных. Наши результаты демонстрируют, что LLM-AL (Active Learning, основанное на больших языковых моделях) достигает сопоставимой или более высокой производительности по сравнению с традиционными методами, такими как регрессия Гаусса, случайный лес, XGBoost и байесовские нейронные сети, на четырех различных наборах данных. Это указывает на эффективность LLM-AL в оптимизации стратегии поиска материалов и снижении количества необходимых экспериментов для достижения целевых свойств.

Большие Языковые Модели: Ускорение Инноваций
Большие языковые модели (БЯМ) значительно ускоряют процесс открытия новых материалов, анализируя обширные объемы научной литературы и выявляя корреляции между составом, структурой и свойствами веществ. Обучаясь на основе существующих данных, БЯМ способны прогнозировать свойства материалов, сокращая необходимость в дорогостоящих и трудоемких экспериментальных исследованиях. Модели используют методы машинного обучения для установления связей между текстовыми описаниями материалов и их характеристиками, что позволяет предсказывать, например, прочность, электропроводность или термостойкость. Прогнозирующие возможности БЯМ особенно ценны при исследовании сложных материалов и сплавов, где традиционные методы требуют значительных вычислительных ресурсов и времени.
Эффективное проектирование запросов (prompt engineering) является критически важным для извлечения ценной информации из больших языковых моделей. Существуют два основных подхода к формулированию запросов: запросы в формате отчета (Report-Format Prompts), представляющие собой структурированные вопросы, требующие развернутых ответов, и запросы в формате параметров (Parameter-Format Prompts), фокусирующиеся на конкретных значениях или характеристиках. Комбинирование этих подходов позволяет максимизировать точность и релевантность получаемых результатов, обеспечивая более эффективное использование возможностей языковой модели для решения конкретных задач. Правильная формулировка запроса, учитывающая специфику модели и требуемый формат ответа, существенно влияет на качество и полезность извлеченной информации.
Несмотря на значительный потенциал больших языковых моделей (LLM), их эффективность может быть существенно снижена при работе с ограниченным объемом исходных данных, что известно как проблема «холодного старта». В таких условиях, когда LLM обучается или применяется к задачам с недостаточным количеством примеров, точность прогнозов и способность к генерации релевантных результатов значительно ухудшаются. Это связано с тем, что модели требуют достаточного объема данных для выявления закономерностей и установления корреляций, необходимых для выполнения поставленных задач. В ситуациях дефицита данных, LLM могут выдавать неточные, неполные или вводящие в заблуждение результаты, что ограничивает их применимость в областях, где данные ограничены или труднодоступны.
Недетерминированная природа больших языковых моделей (LLM) представляет собой существенную проблему для воспроизводимости результатов. В связи с этим, при использовании LLM для научных исследований требуется внимательный подход к документированию и контролю параметров генерации. Наши исследования показали, что использование запросов в формате отчета (Report-format prompts) обеспечивает более высокую семантическую согласованность с предварительным экспериментальным контекстом по сравнению с запросами в параметрическом формате (Parameter-format prompts). Это означает, что ответы, сгенерированные с использованием Report-format prompts, в большей степени соответствуют уже известным научным данным и уменьшают вероятность получения противоречивых или нерелевантных результатов, что критически важно для обеспечения надежности и валидности научных выводов.
