Автор: Денис Аветисян
Новое исследование показывает, как современные ИИ-системы осваивают сложные когнитивные способности и почему некоторые методы обучения работают лучше других.
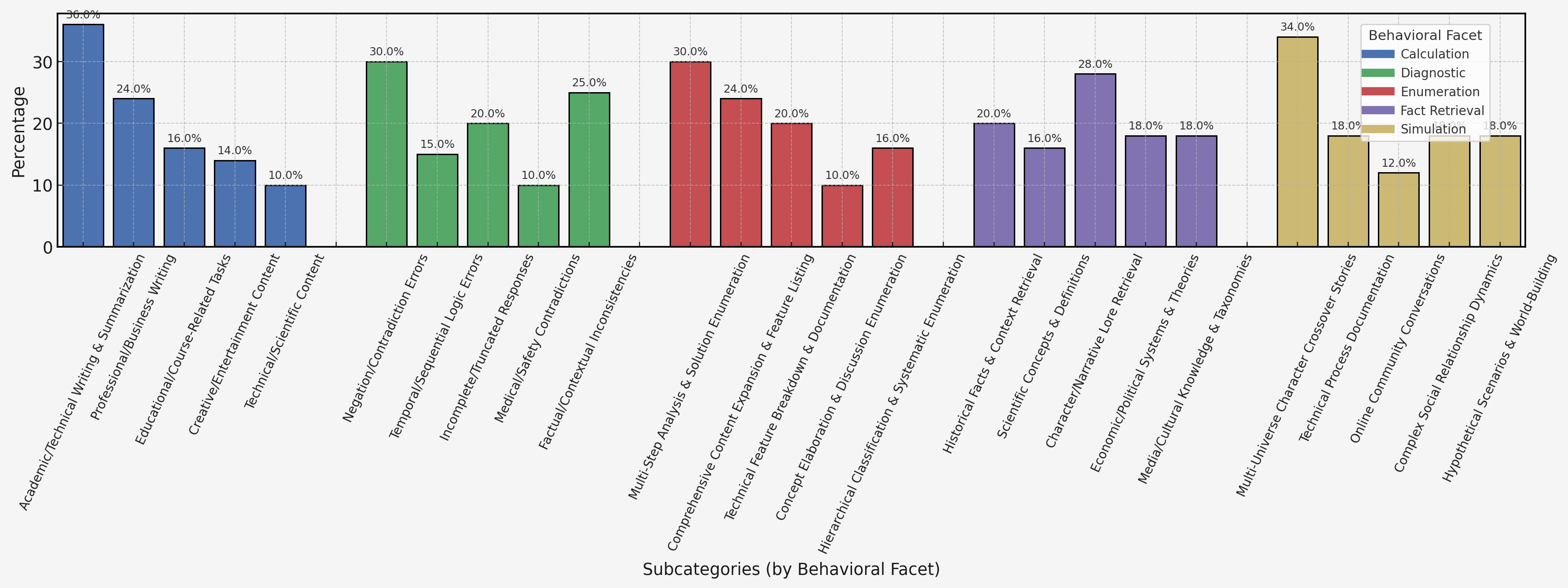
Детальный анализ навыков рассуждений больших языковых моделей выявляет, что обучение с подкреплением сохраняет более сбалансированный набор умений по сравнению с контролируемым обучением, которое часто приводит к чрезмерной специализации.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), механизмы, определяющие их способность к обобщению, остаются недостаточно изученными. В работе ‘How and Why LLMs Generalize: A Fine-Grained Analysis of LLM Reasoning from Cognitive Behaviors to Low-Level Patterns’ представлен новый подход к анализу рассуждений LLM, основанный на декомпозиции когнитивных навыков на базовые элементы, такие как вычисления и перечисления. Полученные результаты показывают, что обучение с подкреплением способствует сохранению более сбалансированного набора навыков, в то время как контролируемое обучение часто приводит к переспециализации и ухудшению обобщающей способности. Какие принципы проектирования стратегий обучения позволят в полной мере раскрыть потенциал LLM и обеспечить надежное обобщение в различных областях?
