Автор: Денис Аветисян
Новая платформа DeepCode позволяет автоматически преобразовывать научные статьи в исполняемый код, открывая новые возможности для проверки и воспроизведения результатов.
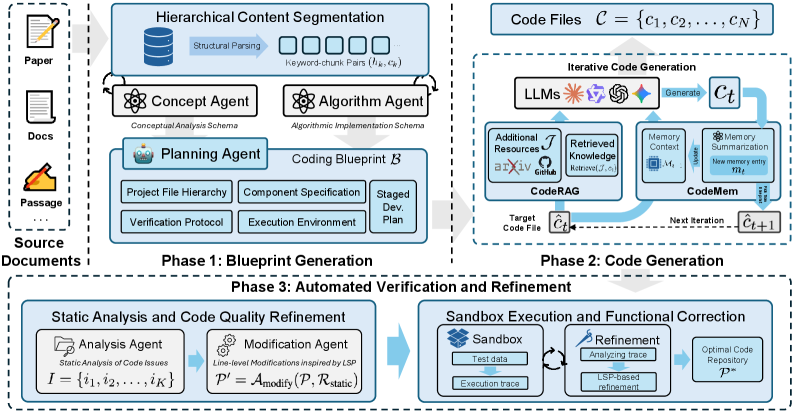
DeepCode — это агентный фреймворк, использующий большие языковые модели для синтеза кода, оптимизации потока информации и повышения эффективности работы с контекстом.
Несмотря на значительный прогресс в области больших языковых моделей, автоматизированный перевод научных публикаций в рабочий код остается сложной задачей из-за перегрузки информацией и ограничений контекста. В данной работе представлена система DeepCode: Open Agentic Coding — автономный фреймворк, решающий эту проблему посредством оптимизированного управления информационными потоками. DeepCode достигает передовых результатов в воспроизведении научных работ в виде исполняемого кода, превосходя как коммерческие решения, так и экспертов-программистов, благодаря компрессии исходных данных, структурированному хранению кода, условной инъекции знаний и самокоррекции ошибок. Не открывает ли это новые возможности для автоматизации научных исследований и ускорения процесса проверки и воспроизведения результатов?
Разрушая Барьеры Воспроизводимости: Вызов для Искусственного Интеллекта
Несмотря на стремительное развитие машинного обучения, воспроизведение результатов, описанных в научных публикациях, остается удивительно сложной задачей, серьезно замедляющей прогресс в области. Эта проблема не ограничивается тривиальными ошибками, а обусловлена целым рядом факторов, включая неполноту предоставляемого кода, неоднозначность описаний экспериментальных установок и зависимость от быстро устаревающих программных сред. Воспроизводимость является краеугольным камнем научного метода, и ее отсутствие подрывает доверие к исследованиям, а также требует значительных затрат времени и ресурсов для проверки и подтверждения полученных результатов. Неспособность других исследователей независимо подтвердить заявленные достижения препятствует развитию новых технологий и замедляет внедрение инноваций, создавая барьер для дальнейшего прогресса в области искусственного интеллекта.
Существующие подходы к обеспечению воспроизводимости исследований в области искусственного интеллекта часто оказываются недостаточными из-за неполноты предоставляемого кода, расплывчатости описаний алгоритмов и зависимостей от быстро устаревающих сред разработки. Авторы научных работ нередко публикуют лишь фрагменты кода, необходимые для демонстрации результатов, опуская критически важные детали, необходимые для полноценной реализации. Кроме того, недостаточная ясность в описании используемых методов, параметров и предварительной обработки данных усложняет процесс повторения экспериментов. Особенно проблематичным является использование временных или нестабильных сред разработки, которые могут перестать функционировать спустя короткое время, делая воспроизведение результатов невозможным. Такая ситуация приводит к потере ценного времени и ресурсов, а также подрывает доверие к опубликованным исследованиям в сфере машинного обучения.
Отсутствие воспроизводимости результатов в исследованиях искусственного интеллекта влечет за собой ощутимые затраты времени и ресурсов, а также подрывает доверие к опубликованным научным работам. Согласно последним оценкам, современные системы искусственного интеллекта способны повторить эксперименты, описанные в научных статьях, лишь в 42% случаев, в то время как у экспертов-людей этот показатель достигает 72%. Данное различие демонстрирует существенные ограничения существующих подходов к обеспечению воспроизводимости и подчеркивает необходимость разработки более надежных и эффективных методов, гарантирующих достоверность и проверяемость научных результатов в области ИИ.
