Автор: Денис Аветисян
Новый алгоритм TreeGRPO позволяет значительно улучшить процесс обучения генеративных моделей, приближая их к человеческому восприятию и предпочтениям.
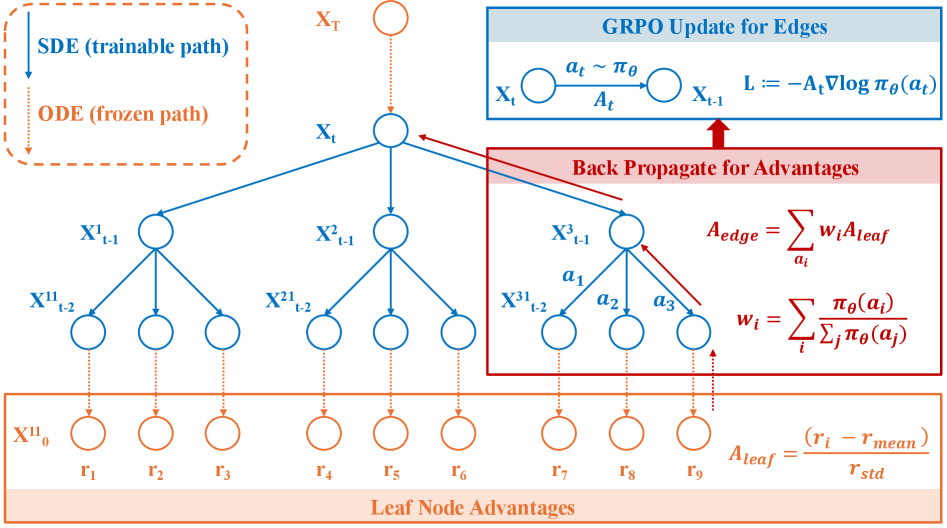
Представлен алгоритм TreeGRPO для постобучения диффузионных моделей с использованием обучения с подкреплением и дерева поиска.
Пост-тренировка генеративных моделей с подкреплением (RL) является ключевым этапом согласования с предпочтениями человека, однако её вычислительная сложность существенно ограничивает широкое применение. В данной работе представлена новая структура RL под названием TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models, которая значительно повышает эффективность обучения за счет представления процесса шумоподавления в виде дерева поиска. Предложенный подход обеспечивает высокую эффективность выборки, точное распределение вознаграждения и амортизацию вычислений, что позволяет ускорить обучение в 2.4 раза и достичь оптимального баланса между эффективностью и качеством генерируемых образцов. Сможет ли TreeGRPO стать стандартом де-факто для масштабируемого и эффективного согласования визуальных генеративных моделей с использованием RL?
Согласование Генеративных Моделей: Вызовы Обучения с Подкреплением
Современные генеративные модели, такие как диффузионные модели, демонстрируют впечатляющую способность создавать реалистичные изображения и тексты, однако их потенциал остается нереализованным без согласования с человеческими предпочтениями. Несмотря на высокую точность воспроизведения деталей, модели часто генерируют контент, который может быть нежелательным, нерелевантным или просто не соответствующим ожиданиям пользователя. Поэтому, для практического применения, необходимо обучить эти модели понимать и учитывать субъективные критерии качества, определяемые человеком, что требует разработки эффективных методов для интеграции человеческой обратной связи в процесс обучения. Именно это согласование между технической точностью и субъективной полезностью является ключевым фактором, определяющим успех и широкое распространение генеративных моделей в различных областях применения, от искусства и развлечений до научных исследований и разработки продуктов.
Традиционные подходы к согласованию генеративных моделей, таких как диффузионные модели, часто сталкиваются с серьезными проблемами стабильности и масштабируемости. В процессе обучения, незначительные изменения в параметрах или структуре вознаграждения могут приводить к непредсказуемым колебаниям и даже к полному срыву процесса оптимизации. Эта нестабильность особенно заметна при работе с высокоразмерными пространствами параметров, характерными для современных генеративных моделей, и препятствует эффективному обучению. Кроме того, масштабирование этих методов для обработки больших объемов данных и сложных задач, например, генерации изображений высокого разрешения, требует значительных вычислительных ресурсов и времени, что ограничивает их практическое применение и замедляет прогресс в области генеративного искусственного интеллекта.