Фундамент интеллекта: Раскрывая когнитивные навыки
Истинный интеллект выходит за рамки простого запоминания и воспроизведения информации; он представляет собой способность к многогранному рассуждению и решению сложных задач. Вместо пассивного хранения фактов, интеллектуальная система должна уметь анализировать, сопоставлять данные, строить логические цепочки и предсказывать последствия. Способность к абстрактному мышлению, выведению новых знаний на основе имеющихся и адаптации к меняющимся обстоятельствам является ключевым отличием развитого интеллекта. Таким образом, оценка интеллектуальных способностей должна фокусироваться не на объеме заученной информации, а на сложности и гибкости мыслительных процессов, демонстрируемых системой при решении разнообразных задач.
Основой любого сложного мышления являются фундаментальные когнитивные навыки, такие как вычисления, перечисление, моделирование, извлечение фактов и диагностическая проверка. Эти навыки не просто отдельные функции, а взаимосвязанные элементы, формирующие основу для решения проблем и принятия решений. Способность быстро и точно выполнять вычисления позволяет оценивать вероятности и оптимизировать действия. Перечисление и извлечение фактов обеспечивают доступ к необходимой информации, а моделирование позволяет предсказывать последствия различных сценариев. Наконец, диагностическая проверка гарантирует точность и надежность полученных результатов. В совокупности эти навыки представляют собой когнитивный инструментарий, позволяющий человеку эффективно взаимодействовать с окружающим миром и адаптироваться к изменяющимся условиям.
Оценка больших языковых моделей (LLM) требует перехода от традиционных, упрощенных тестов к более детальному анализу базовых когнитивных способностей. Простое измерение скорости или точности ответа не позволяет понять, как модель осуществляет вычисления, оперирует с числами, моделирует ситуации или проверяет достоверность информации. Вместо этого, необходимо разрабатывать специализированные тесты, которые целенаправленно проверяют способность модели к расчету, перечислению, симуляции и диагностической проверке. Такой подход позволит получить более тонкое представление о сильных и слабых сторонах LLM, выявляя не только уровень «знаний», но и глубину когнитивных процессов, лежащих в основе их работы. Это, в свою очередь, станет основой для создания более совершенных и надежных систем искусственного интеллекта.
Логическое мышление в LLM: Новые горизонты искусственного интеллекта
Возможности больших языковых моделей (БЯМ) в области воспроизведения сложного рассуждения напрямую зависят от их внутренних характеристик. Ключевые параметры, такие как количество слоёв, размерность скрытого пространства и механизм внимания, определяют способность модели к представлению и обработке информации. Архитектурные особенности, включая использование разреженных связей или специфических функций активации, также оказывают значительное влияние на качество рассуждений. Более того, данные, на которых обучается модель, и применяемые методы обучения формируют её способность к обобщению и решению задач, требующих логического вывода и анализа.
Модель Qwen3-14B представляет собой эффективную платформу для исследования границ логического мышления в больших языковых моделях (LLM). Обладая 14 миллиардами параметров, она обеспечивает достаточный масштаб для обработки сложных задач, сохраняя при этом относительно высокую вычислительную эффективность по сравнению с моделями значительно большего размера. Это позволяет проводить более доступные и масштабируемые исследования в области LLM, сосредотачиваясь на архитектурных инновациях и методах обучения, а не только на увеличении вычислительных ресурсов. Такой баланс между масштабом и эффективностью делает Qwen3-14B ценным инструментом для разработки и оценки новых подходов к логическому мышлению в искусственном интеллекте.