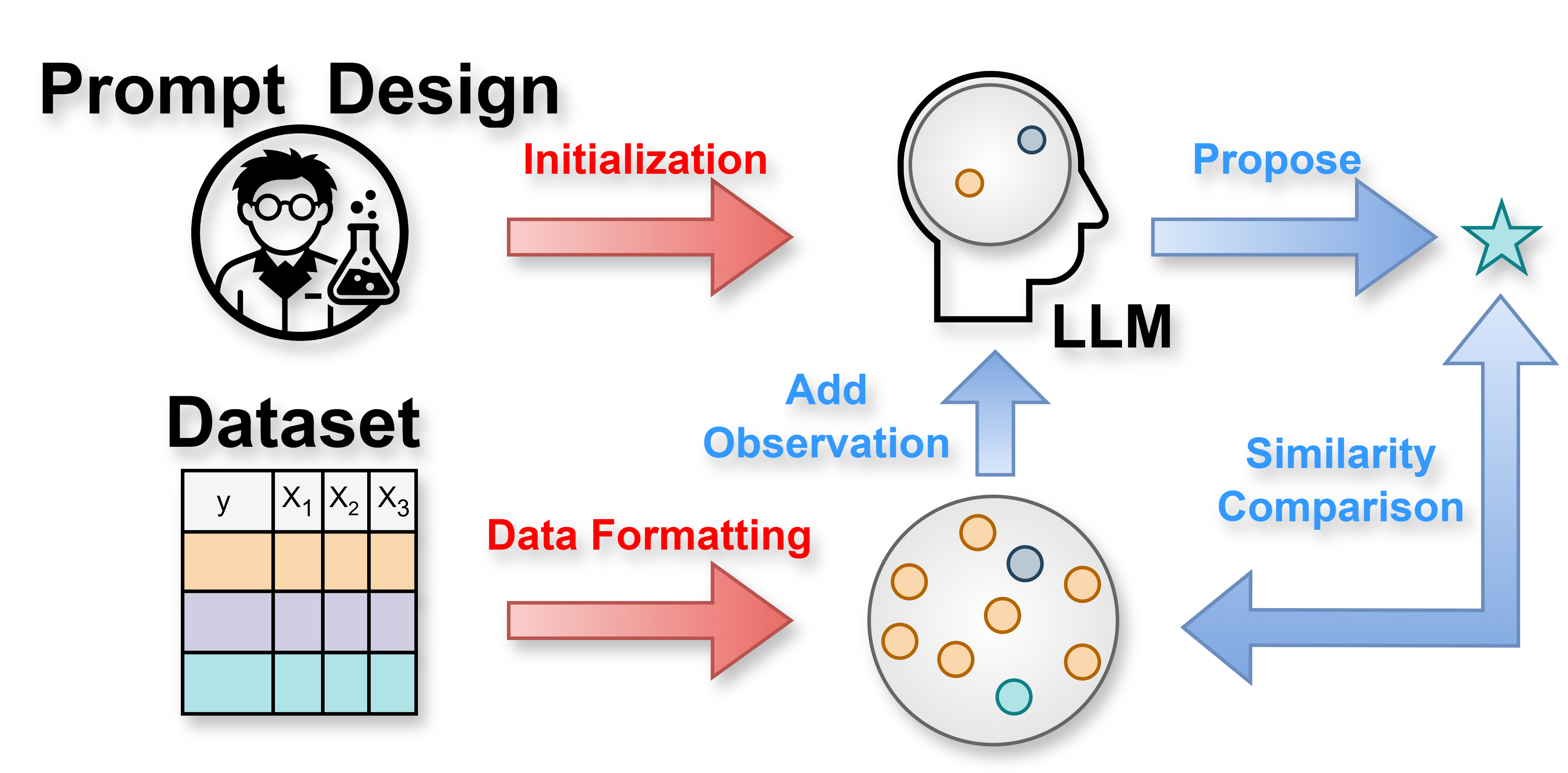
К Самоуправляемым Лабораториям: Новый Горизонт Материаловедения
Самоуправляемые лаборатории представляют собой инновационный подход к научным исследованиям, объединяя в единую систему автоматизированное экспериментальное оборудование и алгоритмы машинного обучения, такие как активное обучение и большие языковые модели. Данная интеграция позволяет создавать замкнутый цикл, в котором эксперименты проводятся и анализируются автоматически, а результаты используются для планирования следующих итераций без участия человека. Такой подход значительно ускоряет процесс открытия и оптимизации свойств материалов, позволяя проводить исследования в масштабах, недоступных традиционным методам, и открывая новые горизонты в материаловедении и других областях науки. В основе функционирования подобных лабораторий лежит способность алгоритмов машинного обучения эффективно управлять экспериментальным оборудованием и извлекать ценную информацию из получаемых данных, что обеспечивает высокую скорость и точность исследований.
Автономные лаборатории представляют собой замкнутую систему, позволяющую значительно ускорить процесс итераций и оптимизации свойств материалов без участия человека. В основе этой концепции лежит автоматизированное экспериментальное оборудование, которое, взаимодействуя с алгоритмами машинного обучения, самостоятельно планирует, проводит и анализирует эксперименты. Данный подход позволяет не только снизить временные затраты на исследования, но и выйти за рамки интуитивных подходов к материаловедению, исследуя гораздо большее количество комбинаций параметров и выявляя неожиданные корреляции. Такая саморегулируемая система способна непрерывно совершенствовать процесс, адаптируясь к полученным результатам и фокусируясь на наиболее перспективных направлениях, что открывает новые возможности для создания материалов с заданными свойствами и решения сложных научных задач.