Для эффективной адаптации генеративных моделей к предпочтениям человека требуется применение устойчивых методов обучения с подкреплением (RL), способных справляться со сложными ландшафтами вознаграждений. Обучение с подкреплением позволяет модели совершенствовать свои стратегии генерации, получая обратную связь в виде вознаграждений за результаты, соответствующие заданным критериям. Однако, при работе с высокоразмерными пространствами, характерными для генеративных моделей, стандартные алгоритмы RL часто сталкиваются с проблемами нестабильности и медленной сходимости. Разработка новых, более робастных методов RL, учитывающих специфику генеративных моделей и способных эффективно исследовать сложные ландшафты вознаграждений, является ключевой задачей для достижения желаемого уровня согласованности между моделью и человеческими предпочтениями. Успешное решение этой задачи откроет возможности для создания генеративных моделей, способных генерировать контент, максимально соответствующий ожиданиям пользователей и требованиям конкретных приложений.

GRPO и Его Вариации: Повышение Эффективности Выборки в RL
GRPO (Group Relative Policy Optimization) является усовершенствованием алгоритма Proximal Policy Optimization (PPO), направленным на повышение эффективности обновления политики. В отличие от PPO, использующего глобальные преимущества для оценки действий, GRPO вводит понятие групповых преимуществ. Это достигается путем вычисления преимуществ относительно группы схожих состояний, что позволяет уменьшить дисперсию оценок и, как следствие, проводить более стабильные и эффективные обновления политики. В частности, GRPO вычисляет преимущество действия $A_t$ как разницу между $Q_t$ и $V_t$, но при этом $V_t$ вычисляется для группы состояний, близких к текущему состоянию $s_t$, что обеспечивает более точную оценку и ускоряет процесс обучения.
Для повышения эффективности алгоритма GRPO в различных архитектурах генеративных моделей были предложены несколько адаптаций. DanceGRPO оптимизирован для работы с дискретными латентными пространствами, используя методы, направленные на улучшение стабильности обучения при генерации дискретных данных. FlowGRPO разработан специально для нормализующих потоков, обеспечивая более эффективную оптимизацию в контексте непрерывных латентных представлений. MixGRPO, в свою очередь, сочетает в себе элементы, оптимизированные для различных типов моделей, включая как дискретные, так и непрерывные, и использует гибридные методы выборки и скользящие окна для снижения вычислительных затрат при работе с обыкновенными дифференциальными уравнениями (ODE) и стохастическими дифференциальными уравнениями (SDE).
MixGRPO оптимизирует вычислительные затраты при работе с непрерывными нормализующими потоками, использующими обыкновенные дифференциальные уравнения (ODE) и стохастические дифференциальные уравнения (SDE), за счет применения гибридной выборки и скользящих окон. Гибридная выборка комбинирует дискретную и непрерывную выборки для более эффективного исследования пространства состояний, в то время как скользящие окна ограничивают объем данных, необходимых для обновления политики, снижая вычислительную сложность. Эти техники позволяют MixGRPO эффективно обучать генеративные модели, использующие сложные методы нормализации потоков, такие как ODE и SDE, при разумных вычислительных ресурсах.
TreeGRPO: Новый Фреймворк для Улучшенной Оценки Преимуществ
В основе TreeGRPO лежит новая схема оценки преимуществ, использующая структуру дерева поиска (Tree Search) для повышения эффективности выборки и улучшения атрибуции вознаграждений в обучении с подкреплением (RL). В отличие от традиционных методов, которые полагаются на одношаговые оценки, TreeGRPO строит дерево возможных действий, позволяя алгоритму оценивать долгосрочные последствия каждого действия и более точно определять вклад каждого шага в итоговое вознаграждение. Это особенно важно в сложных средах с отложенными вознаграждениями, где традиционные методы могут испытывать трудности с правильной атрибуцией заслуг и, как следствие, медленной сходимостью обучения. Использование дерева поиска позволяет алгоритму эффективно исследовать пространство действий и собирать более информативные данные для обучения, что приводит к повышению эффективности и улучшению результатов.
В основе TreeGRPO лежит комбинирование поиска по дереву (Tree Search) с методами пакетной оценки преимущества (Batch Advantage Estimation) и неотрицательными весами (Non-negative Weights). Данный подход позволяет более эффективно исследовать пространство состояний и распределять кредит за вознаграждение в сложных средах обучения с подкреплением. Пакетная оценка преимущества снижает дисперсию оценки, а использование неотрицательных весов стабилизирует процесс обучения и предотвращает осцилляции, особенно в задачах с разреженными сигналами вознаграждения. Комбинация этих техник обеспечивает более точную и надежную оценку преимущества, что, в свою очередь, способствует более эффективному обучению агента в сложных условиях и повышает скорость сходимости алгоритма.