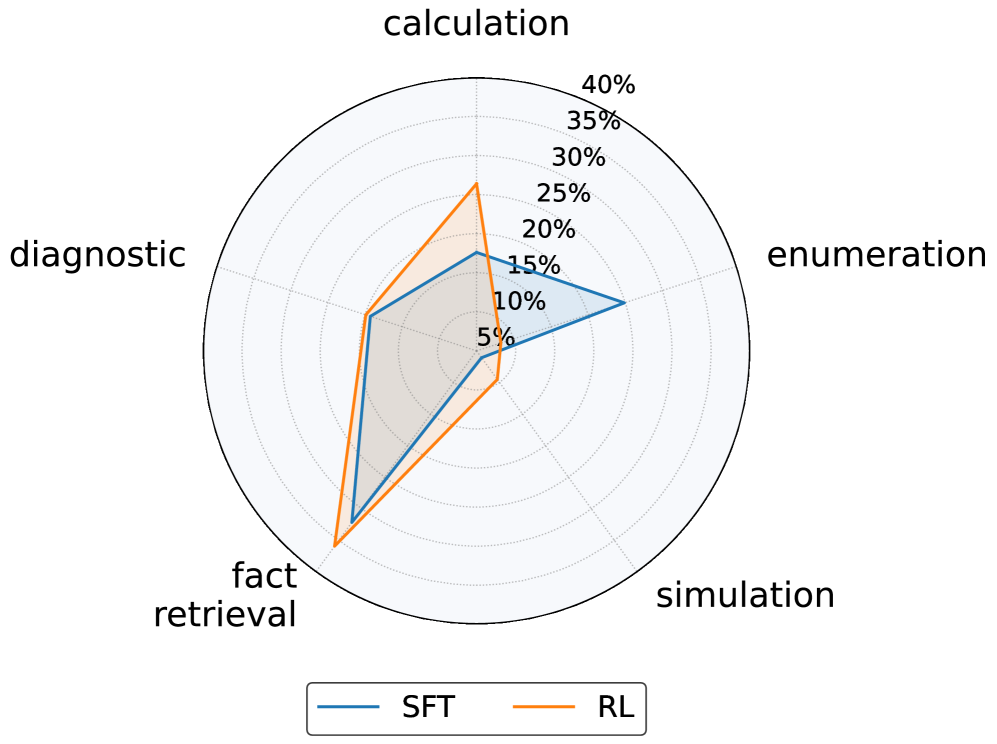
В моделях, таких как Qwen3-14B, количество параметров напрямую влияет на способность представлять и обрабатывать сложные данные, определяя потенциал для надежного рассуждения. Примечательно, что как методы контролируемого обучения (SFT), так и обучение с подкреплением (RL) обновляют приблизительно 98% параметров модели. Это указывает на то, что именно режим обучения, а не просто величина изменений параметров, является более критичным фактором, определяющим эффективность модели в задачах, требующих рассуждений.
Валидация рассуждений: Подход поведенческого бенчмарка
Комплексная поведенческая оценка (Behavioral Benchmark) является необходимым инструментом для всесторонней оценки языковых моделей (LLM), охватывающим широкий спектр когнитивных навыков. Традиционные метрики точности недостаточны для определения истинных возможностей модели, поскольку они не учитывают сложность рассуждений и способность к решению разнообразных задач. Поведенческая оценка позволяет оценить не только способность модели давать правильные ответы, но и то, как она приходит к этим ответам, выявляя сильные и слабые стороны в различных областях, таких как математическое, научное и программное рассуждение. Это позволяет получить более полное представление о когнитивных способностях модели, выходящее за рамки простой производительности на отдельных тестовых примерах.
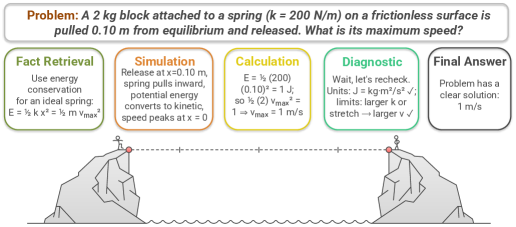
Для всесторонней оценки навыков решения задач, эталонный набор тестов включает в себя задачи, проверяющие математическое рассуждение, научное мышление и навыки программирования. Математические задачи охватывают арифметику, алгебру и элементарную геометрию, требуя от модели применения логических операций и числовых вычислений. Научное рассуждение оценивается посредством вопросов, требующих понимания физических, химических и биологических принципов, а также анализа данных и формулировки гипотез. Задачи по программированию, включающие написание и отладку кода на различных языках, проверяют способность модели к алгоритмическому мышлению и решению задач посредством кодирования. Комбинация этих трех категорий позволяет получить целостную картину когнитивных возможностей языковой модели.