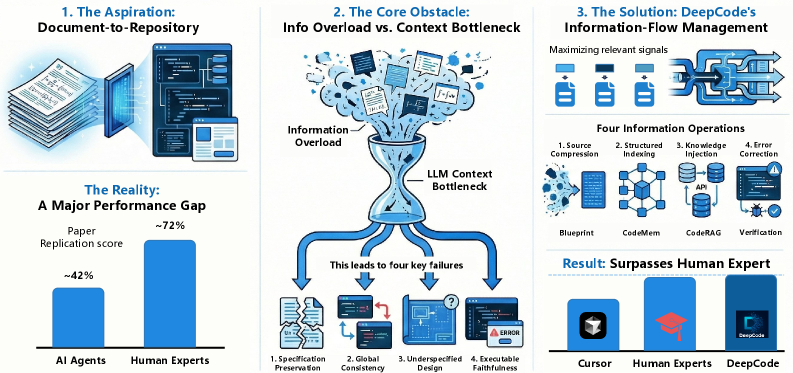
DeepCode: Автономный Агент для Воссоздания Алгоритмов
DeepCode — это агентурная платформа для автоматического воспроизведения алгоритмов, описанных в научных публикациях по машинному обучению. В отличие от простых систем генерации кода, DeepCode ориентирована на создание полноценных, самодостаточных репозиториев, включающих не только исходный код, но и все необходимые зависимости, а также наборы тестов для проверки корректности реализации. Платформа функционирует как автономный агент, способный самостоятельно анализировать научные статьи и преобразовывать их описания в работающий код, имитируя процесс воспроизведения результатов, представленных авторами.
DeepCode использует протокол $Model Context Protocol (MCP)$ для интеграции инструментов, обеспечивающих доступ к информации, семантическую обработку и выполнение действий. MCP позволяет системе динамически подключать и координировать различные модули, такие как поисковые системы для получения необходимых данных, инструменты для анализа естественного языка для понимания описания алгоритма и средства для запуска кода и проверки результатов. Этот модульный подход обеспечивает гибкость и расширяемость, позволяя DeepCode адаптироваться к различным требованиям задач по воспроизведению кода и использовать новые инструменты по мере их появления.
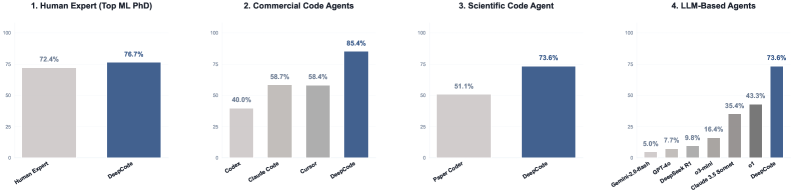
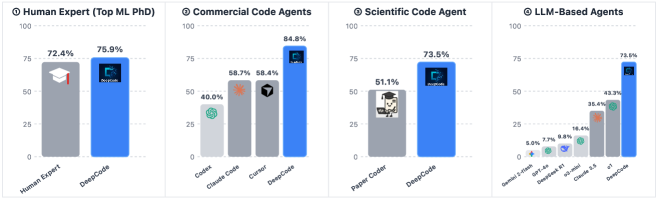
В отличие от простых систем генерации кода, DeepCode стремится к созданию полноценных, самодостаточных репозиториев, включающих все необходимые зависимости и наборы тестов. На бенчмарке PaperBench DeepCode достиг показателя воспроизводимости в 75.9%, что демонстрирует новый уровень производительности в области высокоточной программы синтеза, основанной на документах. Это указывает на способность системы не просто генерировать фрагменты кода, а воссоздавать полные, функциональные проекты, готовые к использованию и тестированию.
Оптимизация Потока Информации для Надежного Синтеза Кода
В основе подхода DeepCode к синтезу кода лежит управление потоком информации (Information-Flow Management), которое обеспечивает структурированную передачу данных на всех этапах процесса. Это включает в себя не только определение источников и получателей информации, но и оптимизацию путей её прохождения, а также фильтрацию избыточных или нерелевантных данных. Применение принципов управления потоком информации позволяет снизить вероятность ошибок и повысить надежность генерируемого кода за счет обеспечения целостности и непротиворечивости передаваемых данных, что критически важно для сохранения спецификаций и обеспечения глобальной структурной согласованности результирующего кода.
Процесс дистилляции чертежей (Blueprint Distillation) в DeepCode предполагает извлечение и структурирование ключевой информации из исходных документов с целью формирования высокосигнального чертежа реализации. Этот процесс включает в себя идентификацию релевантных фрагментов текста, таких как спецификации требований, примеры использования и ключевые алгоритмы, а затем организацию этой информации в формат, пригодный для последующего синтеза кода. Полученный чертеж реализации представляет собой структурированное представление намерения разработчика, которое служит основой для генерации корректного и функционального кода. Структурирование информации включает в себя определение взаимосвязей между различными элементами спецификации, что позволяет DeepCode обеспечить согласованность и точность синтезируемого кода.
В процессе синтеза кода DeepCode использует максимизацию контекстной информации для обеспечения высокого отношения сигнал/шум. Это достигается за счет эффективной фильтрации и приоритизации релевантных данных из исходных документов, что приводит к улучшению сохранения спецификаций, глобальной структурной согласованности и, как следствие, функциональной работоспособности сгенерированного кода. В ходе тестирования на бенчмарке PaperBench DeepCode показал результат 73.5 ± 2.8, превзойдя как ведущие коммерческие решения, так и результаты, полученные экспертами-людьми (72.4), что подтверждает эффективность данного подхода к управлению информационными потоками.