В ходе экспериментов с визуальными генеративными моделями, фреймворк TreeGRPO продемонстрировал ускорение сходимости обучения в 2-3 раза по сравнению с существующими методами. Данная оптимизация достигается за счет более эффективного назначения кредитов и улучшения оценки преимуществ. В процессе оценки качества, TreeGRPO показал превосходный баланс между эффективностью обучения и итоговой наградой. В частности, модель достигла показателей: HPSv2.1 — 0.3735, Aesthetic Score — 6.5094, и ImageReward Score — 1.3426, что подтверждает ее высокую производительность в задачах визуальной генерации.
Оценка Соответствия: Роль Моделей Вознаграждения
Эффективность современных систем обучения с подкреплением напрямую зависит от качества используемых моделей вознаграждения, оценивающих соответствие сгенерированного контента человеческим предпочтениям. Неточные или предвзятые модели вознаграждения могут привести к тому, что система будет оптимизироваться для достижения ложных целей, игнорируя истинные намерения разработчиков и пользователей. В результате, даже самые передовые алгоритмы обучения с подкреплением не смогут обеспечить желаемое поведение, если базовый механизм оценки не способен адекватно отражать ценности и ожидания людей. Поэтому, разработка надежных и репрезентативных моделей вознаграждения является критически важным шагом для создания действительно полезных и безопасных систем искусственного интеллекта.
Для оценки соответствия сгенерированного контента человеческим предпочтениям используются различные модельные сигналы, такие как ClipScore, Aesthetic Score, HPS-v2.1 и ImageReward. ClipScore оценивает семантическое сходство между текстом и изображением, что позволяет определить, насколько визуальный контент соответствует текстовому описанию. Aesthetic Score, в свою очередь, фокусируется на художественной ценности изображения, оценивая его визуальную привлекательность и композицию. HPS-v2.1 и ImageReward предоставляют более сложные оценки, учитывающие не только визуальные характеристики, но и субъективные предпочтения людей, полученные в результате анализа больших объемов данных. Комбинирование этих моделей позволяет получить комплексную оценку, отражающую как объективные качества контента, так и его соответствие ожиданиям пользователей, что является ключевым фактором в создании действительно привлекательных и полезных генеративных моделей.
Для более всесторонней и надежной оценки соответствия сгенерированного контента человеческим предпочтениям, современные системы все чаще используют комбинацию различных моделей вознаграждения, таких как ClipScore и ImageReward. В частности, применение метода неотрицательных весов позволяет эффективно объединять сигналы от этих моделей, создавая более точную оценку. Кроме того, оптимизация процесса обучения, реализованная в алгоритме TreeGRPO, значительно сокращает время, необходимое для каждой итерации, до 72.0-79.2 секунд. Это демонстрирует прирост скорости в 2.4 раза по сравнению с базовыми методами, которым требуется 145.4-184.0 секунды, что делает TreeGRPO особенно эффективным инструментом для масштабируемых систем оценки соответствия.
Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в алгоритмах обучения с подкреплением. В основе TreeGRPO лежит принцип эффективного поиска и распространения вознаграждений, что позволяет добиться высокой производительности при дообучении генеративных моделей. Этот подход перекликается с мыслями Анри Пуанкаре: “Математия — это искусство давать верные названия вещам”. Действительно, точность и непротиворечивость алгоритма, как и правильное наименование математических объектов, являются ключевыми для получения достоверных результатов. В контексте TreeGRPO, использование древовидного поиска позволяет элегантно и эффективно оценивать преимущества различных действий, что соответствует принципу доказательности и математической обоснованности.
Куда Далее?
Представленная работа, несомненно, демонстрирует элегантность использования древовидного поиска для уточнения генеративных моделей. Однако, истинная проверка любой методологии — в её масштабируемости и устойчивости к шуму. Вполне логично предположить, что увеличение размерности пространства состояний приведет к экспоненциальному росту вычислительных затрат, связанных с построением и исследованием дерева. Это требует разработки более эффективных стратегий обрезки и аппроксимации, возможно, с привлечением методов, заимствованных из области оптимального управления.
Более того, вопрос о надежности оценки преимущества (advantage estimation) остается открытым. В хаосе данных спасает только математическая дисциплина. Несмотря на улучшения, достигнутые в данной работе, всегда существует риск, что оценка преимущества будет смещена или недостаточно точна, что приведет к субоптимальному обучению модели. Необходимы более строгие теоретические гарантии сходимости и устойчивости алгоритма.
В конечном счете, будущее этого направления исследований, вероятно, лежит в интеграции методов обучения с подкреплением с более глубоким пониманием принципов, лежащих в основе генеративных моделей. Задача состоит не просто в том, чтобы научить модель генерировать желаемые результаты, но и в том, чтобы понять, почему она это делает, и обеспечить её предсказуемость. Лишь тогда можно будет говорить о настоящем прогрессе в области искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2512.08153.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-10 12:44