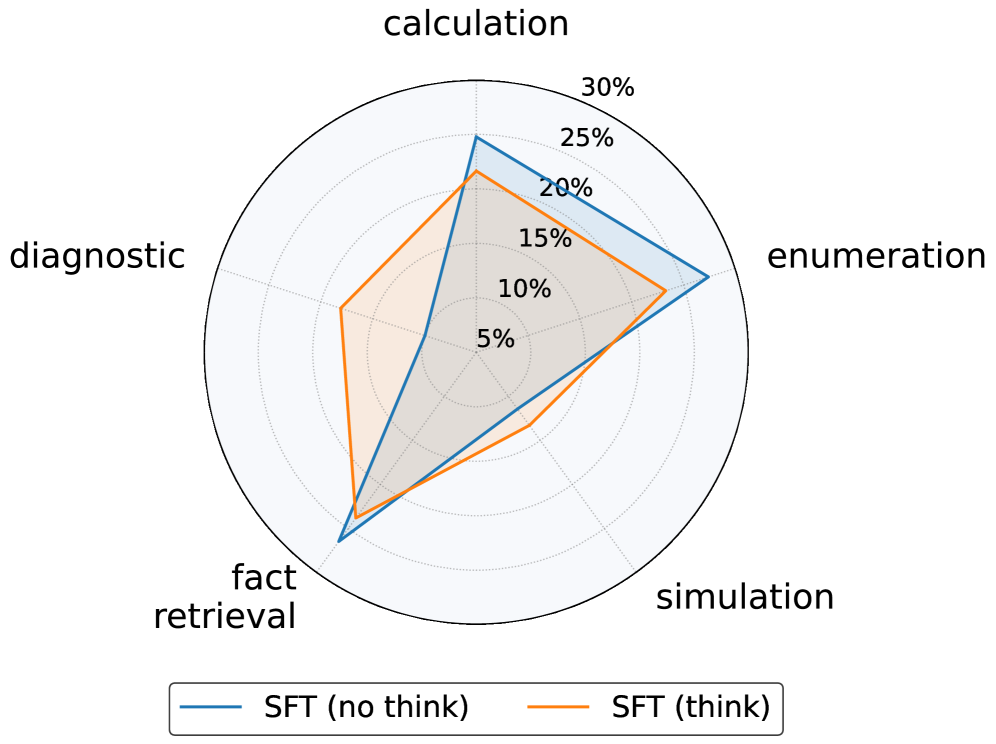
В рамках валидации рассуждений, разработанный нами поведенческий бенчмарк включает задачи, не требующие логического вывода, что позволяет отделить истинное рассуждение от простого распознавания закономерностей. Результаты показывают, что модели, обученные с использованием обучения с подкреплением (RL), демонстрируют более сбалансированные когнитивные профили — что визуально отображается в виде округлых радаров — в отличие от моделей, прошедших контролируемое обучение (SFT), которые характеризуются прерывистыми и нерегулярными профилями, указывающими на специализацию в отдельных навыках. Такая дифференциация позволяет более точно оценить общие когнитивные способности моделей и их способность к обобщению.
Влияние и перспективы развития рассуждений в искусственном интеллекте
Тщательная оценка больших языковых моделей (LLM) по базовым когнитивным навыкам позволяет получить более глубокое понимание их возможностей и ограничений. Исследования, направленные на проверку способности LLM к логическому мышлению, решению проблем и абстрагированию, выявляют не только сильные стороны, но и области, требующие дальнейшего развития. Выявление слабых мест в когнитивных способностях моделей является ключевым шагом к созданию более надежных и эффективных систем искусственного интеллекта, способных к адаптации и решению сложных задач в различных областях. Такой подход позволяет перейти от простого достижения высоких результатов в узкоспециализированных задачах к созданию действительно интеллектуальных систем, способных к обобщению и переносу знаний.