Агентское Каркасирование и Память Кода для Воспроизводимости: За гранью простого копирования
В основе функционирования DeepCode лежит концепция “Памяти Кода” — структурированного представления репозитория, обеспечивающего последовательность и управление зависимостями на протяжении всего процесса воспроизведения. Данный подход позволяет системе не просто копировать код, но и понимать его структуру, взаимосвязи между различными компонентами и внешние зависимости. Благодаря этому, DeepCode способна эффективно обрабатывать сложные проекты, корректно разрешать конфликты версий и гарантировать, что воспроизведенный код будет соответствовать оригинальному, даже при наличии изменений в исходном репозитории. “Память Кода” служит своего рода цифровым двойником проекта, позволяя системе оперативно восстанавливать необходимую информацию и избегать ошибок, связанных с неполным или устаревшим кодом.
В основе системы DeepCode лежит подход к построению агентов, использующий так называемый “IterativeAgent”. В отличие от более простых агентов, таких как “BasicAgent”, которые стремятся к быстрому решению, “IterativeAgent” делает акцент на постепенном, итеративном прогрессе. Такой подход позволяет агенту эффективно использовать доступное время, последовательно улучшая результаты и находя более точные решения. Вместо того, чтобы сразу выдавать ответ, агент разбивает задачу на подзадачи, решает их последовательно и использует полученные результаты для дальнейшей оптимизации. Это позволяет добиться большей надежности и точности воспроизведения сложных алгоритмов, особенно в контексте машинного обучения, где даже небольшие ошибки могут привести к значительным отклонениям.
Для повышения точности и полноты генерируемого кода, система DeepCode использует технологию CodeRAG. Этот подход предполагает интеграцию релевантных внешних знаний в процесс создания кода, что позволяет учитывать последние исследования, лучшие практики и специфические требования конкретной задачи. Вместо того, чтобы полагаться исключительно на внутренние данные, CodeRAG динамически извлекает и использует информацию из внешних источников, таких как документация, статьи и репозитории кода, что существенно снижает вероятность ошибок и повышает надежность результатов. Такое обогащение знаний обеспечивает более контекстуально-осведомленное и адекватное генерирование кода, что особенно важно при воспроизведении сложных научных работ и алгоритмов.
Применение разработанных стратегий, включающих структурированное хранение кода и использование итеративных агентов, значительно повысило способность к воспроизведению сложных научных работ в области машинного обучения, подтверждая эффективность фреймворка DeepCode. В ходе тестирования на подмножестве из пяти статей, DeepCode достиг показателя воспроизводимости в 0.8482, что на более чем 0.26 превышает результаты, демонстрируемые другими системами. Полученные данные свидетельствуют о существенном улучшении надежности и точности воспроизведения научных экспериментов, что особенно важно для обеспечения прозрачности и верификации результатов в области машинного обучения.
Исследование демонстрирует, что оптимизация потока информации и управление контекстом в больших языковых моделях значительно повышают эффективность воспроизведения научного кода. Подобный подход позволяет не просто синтезировать код, но и понимать его структуру, что особенно важно для сложных научных вычислений. Барбара Лисков однажды заметила: «Хороший дизайн — это проектирование системы с учетом её эволюции». Эта мысль находит отражение в DeepCode, где акцент делается на создании гибкой и адаптируемой системы, способной к воспроизведению и расширению научного знания, а не на простом выполнении заданной задачи. DeepCode, по сути, демонстрирует, что понимание и управление сложностью системы — ключ к её успешному развитию и воспроизводимости.
Куда дальше?
Представленная работа, оптимизируя потоки информации и управление контекстом в больших языковых моделях, демонстрирует впечатляющую способность к воспроизведению научного кода. Однако, каждый эксплойт начинается с вопроса, а не с намерения. Вопрос в том, насколько эта «воспроизводимость» действительно является пониманием. Модель умело манипулирует символами, но способна ли она к истинному научному мышлению, к выявлению лежащих в основе принципов? Этот аспект остается открытым.
Очевидным направлением для дальнейших исследований представляется выход за рамки простого воспроизведения. Необходимо исследовать возможность использования подобных агентов для генерации новых научных гипотез, для автоматического проектирования экспериментов, для поиска ошибок в существующих алгоритмах. Ограничением, как и всегда, является размер контекстного окна — по сути, размер «памяти» агента. Решение этой проблемы, вероятно, потребует не только технических ухищрений, но и принципиально новых подходов к архитектуре моделей.
В конечном итоге, успех подобных систем будет определяться не столько их способностью к кодированию, сколько их способностью к декодированию — к пониманию смысла, к выявлению скрытых взаимосвязей, к взлому системы познания. Иначе говоря, к реверс-инжинирингу реальности.
Оригинал статьи: https://arxiv.org/pdf/2512.07921.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-10 07:53