Байесовская оптимизация представляет собой усовершенствованную стратегию, расширяющую возможности активного обучения при решении задач материаловедения. В отличие от традиционных методов, требующих большого количества экспериментов для исследования пространства параметров материала, байесовская оптимизация эффективно справляется с так называемыми «черными ящиками» — процессами, внутреннее устройство которых неизвестно, но для которых можно получить выходные данные при заданных входных параметрах. Используя вероятностную модель, основанную на предыдущих результатах экспериментов, она предсказывает наиболее перспективные области для дальнейшего исследования, минимизируя количество необходимых опытов для нахождения оптимальных свойств материала. Такой подход особенно ценен в материаловедении, где вычислительные модели часто неполны или требуют значительных затрат времени, а экспериментальные исследования — ресурсов и времени ученых. Байесовская оптимизация позволяет значительно ускорить процесс открытия новых материалов с заданными характеристиками, предлагая эффективный инструмент для решения сложных задач в области дизайна и оптимизации материалов.
Автономные лаборатории открывают беспрецедентные возможности для ускорения материаловедческих исследований и решения актуальных научных задач. В рамках данной работы продемонстрировано, что комбинация больших языковых моделей и активного обучения (LLM-AL) позволяет достигать результатов, сопоставимых или превосходящих традиционные подходы, при этом сокращая количество необходимых экспериментов более чем на 70%. Такое значительное снижение экспериментальных затрат, в сочетании с автоматизацией процесса, позволяет исследователям фокусироваться на анализе данных и формулировании новых гипотез, существенно повышая эффективность поиска и разработки новых материалов с заданными свойствами. Это создает условия для прорывных инноваций в различных областях, от энергетики и медицины до электроники и машиностроения.

Исследование демонстрирует, что большие языковые модели могут эффективно направлять экспериментальные исследования в материаловедении, обходя традиционные методы машинного обучения в сценариях активного обучения. Это не революция, а скорее очередная итерация поиска более эффективных ‘костылей’ для ускорения открытия материалов. Как однажды заметил Марвин Мински: «Наиболее важные вещи, которые мы создаем, — это те, которые позволяют нам создавать другие вещи». В данном случае, LLM выступает как инструмент, который позволяет исследователям быстрее перебирать варианты, но фундаментальные ограничения процесса — необходимость в экспериментальной проверке и сложность моделирования реальных материалов — никуда не деваются. Архитектура, лежащая в основе этих моделей, рано или поздно станет предметом иронии, но пока что это эффективный способ автоматизировать рутинные задачи и, возможно, немного отодвинуть неизбежный технический долг.
Что дальше?
Представленная работа демонстрирует, что большие языковые модели могут направлять эксперименты в материаловедении, конкурируя или превосходя традиционные методы машинного обучения в активном обучении. Однако, за каждой «революцией» скрывается неизбежный технический долг. Очевидно, что эффективность сильно зависит от качества промптов — а это, по сути, ручной труд, замаскированный под автоматизацию. Когда увидим идеальный промпт — будем знать, что его ещё никто не протестировал на реальных данных.
Следующим этапом, вероятно, станет автоматизация генерации и валидации промптов. Но не стоит забывать: «саморастущие» промпты — это просто более сложные способы создания новых ошибок. Важнее, чем элегантность алгоритма, будет устойчивость к шуму и неполноте данных, которые всегда будут присутствовать в экспериментальных исследованиях. Иначе, мы получим красивую модель, которая прекрасно работает на синтетических данных и быстро ломается в реальном мире.
Оптимизация байесовскими методами выглядит привлекательно, но не стоит переоценивать её масштабируемость. С увеличением размерности пространства параметров, вычислительные затраты быстро возрастают. В конечном итоге, придётся выбирать между точностью и скоростью. А выбор этот всегда будет прагматичным, а не теоретически обоснованным. Ведь, как известно, MVP — это просто способ сказать пользователю: «подождите, мы потом исправим».
Оригинал статьи: https://arxiv.org/pdf/2511.19730.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовый Переход: Пора Заботиться о Криптографии
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые прорывы: Хорошее, плохое и смешное
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2025-11-26 07:03