Полученное понимание возможностей и ограничений больших языковых моделей (LLM) позволяет создавать более надежные и устойчивые системы искусственного интеллекта, способные решать сложные задачи из реального мира. В частности, исследования показывают, что модели, обученные с помощью обучения с подкреплением (RL), демонстрируют лучшую сохранность приобретенных навыков при переносе обучения в другие области. В отличие от моделей, обученных с помощью контролируемого обучения (SFT), RL-модели меньше теряют в производительности при переходе от математических задач к задачам, не требующим логического мышления, что указывает на их более высокую способность к обобщению и адаптации к новым условиям.
Перспективные исследования в области искусственного интеллекта должны быть направлены на совершенствование существующих оценочных тестов, чтобы более точно отражать когнитивные способности. Параллельно, необходимо изучение и разработка новых архитектур ИИ, способных к более эффективному и гибкому решению задач. Особое внимание следует уделить сближению искусственного и человеческого мышления, что подразумевает не только достижение сопоставимых результатов, но и понимание принципов, лежащих в основе рассуждений, используемых человеком. Успешное решение этих задач позволит создать более надежные и интеллектуальные системы, способные к адаптации и обучению в различных областях, а также к решению сложных, нетривиальных проблем, с которыми сталкивается современное общество.
Исследование демонстрирует, что архитектуры больших языковых моделей, подобно любым системам, подвержены старению и эволюции. Авторы работы показывают, как различные методы обучения — обучение с подкреплением и контролируемое обучение — влияют на баланс когнитивных навыков. Контролируемое обучение часто приводит к чрезмерной специализации, тогда как обучение с подкреплением способствует сохранению более широкого спектра умений. Как метко заметил Андрей Колмогоров: «Математика — это искусство говорить правду без необходимости убедительности». Подобно математике, эффективная архитектура модели должна быть устойчива и универсальна, а не просто демонстрировать впечатляющие результаты в узко определенных задачах. Иными словами, речь идет о создании системы, способной адаптироваться и сохранять свою функциональность в меняющейся среде.
Что дальше?
Представленная работа, стремясь разложить сложные когнитивные навыки больших языковых моделей на элементарные составляющие, неизбежно сталкивается с фундаментальным вопросом: не является ли сама эта декомпозиция лишь иллюзией порядка в хаосе? Подобно тому, как любая система со временем теряет свою функциональность, LLM не стареют из-за ошибок в коде, а из-за неумолимого течения времени и накопления энтропии. Выявленное преимущество обучения с подкреплением в поддержании баланса навыков — не абсолютное решение, а лишь временная отсрочка неизбежной специализации, когда система, стремясь к оптимизации в одном направлении, теряет гибкость в других.
Ключевым ограничением остается искусственность самой постановки задачи — разделить когнитивные функции на отдельные блоки, словно разбирая сложный механизм. Жизненные системы редко функционируют столь дискретно. Будущие исследования должны сместиться от поиска оптимальных алгоритмов обучения к изучению принципов самоорганизации и адаптации, позволяющих LLM сохранять целостность и устойчивость в меняющейся среде. В конечном счете, важно помнить: иногда видимая стабильность — это лишь задержка катастрофы.
Вместо бесконечной гонки за улучшением отдельных метрик, необходимо сосредоточиться на понимании того, как LLM взаимодействуют с миром, как они формируют представления о реальности и как эти представления эволюционируют со временем. Иначе, все усилия по совершенствованию искусственного интеллекта рискуют превратиться в создание все более сложных и хрупких конструкций, обреченных на постепенное увядание.
Оригинал статьи: https://arxiv.org/pdf/2512.24063.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
2026-01-02 14:35